XiaoMi-AI文件搜索系统
World File Search System读取数据

提高环境中 UHF RFID 标签读取率的创新解决方案
1.1 RFID 的历史 ................................................................................................................ 1 1.2 电子识别和 RFID .................................................................................................. 4 1.3 RFID 市场 ................................................................................................................ 6 1.4 频段和法规 ........................................................................................................ 7 1.5 电感耦合和辐射耦合 ................................................................................................ 8 1.6 应用领域 ............................................................................................................. 10 1.7 论文问题 ............................................................................................................. 14 1.8 第 1 章参考文献 ............................................................................................. 17
提高环境中 UHF RFID 标签读取率的创新解决方案
1.1 RFID 的历史 ................................................................................................................ 1 1.2 电子识别和 RFID .................................................................................................. 4 1.3 RFID 市场 ................................................................................................................ 6 1.4 频段和法规 ........................................................................................................ 7 1.5 电感耦合和辐射耦合 ................................................................................................ 8 1.6 应用领域 ............................................................................................................. 10 1.7 论文问题 ............................................................................................................. 14 1.8 第 1 章参考文献 ............................................................................................. 17

一种基于敏感压缩的方法,用于过滤靶向的FASTQ测序读取
摘要 - BioInformatics应用程序通常需要根据其与特定序列目标的相似性过滤FastQ测序读取,例如消除与特定病毒相关的污染或隔离读取。尽管基于对齐的方法对这些任务有效,但它们表现出降低的灵敏度并可能引入高估,尤其是在面对较低的相似性搜索时。在本文中,我们使用一种新颖的无对齐方法来过滤FASTQ根据定义的相似性阈值读取。与基于对齐方式的方法不同,即使在相似性较低的方案中,例如在古代DNA中,我们的方法也保持较高的灵敏度。此外,我们的方法是基于压缩的,可以减轻其他方法固有的高估风险。我们在各种应用程序中演示了我们方法的多功能性,并提供了一种称为磁铁的公共开源物。磁铁提供了用于加速处理的多线程功能,并且可以在https://github.com/cobilab/magnet上自由访问。索引项 - 数据压缩,生物信息学,计算生物学,测序读取,数据滤波器

数据作为经济利益,作为共享的数据和数据治理
1这是欧盟立法的不完整清单,与数据治理相关:欧洲议会的2016/679法规(EU)和2016年4月27日的2016年4月27日的理事会,涉及对自然人的保护在处理个人数据以及此类数据的自由竞争以及95/46/EC的自由数据方面的保护(一般数据)。 1-88;欧洲议会和2019年6月5日理事会的2019/944指令(EU)2012年6月5日的《电力和修订指令》 2012/27/eu oj l 158,14.6.6.6.2019,p。 125–199;欧洲议会和2019年6月20日理事会的2019/1024指令(欧盟)关于开放数据和重新使用公共部门信息OJ L 172,26.6.2019,p。 56–83;欧洲议会和2022年5月30日理事会的第2022/868号法规(EU)关于欧洲数据治理和修订法规(EU)2018/1724(数据治理法)OJ L 152,3 .6.2022,p。 1-44岁于2022年6月23日生效,将于2023年9月适用;欧洲议会和2022年10月19日理事会的第2022/2065号法规(EU)在数字服务和修订指令2000/31/EC(数字服务法)的单一市场上(数字服务法) 1-102,从2024年1月起生效;欧洲议会和2022年9月14日理事会的法规(EU)2022/1925关于数字领域的可竞争和公平市场2019/1937和(EU)2020/1828(数字市场)OJ L 265,12.10.10.2022,p。 1-66,实际上是2023年6月;在撰写本文时,理事会已经采用了有关《人工智能法》数据法的一般方法

线性扩增子测序分析报告/结果
下面的直方图显示了测序数据的读取长度分布。直方图在 y 轴上显示测序碱基数 (bp),在 x 轴上显示读取长度。直方图中的每个条形代表读取长度的范围,条形的高度表示该范围内的碱基总数 (bp)。这会产生按每个箱体的核苷酸数加权的图,因为较长的读取在直方图中具有更大的权重。读取长度直方图可用于评估测序数据的质量,因为读取长度的分布可以指示测序过程中是否存在污染物或偏差。它们还可用于确定正在测序的扩增子的大小。

面向线状柔性物体的机器人操作研究进展与展望
此类任务同样可以先离线学习状态转移预测模 型再使用 MPC 计算控制输入 [28-29] ,或直接使用强 化学习方法 [68-69] ,但需要大量训练数据且泛化性较 差。在准静态的局部形变控制中,更常用的方法是 在线估计局部线性模型。该模型假设线状柔性体形 状变化速度与机器人末端运动速度在局部由一个雅 可比矩阵 JJJ 线性地联系起来,即 ˙ xxx ( t ) = JJJ ( t ) ˙ rrr ( t ) ,其 中 ˙ xxx 为柔性体形变速度, ˙ rrr 为机器人末端运动速度。 由于使用高频率的闭环反馈来补偿模型误差,因此 完成任务不需要非常精确的雅可比矩阵。 Berenson 等 [70-71] 提出了刚度衰减( diminishing rigidity )的概 念,即离抓取点越远的位置与抓取点之间呈现越弱 的刚性关系,并据此给出了雅可比矩阵的近似数学 表示。此外,常用的方法是根据实时操作数据在线 估计雅可比矩阵,即基于少量实际操作中实时收集 的局部运动数据 ˙ xxx 和 ˙ rrr ,使用 Broyden 更新规则 [72] 、 梯度下降法 [73] 、(加权)最小二乘法 [33-34,74] 或卡尔 曼滤波 [75] 等方法在线地对雅可比矩阵进行估计。 该模型的线性形式给在线估计提供了便利。然而, 雅可比矩阵的值与柔性体形状相关,因此在操作 过程中具有时变性,这使得在线更新结果具有滞 后性,即利用过往数据更新雅可比矩阵后,柔性体 已经移动至新的形状,而新形状对应的雅可比矩阵 与过往数据可能并不一致。同时,完整估计雅可比 矩阵的全部元素需要机器人在所有自由度上的运 动数据,这在实际操作过程中难以实现,为此一些 工作提出根据数据的奇异值进行选择性更新或加 权更新 [74] 。此外,此类方法需要雅可比矩阵的初 值,一般在操作前控制机器人沿所有自由度依次运 动,收集数据估计初始位置的雅可比矩阵。受上述 问题影响,在线估计方法往往仅适用于局部小形变 的定点控制,难以用于长距离大形变的轨迹跟踪。 Yu 等 [31] 提出 ˙ xxx = JJJ ( xxx , rrr ) ˙ rrr 的模型形式,其中 JJJ ( · ) 为 当前状态至雅可比矩阵的非线性映射,待估计参数 为时不变形式。基于该模型,该方法将离线学习与 在线更新无缝结合,实现了稳定、平滑的大变形控 制。 Yang 等 [76-77] 使用模态分析方法建立柔性体模

从头读数,使用长读和简短的抛光
您将组装来自锯齿状铜菌菌株Cav1492的分离株。该菌株具有一个染色体和五个质粒。测序数据包含7,038个小小的读取,平均读取长度超过12,000 bp,一组Illumina读取了从同一菌株进行测序的读取。Illumina读取已被删除,以降低本教程中的分析时间。数据集中包含的参考基因组是由深层覆盖的PACBIO和配对末端测序数据制成的。可从https://ncbi.nlm.nih.gov/datasets/ genome/gca_001022215.1/。
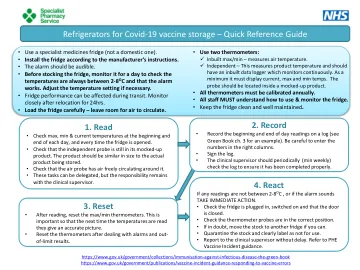
1. 读取 2. 记录 3. 重置 4. 对 Covid 冰箱做出反应...
4. 反应 如果任何读数不在 2-8 OC 之间,或者警报响起,请立即采取行动。 • 检查冰箱是否插上电源、打开电源并且门是否关闭。 • 检查温度计探头是否处于正确位置。 • 如有疑问,请尽可能将库存移至另一台冰箱。 • 隔离库存并明确标记为不可使用。 • 立即向临床主管报告。请参阅 PHE 疫苗事件指南。

合成数据:从数据稀缺到数据污染合成数据的关键挑衅
培训人工智能(AI)系统需要大量数据,AI开发人员面临访问所需信息的各种障碍。合成数据已将研究人员和行业的想象力作为解决这个问题的潜在解决方案。虽然可能需要对合成数据的某些热情,但在这篇简短的论文中,我们为简单叙事提供了至关重要的配重,这些叙述将合成数据定位为对每个数据访问挑战的一种无需成本的解决方案,突显了伦理,政治,政治和治理性,可以创建合成数据的使用。我们质疑合成数据本质上可以免于隐私和相关的道德问题的想法。我们警告说,将二元反对的构架数据构架对“真实”测量数据可能会巧妙地将数据收集器和处理器持有的规范标准转移。我们认为,通过承诺将数据与其组成部分(其代表和影响的人)离婚,合成数据可能会给民主数据治理带来新的障碍。

数据空间的数据平台
摘要 在我们的社会中,对生产和使用更多数据的需求日益增长。数据正在达到推动每个行业部门的所有社会和经济活动的程度。技术不再是障碍;然而,在技术大规模部署的地方,数据的生产会产生对更好的数据驱动服务日益增长的需求,同时,数据生产的好处在很大程度上推动了全球数据经济的发展,数据已成为企业最有价值的资产。为了充分发挥其价值并帮助数据驱动型组织获得竞争优势,我们需要有效和可靠的生态系统来支持跨境数据流动。为此,数据生态系统是组织内或跨组织数据共享和重用的关键推动因素。数据生态系统需要应对数据管理的各种基本挑战,包括技术和非技术方面(例如法律和道德问题)。本章探讨了大数据价值生态系统,并详细概述了几种数据平台实现,作为共享和交易工业和个人数据的尽力而为的方法。我们还介绍了实现数据平台的几种关键支持技术。本章最后介绍了数据平台项目遇到的常见挑战,并详细介绍了应对这些挑战的最佳实践。