XiaoMi-AI文件搜索系统
World File Search System语法



问题库 - 第10类
机器进行的通信非常基本和简单。人类交流很复杂。人类语言的多种特征对于人类来说可能很容易理解,但对于计算机来说极其困难。对于机器,很难理解我们的语言。让我们在这里查看其中的一些:单词和含义的安排 - 人类语言中有规则。有名词,动词,副词,形容词。单词一次可以是一个名词,而另一些时间则可以是一个名词。这可能会在计算机处理时会产生困难。类比编程语言 - 不同的语法,相同的语义:2+3 = 3+2这里的书面方式不同,但它们的含义与5。不同的语义,相同的语法:2/3(Python 2.7)≠2/3(Python 3)这里所写的语句具有相同的语法,但其含义不同。在Python 2.7中,该语句将导致1个,而在Python 3中,它的输出为1.5。单词的多种含义 - 在自然语言中,重要的是要了解一个单词可以具有多种含义,并且根据其上下文符合陈述的含义。

痴呆症的语言标记及其在阿尔茨海默氏病早期诊断中的作用:通过句子探索语法和句法能力
塞洛尼基亚里士多德大学,塞萨洛尼基亚里士多德大学英语学院,塞萨洛尼基,塞萨洛尼基,塞萨洛尼基大学医学院,塞萨洛尼基大学,塞萨洛尼基大学,塞萨洛尼基,塞萨洛尼基,塞萨洛尼基,塞萨洛尼基,希腊阿尔茨阿尔茨阿尔兹·阿尔茨·阿尔兹·阿尔兹·艾尔兹·迪克(Greece)的泰士(Grecect)塞萨洛尼基的技术赫拉斯,希腊语言学系,语言学系,亚里士多德大学塞萨洛尼基大学哲学学院塞萨洛尼基(Thessaloniki),塞萨洛尼基(Thessaloniki),希腊h神经退行性疾病实验室,跨学科研究与创新中心(CIRI - AUTH),巴尔干中心,塞萨洛尼基亚里士多德大学,塞萨洛尼基,塞萨洛尼基,格里西基,格里西基,塞洛尼基亚里士多德大学,塞萨洛尼基亚里士多德大学英语学院,塞萨洛尼基,塞萨洛尼基,塞萨洛尼基大学医学院,塞萨洛尼基大学,塞萨洛尼基大学,塞萨洛尼基,塞萨洛尼基,塞萨洛尼基,塞萨洛尼基,希腊阿尔茨阿尔茨阿尔兹·阿尔茨·阿尔兹·阿尔兹·艾尔兹·迪克(Greece)的泰士(Grecect)塞萨洛尼基的技术赫拉斯,希腊语言学系,语言学系,亚里士多德大学塞萨洛尼基大学哲学学院塞萨洛尼基(Thessaloniki),塞萨洛尼基(Thessaloniki),希腊h神经退行性疾病实验室,跨学科研究与创新中心(CIRI - AUTH),巴尔干中心,塞萨洛尼基亚里士多德大学,塞萨洛尼基,塞萨洛尼基,格里西基,格里西基,

访谈:太空问答 - Eric Perlade,技术......
Ada 可读性强,语法清晰,能够传达程序意图并避免陷阱和缺陷,并且具有其他语言未指定的运行时行为的明确语义。Ada 支持模块化软件架构,其软件包功能将规范与实现分开。对于必须禁用某些 Ada 检查的低级编程,语言功能具有明确的语法(“未检查”前缀),使人类读者能够清楚地了解它们的用法。所有这些使得 Ada 成为需要维护多年项目时的绝佳选择。
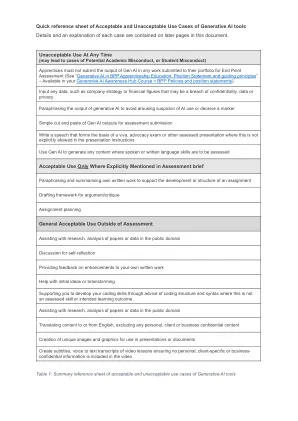
生成AI工具的可接受和不可接受用例的快速参考表
“您将充当编码Excel函数和语法的专家。您将为我提供有关我发布给您的问题的解决方案。您将更正或改编我提供给您的代码。我将以这种方式参考列和行[[列],[[row]]。您将使用“代码片段”提供任何编码更正或建议,然后我可以将其切割并粘贴到Excel中。如果您不知道,您将不会尝试猜测功能或代码。,如果您不确定正确的函数语法,您会清楚地说“我不知道”或“这是可能有效的建议”。

人工智能正在彻底改变出版业......
判别式人工智能(大多数在线工具,例如 Grammarly)是经过训练以区分类别(例如语法正确或不正确)的模型。另一方面,GenAI 经过训练能够生成新内容(文本、音频或视觉内容)。由于这一更高级的功能,它不仅可用于检查语法,而且还可以帮助处理结构和内容。人们经常错误地认为 ChatGPT 和 Grammarly 是相同的。它们不是,它们是具有显着差异的不同工具。最受欢迎的 GenAI 模型是 OpenAI 的 Cha-tGPT(https://chatgpt.com/ 或免费版本 https://chatgpt.com/)、Google 的 Gemini(https://gemini.google.com)和 Anthropic 的 Claude(https://www.an-thropic.com/claude)

高级英语1(AE1)
a。在给定的段落中使用适当的词汇项填充空白b。确定语音的一部分c。为词汇项目d编写正确的定义。使用词汇项目e创建句子。大声说话或读取f时正确发音词汇项。在他们的写作中适当地包括词汇项2。为提示3.使用狂热者以书面形式产生语法上正确的复合句子。以书面形式表现出流利和表达5。书面材料中的解释想法6。通过指导编辑听力和说话来加强AE1语法目标:


用法中的语言获取和语言教学 -
在生成的传统中,童年和青春期后的语言获取被视为两个根本不同的过程。获得了第一(L1)或第二(L2)语言的孩子可以使用通用语法(UG)。从获取率和最终达成方面,他们获得的语言的便捷性是由年轻学习者只需要输入来基于他们听到的输入来设置参数的事实来解释的,并且语法已经通过先天的语言获取设备可以使用,其余的语法已经可以使用(Chomsky 1975,1985,1988; Pinker 1989; Pinker 1989; Pinker; Pinker; Pinker; Pinker; Pinker; Pinker;相比之下,据称通心后学习者不能访问UG,或者仅是部分或间接访问(通过L1),这是对较慢的获取率和整体非本地结果的解释。例如,一种生成观点认为,puberty后的L2ER无法获得其L1中无法使用的功能功能(Hawkins and Chan 1997)。我们认为,生成账户的一个主要问题是,UG的存在是无法伪造的:不可能研究人类的大脑,希望找到一种语言获取设备。但是,可以从经验上做的事情是在不提出先天语法的情况下从输入中获取语言是可能的。这正是在基于用法的范式中工作的语言获取研究人员的启发,这是受Tomasello在领域的开创性工作的启发(Tomasello 1992,2000a,2000b,2003)。这就是为什么基于用法的语言发展研究本质上是定义经验的原因。本卷从两种主要用法的方法的角度来看,在自然主义和指导环境中进行了关于语言获取的最新研究:认知语言学和施工语法。在基于用法的方法中,由于使用了域中的学习机制,例如模式发现,类比,一般性和根深蒂固,可以从输入中获取语言(Tomasello 2003)。输入属性,例如类型和令牌频率,概念复杂性和交流意义,在各种获取中都起着至关重要的作用。因此,无需假设