XiaoMi-AI文件搜索系统
World File Search System错误率

算法分析的错误率
在2021年,澳大利亚政府同意向政府“ RobodeBT”计划的数十万受害者支付18亿美元。政府花了多年的时间在有缺陷的算法的基础上发出了福利欺诈指控(通常是破坏生命)。根据适用的法律,人们有权在每两周的低工资期间获得福利付款;该算法错误地认为薪金支付在更长的时间内均匀分布。参见,例如[65]和[79]有关损坏的简短摘要,以及[92]有关2023年发行的正式验尸。对缺陷算法的典型响应是要求分析算法。例如,[92,建议17.1]说:“应提供算法,以实现独立的专家审查”。O'Neil的2016年书《数学破坏武器》 [85]涵盖了许多决定的决定的例子O'Neil的2016年书《数学破坏武器》 [85]涵盖了许多决定

Ureqa:利用操作感知错误率来……
背景和问题陈述。在量子计算机中,量子比特是基本单位,类似于经典比特。量子比特状态 ( | Ψ ⟩ ) 可以表示为两个基态的叠加:| 0 ⟩ 和 | 1 ⟩ 。更正式地说,| Ψ ⟩ = a | 0 ⟩ + b | 1 ⟩ ,其中 a 和 b 是复数,满足 ∥ a ∥ 2 + ∥ b ∥ 2 = 1。由于量子比特的量子物理行为,在测量时,这种叠加会崩溃,并且量子比特要么处于状态 | 0 ⟩(概率为 ∥ a ∥ 2 ),要么处于状态 | 1 ⟩(概率为 ∥ b ∥ 2 )。可以在计算机上对一组量子比特依次执行多个操作来运行量子算法。在完成量子算法的执行后,测量所有量子比特的量子比特状态并分析输出。量子比特操作称为量子操作,有三种类型:1 量子比特门、2 量子比特门和读出。1 量子比特门对单个量子比特进行操作并改变量子比特的叠加状态。2 量子比特门

生命之树上的转录错误率范围很窄
。CC-BY-NC-ND 4.0 国际许可证永久有效。它以预印本形式提供(未经同行评审认证),作者/资助者已授予 bioRxiv 许可,可以在该版本中显示预印本。版权所有者于 2025 年 1 月 14 日发布了此版本。;https://doi.org/10.1101/2023.05.02.538944 doi:bioRxiv 预印本

稀疏量子码的逻辑错误率 - UDSpace
摘要 量子范式呈现出一种称为退化的现象,这种现象可以潜在地提高量子纠错码的性能。然而,在评估稀疏量子码的性能时,这种机制的影响有时会被忽略,逻辑错误率并不总是能被正确报告。在本文中,我们讨论了以前存在的计算逻辑错误率的方法,并提出了一种受经典编码策略启发的基于陪集的有效方法来估计退化错误并将其与逻辑错误区分开来。此外,我们表明,所提出的方法为 Calderbank-Shor-Steane 码系列提供了计算优势。我们使用这种方法证明,退化错误在特定的稀疏量子码系列中很常见,这强调了准确报告其性能的重要性。我们的结果还表明,文献中提出的改进解码策略是提高稀疏量子码性能的重要工具。

利用设计多样性冗余降低 SoC 模拟数字接口的软错误率
摘要 — 本文在重离子辐照下测试了商用可编程片上系统(PSoC 5,来自赛普拉斯半导体公司),重点测试了系统的模数接口模块。为此,将数据采集系统 (DAS) 编程到被测设备中,并使用设计多样性冗余技术进行保护。该技术通过使用两种不同架构的转换器(一个转换器和两个逐次逼近寄存器 (SAR) 转换器)以不同的采样率运行,实现了不同级别的多样性(架构和时间)。实验在真空室中进行,使用能量为 36 MeV 且足以穿透硅的 16 O 离子束在活性区域产生 5.5 MeV/mg/cm 2 的有效线性能量传输 (LET)。平均通量约为 350 粒子/秒/cm 2,持续 246 分钟。评估了每个转换器对单粒子效应的个体敏感性,以及整个系统截面。结果表明,所提出的技术可有效缓解源自转换器的错误,因为使用分集冗余技术可纠正 100% 的此类错误。结果还表明,系统的处理单元容易挂起,可以使用看门狗技术来缓解。

一种具有错误率保证的高效近似节点合并方法
近似计算是针对容错应用的一种新兴设计范式,例如信号处理和机器学习。在近似计算中,近似电路的面积、延迟或功耗可以通过牺牲其精度来改善。在本文中,我们提出了一种基于节点合并技术并保证错误率的近似逻辑综合方法。我们的方法的思想是用常数值替换内部节点,并合并电路中两个功能相似的节点。我们在一组 IWLS 2005 和 MCNC 基准上进行了实验。实验结果表明,我们的方法最多可以减少面积 80%,平均减少 31%。与最新方法相比,在同样 5% 的错误率约束下,我们的方法加速了 51 倍。
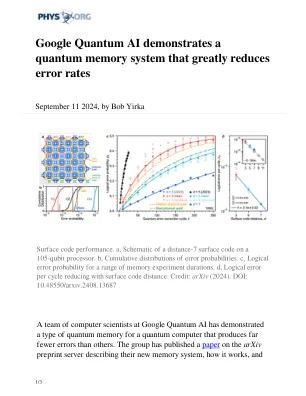
Google Quantum AI 演示量子记忆系统,可大幅降低错误率
在测试中,研究小组还发现,随着逻辑量子比特数量的增加(在他们的案例中从 72 个跃升至 105 个),该算法在纠正错误方面的表现越来越好。研究小组指出,这一发现表明,增加更多的量子比特将进一步提高纠正能力,从理论上讲,这一方案可以开发出一种错误很少、真正有用的量子计算机。

使用基于 SRAM 的软错误率监视器和监督机器学习预测太阳粒子事件
本研究引入了一种嵌入式方法,通过将实时软错误率 (SER) 测量与基于 SRAM 的检测器以及离线训练的机器学习模型相结合,用于预测太空应用中的太阳粒子事件 (SPE)。所提出的方法适用于太空应用中使用的自适应容错多处理系统。相对于最先进的技术,我们的解决方案可以提前 1 小时预测 SER,并在 SPE 期间以及正常条件下以小时为单位细粒度跟踪 SER 变化。因此,目标系统可以在高辐射水平出现之前激活适当的辐射硬化机制。基于对使用公共空间通量数据库训练的五种不同机器学习算法的比较,初步结果表明,使用具有长短期记忆 (LSTM) 的循环神经网络 (RNN) 可实现最佳预测精度。

评估在多核和众核处理器中实现的应用程序的 SEE 灵敏度和错误率预测方法
部长法令:2016 年 5 月 25 日 由 PABLO FRANCISCO RAMOS VARGAS 提交论文由 TIMA 实验室研究主任 Raoul VELAZCO 指导,格勒诺布尔阿尔卑斯大学讲师 Nacer-Eddine ZERGAINOH 联合指导,在 IT 技术实验室内编写和微电子学的集成系统架构电子、电工、自动、信号处理博士生学院 (EEATS) 对 SEE 敏感度的评估以及预测多核和众核处理器中实施的应用程序错误率的方法 2017 年 4 月 18 日公开答辩论文,在评审团组成:

Consensify:一种从古基因组数据集生成伪单倍体基因组序列并降低错误率的方法
摘要:古基因组分析的标准做法是将映射的短读数据转换为伪单倍体序列,通常是从映射读堆栈中随机选择一个高质量的核苷酸。这可以控制由于差异测序覆盖率而导致的偏差,但不能控制差异率和测序错误类型,这些错误在从古代样本获得的数据集中通常很大且多变。这些错误可能会扭曲系统发育和种群聚类分析,并误导使用 D 统计量的混合测试。我们介绍了一种生成伪单倍体序列的方法 Consensify,它可以控制由差异测序覆盖率导致的偏差,同时大大降低错误率。错误校正直接来自数据本身,无需额外的基因组资源或简化假设(例如同时采样)。对于系统发育和种群聚类分析,我们发现与基于单读采样的方法相比,Consensify 受人工制品的影响较小。对于 D 统计量,Consensify 对假阳性的抵抗力更强,并且与其他常用方法相比,不同实验室协议导致的偏差似乎影响较小。尽管 Consensify 是针对古基因组数据开发的,但它适用于任何低到中等覆盖率的短读数据集。我们预测,Consensify 将成为未来古基因组研究的有用工具。