XiaoMi-AI文件搜索系统
World File Search System训练模型

基于深度神经网络的计算机断层扫描检测脑肿瘤
摘要:脑肿瘤是最致命的疾病之一,对人类健康有许多影响。脑肿瘤是脑内或脑周围的异常细胞团或生长。它们并非都是癌症,因为它们可能是良性的或恶性的。医生使用各种诊断技术来评估良性或恶性脑肿瘤的存在,以及估计其大小、位置和生长速度。使用适当的诊断方式来提供完整的大脑视图以检测任何异常。应对脑部进行计算机断层扫描 (CT) 扫描以检查异常。CT 扫描的好处包括准确检测钙化、出血和骨骼细节,以及与磁共振成像 (MRI) 相比成本低。因此,我们研究了一种基于 CT 的检测方法,以确定是否存在脑肿瘤。所提出的方法适用于从曼苏拉大学医院收集的 CT 图像数据集。使用不同的预训练模型:VGG-16、ResNet-50 和 MobileNet-V2。对比结果,预训练模型 MobileNet-V2 尽管参数数量最少,但结果却更好。它的准确率为 97.6%,而其精确度、召回率和 F1 分数分别为 96%、95% 和 96%。
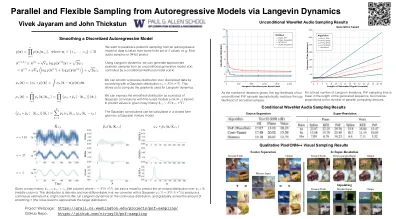
通过Langevin Dynamics
给出了一个嘈杂的历史记录(左列),在其中,我们训练模型以预测(中间列)的未透明分布。此分布是离散的且不差异的;我们与高斯人进行卷积,以产生(右柱)的连续估计。我们在连续分布上运行langevin动力学,并逐渐退化平滑量(噪声水平)以近似目标分布。

人工智能工程设计 Giorgi Tskhondia
工程设计自动化可以表述为马尔可夫决策过程 (MDP)。工程师提供结构的初始几何形状,设置负载并允许改变几何形状的操作,指定优化目标(例如最小化重量、最大化刚度),然后开始训练模型。训练结束后,在推理阶段,工程师得到最终设计。生成式人工智能的最新发展可以增强这一过程。

LayoutLMv3:使用统一的文本和图像蒙版对文档 AI 进行预训练
自监督预训练技术在 Document AI 中取得了显著进展。大多数多模态预训练模型使用掩码语言建模目标来学习文本模态的双向表示,但它们在图像模态的预训练目标上有所不同。这种差异增加了多模态表示学习的难度。在本文中,我们提出了 LayoutLMv3,以统一的文本和图像掩码来预训练用于 Document AI 的多模态 Transformer。此外,LayoutLMv3 还使用词块对齐目标进行预训练,通过预测文本词的相应图像块是否被掩码来学习跨模态对齐。简单的统一架构和训练目标使 LayoutLMv3 成为以文本为中心和以图像为中心的 Document AI 任务的通用预训练模型。实验结果表明,LayoutLMv3 不仅在以文本为中心的任务(包括表单理解、收据理解和文档视觉问答)中取得了最佳性能,而且在以图像为中心的任务(例如文档图像分类和文档布局分析)中也取得了最佳性能。代码和模型可在 https://aka.ms/layoutlmv3 上公开获取。

通过势能视角探索模型的可转移性
由于预训练的深度学习模型大量可用,迁移学习在计算机视觉任务中变得至关重要。然而,从多样化的模型池中为特定的下游任务选择最佳的预训练模型仍然是一个挑战。现有的衡量预训练模型可迁移性的方法依赖于编码静态特征和任务标签之间的统计相关性,但它们忽略了微调过程中底层表示动态的影响,导致结果不可靠,尤其是对于自监督模型。在本文中,我们提出了一种名为 PED 的富有洞察力的物理启发方法来应对这些挑战。我们从势能的视角重新定义模型选择的挑战,并直接模拟影响微调动态的相互作用力。通过捕捉动态表示的运动来降低力驱动物理模型中的势能,我们可以获得增强的、更稳定的观察结果来估计可迁移性。在 10 个下游任务和 12 个自监督模型上的实验结果表明,我们的方法可以无缝集成到现有的排名技术中并提高其性能,揭示了其对模型选择任务的有效性以及理解迁移学习机制的潜力。代码可在 https://github.com/lixiaotong97/PED 上找到。

基于流的神经网络潜在状态生成模型...
我们针对两种主要的神经变异源提出了一种联合深度神经系统识别模型:刺激驱动和刺激条件波动。为此,我们结合了 (1) 最先进的刺激驱动活动深度网络和 (2) 灵活的、基于正则化流的生成模型来捕捉刺激条件变异,包括噪声相关性。这使我们能够端到端地训练模型,而无需与许多刺激条件波动的潜在状态模型相关的复杂概率近似。我们根据来自小鼠视觉皮层多个区域的数千个神经元对自然图像的反应来训练模型。我们表明,我们的模型在预测神经群体对新刺激(包括共享的刺激条件变异性)的反应分布方面优于以前的最先进模型。此外,它成功地学习了与瞳孔扩张等行为变量相关的群体反应的已知潜在因素,以及随大脑区域或视网膜位置系统变化的其他因素。总体而言,我们的模型准确地解释了神经变异的两个关键来源,同时避免了许多现有潜在状态模型相关的若干复杂性。因此,它提供了一种有用的工具,用于揭示导致神经活动变异的不同因素之间的相互作用。

利用生成式人工智能丰富数字助理体验
生成式 AI 助手取决于训练模型中使用的基础数据的质量和数量。组织应准备其数据、文档、内容以及类似的背景和材料作为学习基础,以增强开源 AI 模型。这些跨环境(本地或边缘)的定制数据集使数字助理能够形成直观的理解,从而为使用该工具的人提供更相关、更准确的帮助。

基于人工智能的蓄电池系统预测性故障检测
计算重建误差。大多数电池模块老化正常。此外,当正常老化模块中电池单元的运行数据与训练模型时使用的运行数据性质相同时,计算出的重建误差较小。然而,当电池模块中电池单元的运行数据与学习 ₂ 期间输入的运行数据性质不同时,计算出的重建误差较大。因此,可以根据重建误差的大小提前自动检测可能发生故障的电池模块。

不是 Guilhem
saccha:兽医学生的狗训练模型混合感:在EPFL的2022年轨道游戏JAM果酱期间开发的游戏。海豚:一个玩具分散的账单共享应用程序。CRDT用于管理分布式数据,以及用于组密钥管理和密钥旋转的TreeKem。pingo:GO中的π-Calculus解释器。建模相互追踪应用程序的影响。在法国议会委员会中提出。

汽车工程中与人工智能相关的用例
人工智能技术可分为联结人工智能和符号人工智能 [5]:符号人工智能,如决策树,可由开发人员直接设计和解释,而联结人工智能,如神经网络,则需要一个复杂的生命周期,包括一个训练阶段,其中使用机器学习 (ML) 算法和数据训练模型。ML 可分为监督学习、无监督学习和强化学习。数据质量和数量对于训练模型至关重要。由于数据采集通常需要大量资源并且可能涉及法律问题,因此不同用例的公共数据库是讨论的主题,例如自动驾驶场景数据库、事故数据库等。通常,多种应用程序都可以由人工智能驱动,例如计算机视觉(对象识别、分割、车辆定位、对象跟踪)、序列建模、自动规划(基于图、深度强化学习)。在汽车领域,人工智能主要用于感知方面,即处理传感器信息(例如场景理解、场景流估计、场景表示),但也用于规划(例如路线规划、行为规划、运动/轨迹规划)和执行器控制。人工智能可用于自动驾驶功能以及信息娱乐、车内监控和人机交互。除了使用人工智能技术带来的机遇之外,它的使用还意味着新的漏洞 [5],包括训练期间的投毒攻击、推理阶段的对抗性攻击和隐私攻击。