XiaoMi-AI文件搜索系统
World File Search System输入量

全球模型模拟中受背景流调制的近惯性波能量
摘要:我们利用 2019 年 5 月至 6 月 30 天内具有真实大气强迫和背景环流的全球 1/25 8 混合坐标海洋模型 (HYCOM) 模拟研究了风致近惯性波 (NIW) 的产生、传播和消散。计算了总场的时间平均近惯性风能输入和深度积分能量平衡项,并将场分解为垂直模式以区分 NIW 能量的辐射和(局部)耗散分量。只有 30.3% 的近惯性风输入投射到前五个模式上,而前五个模式中的 NIW 能量之和占总 NIW 能量的 58%。几乎所有深度积分的 NIW 水平能量通量都投射到前五种模式上。NIW 模式的耗散和衰减距离的全球分布证实,低纬度是高纬度产生的 NIW 能量的汇聚点。发现 NIW 能量的局部耗散部分 q 局部 在整个全球海洋中是均匀的,全球平均值为 0.79。水平 NIW 通量从具有气旋涡度的区域发散,并汇聚在具有反气旋涡度的区域;也就是说,反气旋涡流是 NIW 能量通量的汇聚点 (特别是对于较高模式而言)。大多数未投射到模式上的残余能量在反气旋涡流中向下传播。全球近惯性风能输入量在30天内为0.21TW,其中只有19%传输到500米深度以下。

有关光力量子传送的建议
量子传送的过程描述了未知输入状态到远程量子系统的传递。Bennett等人首先概述。[1],它已经演变成一个活跃的研究领域,现在被认为是许多量子方案的重要工具,例如量子中继器[2],基于测量的量子计算[3]和耐受性量子计算[4]。实验是第一个使用光子[5]实现的,后来又使用了各种系统,例如捕获的离子[6,7],原子集合[8],以及高频声音[9]和其他几个[10]。Over the past few years, optomechanical devices have emerged as an interesting tool to explore quantum phenomena, both from a fundamental perspective, showing the limits of quantum mechanical rules on massive objects [ 11 ], as well as from an applied view, promising to act as efficient transducers connecting radio-frequency regime qubits to low-loss opti- cal channels [ 12 , 13 ].已经提出了使用光力学系统的连续变量传送[14,15],但这种方案的实验实现仍然无法实现。在这里,我们提出了一项协议,该方案将实现基于脉冲制度中的分离变量的固定机械量子存储器上未知的光学输入状态的量子传送。该方案基于双轨编码,其中光子输入量子置值的极化状态被传送到两个机械模式上。当前最新的光学机械设备[16]应该能够实现所提出的协议。光学机械相互作用用作爱因斯坦 - 波多尔斯基 - 罗森河(EPR) - 型纠缠之间的源头,并在此范围内进行了验证,然后成功完成了输入量的成功铃声测量。可以按需读取磁场状态回到光学

在中风康复中使用运动想象脑机接口的虚构输入来调节挫折感和能动性
摘要 脑机接口 (BCI) 可作为中风康复的一种手段,但较低的 BCI 性能会降低自主性 (用户的感知控制),使用户感到沮丧,从而妨碍康复。在这些康复任务中,BCI 可以实现虚构的输入 (预先编程的正反馈),从而改善自主性并减少沮丧。两项针对健康受试者和中风患者的子研究通过完成游戏和简单任务调查了这种潜力:1) 16 名健康受试者使用基于运动想象的在线 BCI;2) 13 名中风患者使用基于通过眼动仪进行眨眼检测的替代 BCI 系统来获得高度可靠的输入信号。子研究 1 在四种条件下测量了感知控制和沮丧:1) 不变的 BCI 控制,2) 30% 保证来自虚构输入的正反馈 3) 50% 保证的负反馈,和 4) 50% 保证的负反馈和 30% 保证的正反馈。在子研究 2 中,中风患者对结果的控制率为 50%,四种情况增加了从 0% 到 50% 的正反馈。在两项子研究中,正反馈提高了参与者的感知控制力并减少了挫败感,并且随着正向虚构输入量的增加,改善程度也随之增加。中风患者对虚构输入的反应不如健康参与者那么强烈。虚构输入可以隐藏在在线和代理 BCI 中,可用于改善基于游戏的交互和简单任务中的感知控制力和挫败感。这表明 BCI 设计师可以发挥艺术自由,创造引人入胜的基于运动意象的叙事游戏交互或更简单的游戏化交互,以促进改进培训工作。

用子...
昆虫学采样和存储条件通常会优先考虑效率,实用性和形态特征的保守性,因此可能是DNA保存的次优。这种做法可能会影响下游分子应用,例如高通量基因组文库的结构,这通常需要大量的DNA输入量。在这里,我们使用了实用的TN5转座酶标记的基于基于96孔板的库制备方法,并从昆虫腿的低屈服DNA提取物中进行了优化,这些昆虫的DNA提取物是在亚最佳条件下存储的DNA保存的。将样品在野外车辆中长时间保存,然后在冰箱中的乙醇中长期存储或在室温下干燥。通过将DNA输入减少到6ng,可以处理更多具有亚最佳DNA产量的样品。我们将这种低DNA输入与市售标记酶的6倍稀释匹配,从而大大降低了库制备成本。通过直接放大后单个图书馆汇集的成本和工作量进一步抑制。我们生成了90个样本中88个中等覆盖范围(> 3倍)基因组,平均覆盖率约为10倍。与储存在乙醇中的样品相比,与储存的样品相比,DNA的DNA明显较少,但这些样品具有较高的测序统计量,其测序读数较长,内源性DNA的速率更高。此外,我们发现基于标记的库制剂的效率可以通过彻底的放大后珠子清理来提高,该珠子可以选择不针对短和大的DNA片段。通过打开使用亚最佳保存的低产量DNA提取物的机会,我们扩大了昆虫标本的整个基因组研究的范围。因此,我们期望这些结果和该协议对于昆虫学领域的一系列应用都有价值。

通过Edge AIbq25620/bq25622 I2C控制的1细胞,3.5a,最大...
•高效率,1.5MHz,单电池电池的同步切换模式 - > 90%的效率 - 从5V输入到25mA输出的电流 - 从10mA到620mA的充电终止,10mA,10mA步骤,灵活的JEITA轮廓 - 弹性JEITA概况,可用于安全•batfet控制•batfet控制•当前型号和全型型号的电量型乘型型号 - 1.5型电池 - 1.5型电池 - 乘飞机 - 乘船乘坐型号。模式 - 0.1μa电池关闭中的电池泄漏电流•支持USB(OTG) - 增强模式支持3.84V至9.6V的输出 - > 90%的增强效率降至100mA OTG的5V VBU•支持多种输入量的范围为3.9V至18V的最大范围26V的范围26V范围26V范围(VINDPM)和输入电流法规(IINDPM) - VINDPM阈值会自动跟踪电池电压•使用15mΩBATFET进行有效的电池操作•狭窄的VDC(NVDC)功率路径管理 - 系统即时启动 - 系统即时启动 - 无需耗尽或无电池的电池 - 当适配器全部载荷时,电池补充•柔性自动•稳定性•稳定的自动级别•i 2 c-contect•i 2 c-contect•i 2 c-contect•i 2 c-contect•i 2 c-contect•i 2 c-contect•i 2 c-contect•i 2 c-contect•电流,温度监测•高准确性 - ±0.5%电荷电压调节 - ±5%电荷电流调节 - ±5%输入电流调节•安全性 - 安全性调节和热关闭 - 输入,系统,系统,电池电压保护 - 电池电量,电池电池,转换器过度保管 - 充电安全计时•安全计时•安全相关的认证: - IEC 6238-1 CB CBB CERTIFIFIAN: - IEC 62368-1 CB CB BB
在小量子计算机上的地球观测图像的组装
摘要 - 卫星仪器的白天和黑夜监视地球的地面,结果,地球观测(EO)数据的大小大大增加。机器学习/深度学习(ML/DL)技术通常用于分析并处理这些大EO数据,而一种众所周知的ML技术是支持向量机(SVM)。SVM提出了二次编程问题,包括量子退火器(QA)以及基于门的量子计算机(包括量子计算机)有望比惯性计算机更有效地解决SVM;通过使用量子计算机/常规计算机来培训SVM,代表量子SVM(QSVM)/经典SVM(CSVM)应用程序。但是,量子计算机无法通过使用QSVM来解决许多实用的EO问题,因为它们的输入量很少。因此,我们组装了给定的EO数据的核心(“数据集的核心”),用于在小量子计算机上训练加权SVM。核心是原始数据集的一个小的,代表性的加权子集,与原始数据集相比,可以通过在小量子计算机上使用建议的加权SVM来分析其性能。作为实际数据,我们使用合成数据,虹膜数据,印度松树的高光谱图像(HSI)以及旧金山的偏光仪合成孔径雷达(Polsar)图像。我们通过使用Kullback-Leibler(KL)Divergence测试来测量原始数据集及其核心之间的接近性,此外,我们通过使用D-Wave量子量子退火器(D-Wave QA)和一台常规计算机在我们的核心数据上训练了加权SVM。我们的发现表明,核心具有很小的kl差异近似于原始数据集,而加权QSVM甚至在我们的一些实验实例上都超过了核心上的加权CSVM。作为一个侧面结果(或副产品结果),我们还提出了我们的KL差异发现,以证明我们的原始数据(即我们的合成数据,虹膜数据,高光谱图像和Polsar图像)和组装的壳体之间的亲密关系。

人脑中情感的依赖编码
摘要:卫星仪器昼夜监测地球的地面,因此,地球观测(EO)数据的大小显着增加。机器学习(ML)技术通常用于分析和处理这些大EO数据,而一种众所周知的ML技术是支持向量机(SVM)。SVM构成了二次编程问题,量子计算机(包括量子退火器(QA))以及基于门的量子计算机有望比常规计算机更有效地求解SVM;通过使用量子计算机/常规计算机来培训SVM,代表量子SVM(QSVM)/经典SVM(CSVM)应用程序。但是,量子计算机无法通过使用QSVM来解决许多实用的EO问题,因为它们的输入量很少。因此,我们组装了一个给定的EO数据的核心(“数据集的核心”),用于在小量子计算机上训练加权SVM,这是一个大约5000个输入量子位的D-Wave量子式退火器。核心是原始数据集的一个小的,代表性的加权子集,与原始数据集相比,可以通过在小量子计算机上使用建议的加权SVM来分析其性能。作为实际数据,我们使用合成数据,虹膜数据,印度松树的高光谱图像(HSI)以及旧金山的偏光仪合成孔径雷达(Polsar)图像。我们通过使用Kullback-Leibler(KL)散射测试来测量原始数据集及其核心之间的接近度,此外,我们还通过使用D-Wave量子量子Quantum Nealealer(D-Wave QA)和一台传统计算机在我们的核心数据上训练了加权SVM。我们的发现表明,核心具有很小的kl差异(较小的较小)近似于原始数据集,而加权QSVM甚至在我们的一些实验实例上都超过了核心上的加权CSVM。作为一个侧面结果(或副产品结果),我们还提出了我们的KL差异发现,以证明我们的原始数据(即我们的合成数据,虹膜数据,高光谱图像和Polsar图像)和组装的壳体之间的亲密关系。

通过电流零模式波导直接测序对DNA片段的快速识别
在单分子,实时(SMRT)测序中,通过单个DNA聚体在DNA链复制过程中实时监测单个核苷酸,跟踪掺入multicolor荧光标记的核苷酸。[3A]通过扩散过程将要测序的DNA模板加载到100 nm直径的纳米线的底部,称为零模式波导(ZMW),这自然有利于捕获由于井的大小约束而捕获较短的DNA分子。[3b,4]为了从长片段中获取读数,使用尺寸选择系统,其中短片段通过凝胶电泳去除。[5]总体而言,在SMRT测序方案中需要高输入DNA量(> 3 µg每1 GB基因组),[5,6],尽管可提供来自亚纳米图DNA的库制备方法[7] [7]来自低输入的这种低输入量的DNA负载限制可有效读取来自低输入的有效读数。需要新平台有效地将各种尺寸的DNA碎片加载到没有长度偏差的ZMW中,并且从超值输入(PICOGRAMPOMPOM级别)导致了几种类型的电气致命ZMW的发展,包括纳米孔ZMWS(NZMWS)(NZMWS)[8]和POOL ZMWS(POOL ZMWS)(POROUL ZMWS(POLOUL ZMWS))(POROUL ZMWS)(POLFOOL ZMWS)。[9]在这些设备中,跨设备的电压应用导致离子流过ZMWS的多孔碱基,从而导致电动介导的生物分子(DNA,RNA和蛋白质)的电动介导的负载。与基于扩散的负载相反,电力学介导的负载功能低尺寸偏差和亚纳米革兰氏DNA输入要求。在该设备中,波导在其底部嵌入了电极,可以使电压诱导的DNA分子捕获到EZMWS中。但是,这些设备都依赖于独立的超薄膜,这在某种程度上承诺了设备的寿命并增加背景光致发光。为了克服这些问题,我们在这里脱颖而出,电光ZMWS(EZMWS),这是一种新型的电气可致动ZMW的设计,其中不需要独立的membranes。我们的新设备功能
概述.pdf
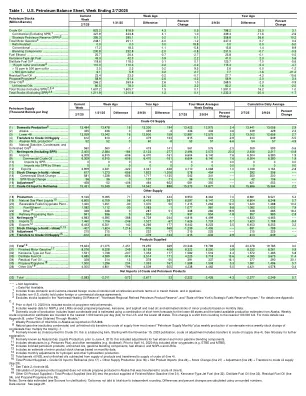
– – = 不适用。– = 数据不可用。1 包括炼油厂和油库或运往油库和管道的国内和海关清关外国原油库存。2 包括根据外国或商业储存协议持有的非美国库存。3 不包括位于“东北取暖油储备”、“东北地区精炼石油产品储备”和“纽约州战略燃料储备计划”中的库存。有关详细信息,请参阅附录 C。4 2020 年 4 月 10 日之前,这包括终端持有的丙烯库存。5 包括 NGPL 和 LRG(丙烷/丙烯除外)、煤油、沥青和道路用油的每周数据;以及基于月度数据的次要产品估计库存。6 国内原油产量包括租赁凝析油,使用美国本土 48 个州的短期预测和阿拉斯加最新的可用产量估计值进行估算。对于美国和美国本土 48 个州,每周原油产量估计值四舍五入到最接近的 1,000 桶/天 (b/d)。此更改是从四舍五入到最接近的 100,000 b/d。有关更多详细信息,请参阅附录 B 中的“通过模型获得的数据”。7 根据 EIA-806 报告,阿拉斯加每周 NGL 总产量。8 最新“石油供应月报”中天然汽油(不包括凝析油)和未加工油转移到原油供应量,加上每周凝析油产量减去每周凝析油库存变化量,然后将总数乘以 -1。9 以前称为未计入原油,这是一个平衡项目。从 2023 年 11 月 15 日的出版物开始,原油调整包括转移到原油供应量(第 4 行)。有关进一步解释,请参阅词汇表。 10 2010 年 6 月 4 日之前称为天然气液产量,包括对燃料乙醇和车用汽油混合成分的调整。11 包括变性剂(例如戊烷加)和其他可再生能源(例如生物柴油)。2020 年 4 月 10 日之前,包括其他含氧化合物(例如 ETBE 和 MTBE)。12 包括成品石油、半成品油、汽油混合成分、燃料乙醇、NGPL 和 LRG。13 包括基于月度数据的次要产品库存变化估计值。14 包括对氢气和其他碳氢化合物产量的月度调整。15 从产品供应中减去并转入原油供应的 NGL 和半成品油总桶数(第 4 行)。 16 总产品供应量 = 炼油厂的原油输入量(第 17 行)+ 其他供应产量(第 18 行)+ 净产品进口量(第 24 行)- 库存变化量(第 27 行)+ 调整量(第 28 行)+ 原油供应转移量(第 29 行)。17 参见表 2,脚注 3。18 丙烷产品供应量的计算不包括阿拉斯加生产的、已转移到原油中的丙烷(第 5 行)。19 其他石油产品供应量 = 总产品供应量(第 30 行)减去成品汽油(第 31 行)、煤油型喷气燃料(第 32 行)、馏分燃料油(第 33 行)、残渣燃料油(第 34 行)和丙烷/丙烯(第 35 行)的供应量。注:部分数据为估算值(请参阅来源以进行澄清)。由于独立四舍五入,数据可能未加总。差异和百分比变化使用未四舍五入的数字计算。数据来源:参见第 29 页。