XiaoMi-AI文件搜索系统
World File Search System随机分布

空间转录组学揭示了HBSAG损失患者的转录活性乙型肝炎病毒整合程度较低
抽象的客观丙型肝炎病毒(HBV)可以整合到感染的肝细胞的染色体中,从而有助于丙型肝炎表面抗原(HBSAG)和肝癌发生。在这项研究中,我们旨在探讨转录活性的HBV整合事件是否在慢性HBV感染的不同阶段中遍布整个肝组织,尤其是在HBSAG损失患者中。设计,我们构建了来自18个慢性HBV感染患者的13个059组织斑点的肝活检的高分辨率空间转录组,以分析转录活性病毒整合事件的发生和相对分布。进行了免疫组织化学,以评估HBSAG和HBV核心抗原的表达。通过实时qPCR定量肝内共价闭合圆形DNA(CCCDNA)水平。结果空间转录组测序鉴定出所有患者的肝组织斑点的存在1354个病毒宿主嵌合读数(13 059中的1026个),包括三名HBSAG丧失患者。这些HBV积分位点被随机分布在染色体上,可以定位于参与肝癌发生的宿主基因,例如Alb,Clu和ApoB。接受或接受过抗病毒治疗的患者的含病毒整合点的百分比明显较低,而嵌合读数的百分比明显少于没有治疗的患者。肝内CCCDNA水平与病毒整合事件很好地相关。结论在慢性HBV感染的患者的不同阶段,包括HBSAG损失患者,发生了转录活跃的HBV整合。抗病毒治疗与转录活性病毒整合的数量和程度降低有关,这意味着早期治疗干预措施可能会进一步减少病毒整合事件的数量。

全基因组的生物信息学分析甜蜜基因家族和Potentilla anserina中候选pasweet基因的表达验证
摘要:糖充当许多水果和蔬菜作物的主要能源。糖的生物合成和运输至关重要,尤其有助于生长和发育。甜蜜是一个重要的基因家族,在植物的生长,发育和适应各种类型的胁迫(生物和非生物)中起着至关重要的作用。尽管已经在许多植物物种中鉴定出甜蜜的基因,但在Potentilla Anserina中没有有关糖果的信息。在本研究中,我们进行了全面的基因组生物信息学分析,并确定了Potentilla anserina基因组中总共有23个候选PASWEET基因,这些基因在十个不同的染色体上随机分布。系统检查了这些基因的系统发育分析,染色体位置,基因结构,特定的顺式元素,蛋白质相互作用网络和生理特征。与拟南芥的系统发育关系的确定结果表明,这些Pasweet基因被分为四个进化枝(I,II,III和IV)。此外,通过定量的实时聚合酶链反应(QRT-PCR)验证,组织特异性基因表达验证,即鉴定出的Pasweets在各种组织(根,茎,叶子和花朵)中差异表达。主要是,有效地揭示了肿胀的pasweets(7、9和12)的相对折叠基因表达有效地表明,肿胀的块茎中的pasweet(7、9和12)在高度表达(300-,120倍和100倍)。在总体结果的基础上,建议PASWEETS(7、9和12)是参与P. anserina肿胀的块茎形成的候选基因。为了进一步阐明pasweets的功能(7、9和12),通过将它们插入烟草叶中,可以确认它们的亚细胞位置,并注意到这些基因存在于细胞膜上。在Crux中,我们推测我们的研究提供了一个有价值的理论基础,以进一步对PASWEET基因家族进行深入的功能分析及其在块茎发育中的作用,并进一步增强Potentilla Anserina的分子育种。

埃塞俄比亚商业银行的成本效率
线虫是丰富而普遍存在的动物,在种内水平上鲜为人知。这项工作是第一次尝试填补原遗传变异和分化的基本知识的差异,这是原骨oryctolagi,lagomorphs的线虫寄生虫。68 Cox1序列是从意大利北部和中部五个位置收集的棕色野兔获得的,突出了该物种内部大量遗传变异的存在。鉴定出的11个单倍型(等于0.702的单倍型多样性)分为两个谱系:谱系A(包括六个不同的单倍型,A1-A6)和谱系B(B1-B5)。遗传变异的平均内部量为0.3%,而差异差异百分比高十倍(3%)。这两个谱系在调查的地区非随机分布。血统A即使在北部地区(Emilia-Romagna)也偶尔发现了对意大利中部(Tus-Cany)的偏爱,而B-Haplotypes仅在Emilia-Romagna中存在。分子变量的分析确定了基因流的两个主要障碍:(i)将意大利中部(PIA和GR7)与北方的强大障碍(RE1,RE3和MO1;φST= 0.750,p = 0.00)分开。 (ii)一个二次微弱屏障,将钢琴岛与grosseto分开(φST= 0.133,p = 0.00)。在北部样品中发现了任何差异(φST= 0.009,p = 0.00)。最后,非常规缩短的扩增子的存在揭示了p中存在数字(线粒体基因的核副本)。观察到的数据可以通过几个因素来解释,从寄生虫的生物学(存在狭窄的宿主谱),最终宿主的行为(小型家用范围),宿主 - 寄生虫二元组的自然分散体发生在过去或最近的Passive人介导的迁移中。oryctolagi核基因组,建议使用DNA条形码作为鉴定属于该属的物种的独特标记时谨慎。

听快节奏的音乐可以延缓神经肌肉疲劳的发生
摘要 Centala, J、Pogorel, C、Pummill, SW 和 Malek, MH。听快节奏音乐会延缓神经肌肉疲劳的发生。J Strength Cond Res 34(3): 617–622, 2020—关于音乐对身体表现影响的研究主要集中在跑步至力竭的时间、血乳酸或最大摄氧量等结果上。肌电图疲劳阈值 (EMG FT ) 通过单次增量测试确定,操作上定义为在工作肌肉的 EMG 活动不增加的情况下可以无限期维持的最高运动强度。到目前为止,还没有研究检查过快节奏音乐对 EMG FT 的作用。因此,本研究的目的是确定快节奏音乐是否能减轻以 EMG FT 衡量的神经肌肉疲劳。我们假设,与对照条件相比,在运动期间听快节奏音乐会增加估计的 EMG FT。其次,我们假设在锻炼期间听快节奏音乐也会增加最大功率输出。十名健康的大学年龄男性(平均±SEM:年龄 25.3±0.8 岁[范围从 22 至 31 岁];体重 78.3±1.8 公斤;身高:1.77±0.02 米)两次访问实验室,间隔 7 天。每次访问时,EMG FT 由增量式单腿膝伸肌测力计确定。以随机顺序,受试者在两次访问中要么听音乐,要么不听音乐。所有音乐都以器乐形式呈现,节奏随机分布在 137 至 160 b·min 2 1 之间。结果表明,运动时听快节奏音乐可增加最大功率输出(无音乐:48 6 4;音乐:54 6 3 W;p = 0.02)和 EMG FT(无音乐:27 6 3;音乐:34 6 4 W;p = 0.008)。然而,两种条件(无音乐与有音乐)之间的绝对和相对运动末期心率以及运动末期运动腿自觉用力程度评分没有显著的平均差异。这些研究结果表明,听快节奏音乐可提高整体运动耐受力以及神经肌肉疲劳阈值。这些结果适用于运动和康复环境。

纯化β-1,3/1,6- ...
摘要:酵母菌纯化的β-1,3/1,6-葡聚糖(BG)可以调节狗的免疫系统和mi-Crobiome,但最佳纳入剂量仍然未知。该研究的目的是评估在干挤出饮食中将BG纳入0.0、0.07、0.14和0.28%的影响,对健康成年犬的消化率,免疫力和粪便微生物群的影响。八个男性和女性边界罪共毛孔[n = 4;身体状况评分(BCS)= 5]和英语Cocker Spaniels(n = 4; BCS = 5),年龄3.5±0.5岁,随机分布在两个4×4平衡的拉丁正方形中。Fecal microbiota (using 16S rRNA sequencing, Illumina ® ), apparent digestibility coefficients (ADC) of nutrients, fecal concentrations of short-chain fatty acids (SCFA) and branched-chain fatty acids (BCFA), ammoniacal nitrogen, lactic acid, IgA and pH, lymphocyte immunophenotyping, intensity确定吞噬作用和氧化爆发的百分比。在治疗之间没有观察到信仰(P = 0.1414)和Pielou-均匀度(p = 0.1151)的差异,但β多样性在0.0%和0.14%BG组之间差异(p = 0.047)。此外,Firmicutes门在所有组中都是最丰富的,并且在消耗0.14%BG后表现出最高的相对丰度,这一发现被认为对犬类微生物组有益。Erysipelotrichaceae和Ruminococcaceae家族以及粪便阶层和Prevotella属,被认为有利于其参与丁酸酯产量和其他代谢产物的有利,在消耗0.14%BG后的丰度增加了丰度。潜在的致病性蛋白杆菌状况显示出0.14%Bg后的丰度较低。繁殖化合物的粪便浓度和pH值在所有百分比的征服后没有差异。在0.14和0.28%BG消耗后发现了更高的粗蛋白ADC(P <0.0001),但对于其他营养素没有发现差异。吞噬作用,氧化爆发和淋巴细胞种群不受任何治疗的调节。但是,0.14%BG调节淋巴细胞T CD4 +:CD8 +比率(P = 0.0368),这是免疫系统效率的重要标志。纳入0.14%BG导致了最佳反应,并且是评估的最佳剂量。

电气工程机器学习的博士学位论文基于未来无线网络的资源分配
有效的资源分配是未来无线网络的关键挑战,尤其是随着用户需求,网络密度和网络复杂性的继续增长。传统上,用户终端的通道状态信息(CSI)用于资源分配。但是,随着网络密度的提高并考虑到移动用户的存在,基于CSI的重新源分配构成了大量的性能开销。这项工作通过利用对用户坐标信息培训的机器学习模式来探讨一种新颖的资源分配方法。具体来说,我们以三种方式制定了源分配问题:(1)调制和编码方案(MCS)运输能力最大化的预测,(2)基于用户位置的噪声限制系统中的资源分配,以及(3)资源分配干扰限制系统以确保公平性,同时最大化Capac-Ity。我们考虑两个用户放置方案进行性能评估:随机下降方案(RDS),其中用户是在传播环境中随机分布的,以及移动性模型方案(MMS),其中用户位置遵循线性轨迹。我们进行广泛的评估,以比较跨关键指标的RDS的数据集,包括训练样本的数量,计算复杂性和模型性能在不同的通道条件和错误的位置信息下。我们的结果表明,通过机器学习适应复杂的无线环境,基于坐标的资源分配了基于坐标的资源分配,从而实现了有效且可扩展的资源位置,同时在动态和不完善的条件下保持稳健的性能。我们提出的基于坐标的资源分配方案与基于CSI的资源分配方案相提并论,在具有变化的散点密度变化的干扰受限系统中至少达到90%的性能。此外,该方案大大优于基于几何资源分配方案,该方案凭直觉地应用了用户的坐标信息来依赖距离的资源分配。MMS数据集用于确定所提出的方案的实现成本,通过考虑一个现实的渠道模型,该模型在系统中持续收集数据样本。使用这种方法,我们将机器学习模型的训练时间,预测时间和记忆足迹进行比较。结果表明,基于坐标的资源分配方案可以可靠地用于有效的资源分配,同时分别为噪声限制和干扰有限的系统产生低至中等的实现成本。本研究强调了机器学习驱动的资源管理对未来无线网络的潜力,为智能,自适应和有效的通信系统铺平了道路。

人工智能算法预测骨科手术后处方镇痛鸡尾酒的疗效
骨科手术后使用止痛药缓解术后疼痛是围手术期医学的一个主要问题。特别是在肩部手术(例如肩袖修复)、全关节置换和肢体创伤的情况下,预计疼痛程度会很高;因此,必须采用高效的策略来加快恢复,避免患者不适和痛苦,并降低疼痛相关并发症的风险 [ 1 – 3 ]。在多模式疼痛治疗中,医生通常会联合使用两种或两种以上的止痛药 [ 4 , 5 ]。由于这些药物之间可能存在药理学相互作用,因此很少知道疗效的预测。相互作用可以基于作用机制(例如受体上的药效学)或药代动力学途径。例如,高达 95% 的双氯芬酸在吸收后与血清白蛋白结合,在肝脏中经 CYP 3A4 羟基化和葡萄糖醛酸化后经肾脏消除。临床效果是通过阻断环氧合酶 I 和 II 实现的,从而导致前列腺素的合成减少。对乙酰氨基酚也通过环氧合酶途径表现出其作用,抑制前列腺素合成。另一方面,阿片类药物通过受体起作用,这些受体对这些镇痛药具有特异性,在肝脏中经 CYP 3A4 羟基化后消除。因此,对于临床医生来说,两种以上药物的组合可能不清楚,并且对处方的净效应感到困惑。术后处方中含有具有各种药代动力学和药效学特性的阿片类药物和非阿片类药物。据我们所知,关于当以两种以上药物组合使用时这些特性如何变化的数据很少,而且很少发表(如果有的话)[6-11]。对具有大量止痛药组合的止痛药的任何统计评估都面临着严峻的挑战:使用传统统计方法得出结论极其困难。我们使用人工智能方法 [12-15] 来克服这一困难。我们使用(人工)神经网络(NN)进行数据分析;具体来说,我们使用称为自动编码器的无监督神经网络(图 1)。这些无监督神经网络通过最小化损失(输入和输出之间的差异的平方和,在训练集上取平均值)来生成高精度模拟输入的输出(因此得名:自动编码器)。特征向量在下一段中描述。然后,我们将每个输入特征向量的代码层权重用作降维特征向量的坐标(图 1)。疼痛程度是分类变量,所施用的止痛药也是如此。我们使用独热编码为每个患者生成一个 38 维特征向量(参见方法部分)。这些特征向量并不独立。降维算法(神经网络自动编码器)找到独立性并将结果映射到二维流形(平面图)上。每个患者都是这个平面上的一个点,这些点不是随机分布的;相反,它们是聚集的。在我们掌握的众多聚类算法中,我们使用 DBSCAN 聚类算法 [ 16 ],因为将其应用于点可以识别出具有许多共同止痛药的鸡尾酒聚类。相互依赖性产生包含高效止痛药的聚类;正如我们下面讨论的那样,这一发现无法通过任何其他方式找到(有 61 种不同的止痛药鸡尾酒,总共 750×2 = 1500 种疼痛

第38届Warman设计和建立竞赛
上下文Gondwana是一个行星上的一个岛屿,在银河系外边缘上绕着一颗星星。冈瓦南人几乎用尽了天然燃料,迫切需要一种可持续的选择。,包括植物和野生动植物在内的居民,如果没有发现其他选择,冬季将在冬季冻结或过热。迫在眉睫的燃料的耗竭是迫在眉睫的。 陨石,含有可持续能源供应有用的稀有矿物质,最近降落在岛上的随机位置。 已经确定了三个具有各种大小和重量的陨石供立即使用,但由于大气温度的迅速上升,必须自主收集并沉积在不稳定桥另一侧的燃油掩体中。 高温环境意味着必须快速完成此过程。 冈瓦南人再次要求地球学生工程师的协助设计一个系统,以将陨石收集并将其存放到存储掩体中。 将制造和演示其设计的缩放原型。 您的学生工程师团队已确定设计和建立缩小规模,演示系统的任务,该系统能够收集三个型号的陨石并将其安全地存入存储库。 在过去的37年中,地球工程专业的学生在此类工程问题方面提供了宝贵的帮助,我们预计您将在第三十八次获得成功。 参考图1,自主系统将从起始区域定义的安全区域开始。迫在眉睫的燃料的耗竭是迫在眉睫的。陨石,含有可持续能源供应有用的稀有矿物质,最近降落在岛上的随机位置。已经确定了三个具有各种大小和重量的陨石供立即使用,但由于大气温度的迅速上升,必须自主收集并沉积在不稳定桥另一侧的燃油掩体中。高温环境意味着必须快速完成此过程。冈瓦南人再次要求地球学生工程师的协助设计一个系统,以将陨石收集并将其存放到存储掩体中。将制造和演示其设计的缩放原型。您的学生工程师团队已确定设计和建立缩小规模,演示系统的任务,该系统能够收集三个型号的陨石并将其安全地存入存储库。在过去的37年中,地球工程专业的学生在此类工程问题方面提供了宝贵的帮助,我们预计您将在第三十八次获得成功。参考图1,自主系统将从起始区域定义的安全区域开始。客观原型缩小规模,概念验证传输系统,后来称为“系统”,该系统将精确地传递陨石的比例表示,从各自的沉降区域到存储掩体。将使用网球,壁球和乒乓球(因此称为“球”)模拟陨石,该球将在3 x 3网格中随机分布。系统必须横穿狭窄的间隙和潜在的不稳定地形,这是由旋转平面或seesaw模拟的。尺寸约束要求您的系统适合虚构的400毫米侧立方体。通过单个起始动作激活时,您的系统将自主收集球,协商雪索或狭窄的间隙,然后将其传递到存储掩体,显示为球矿床区域。操作的最大允许时间为120秒。
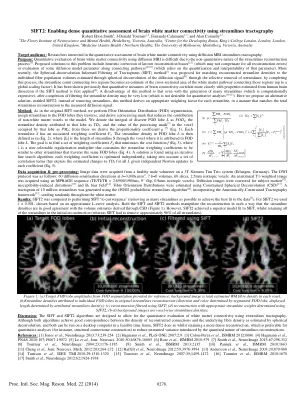
SIFT2:利用流线纤维束成像技术对大脑白质连接进行密集定量评估
目标受众:对使用扩散 MRI 流线纤维束成像定量评估大脑白质连接感兴趣的研究人员。目的:由于流线重建过程的非定量性质 [1],使用扩散 MRI 定量评估大脑白质连接非常困难。针对该问题提出的解决方案包括启发式校正已知的重建偏差 [2,3](可能无法补偿所有重建误差)或评估连接路径上某些扩散模型参数 [4,5,6](依赖于该参数的量化和可解释性)。最近,提出了球面反卷积信息纤维束成像滤波 (SIFT) 方法 [7],通过选择性去除流线,将重建的流线密度与通过扩散信号球面反卷积估计的单个纤维群体积 [8] 进行匹配;完成此过程后,连接两个区域的流线计数变为连接这些区域的白质通路横截面积的估计值(最高可达全局缩放因子)。之前已证明,如果首先应用 SIFT 方法 [9],大脑连接的定量测量与从人脑解剖估计的特性会更加密切相关。这种方法的缺点是,即使生成了许多流线(计算成本高昂),完成过滤后,流线密度可能非常低(这对于定量分析来说是不可取的 [10,11])。在这里,我们提出了一种替代解决方案,称为 SIFT2:此方法不是去除流线,而是为每条流线得出合适的加权因子,以使总流线重建与测量的扩散信号相匹配。方法:与原始 SIFT 方法一样,我们执行纤维方向分布 (FOD) 分割,将流线分配给它们穿过的 FOD 叶,并得出一个处理掩模,以减少非白质体素对模型的贡献。我们将离散 FOD 叶 L 的积分表示为 FOD L ,将归因于该叶的流线密度表示为 TD L ,将处理掩模 [7] 在该叶所占体素中的值表示为 PM L ;从这些中我们得出比例系数 μ [7](等式 1)。每条流线 S 都有一个关联的加权系数 FS 。FOD 叶 L 中的流线密度定义为(等式 2),其中 | SL | 是流线 S 穿过归因于 FOD 叶 L 的体素的长度。目标是找到一组加权系数 FS ,以最小化成本函数 f(等式 3),其中 λ 是用户可选择的正则化乘数,它将流线加权系数约束为与穿过相同 FOD 叶的其他流线相似(等式 4)。使用迭代线搜索算法可以找到解决方案:每个加权系数都经过独立优化,同时考虑一组相关项,这些相关项表示在对每个系数进行独立牛顿更新的情况下所有 L 的 TD L 的估计变化(等式 5)。数据采集和预处理:图像数据是从健康男性志愿者的 3T Siemens Tim Trio 系统(德国埃尔朗根)上采集的。DWI 协议如下:60 个弥散敏化方向,b =3,000s.mm -2,7 b =0 体积,60 个切片,2.5mm 各向同性体素。使用 MPRAGE 序列(TE/TI/TR = 2.6/900/1900ms,9° 翻转,0.9mm 各向同性体素)获取解剖 T1 加权图像。对弥散图像进行了校正以适应受试者运动 [12]、磁化率引起的扭曲 [13] 和 B 1 偏置场 [14]。使用约束球面反卷积 (CSD) [15] 估计纤维取向分布。使用 iFOD2 概率流线算法 [16] 生成了 1000 万条流线的纤维束图,该算法结合了解剖约束纤维束成像框架 [17] ,随机分布在整个白质中。结果:将 SIFT2 与执行 SIFT“收敛”(移除尽可能多的流线以实现与数据的最佳拟合 [7] )进行了比较。对于 SIFT2,我们使用了 λ = 0.001,这是基于近似 L 曲线分析选择的。SIFT 和 SIFT2 方法都以这样一种方式操纵重建,使得流线密度与通过 CSD 得出的体积估计值高度一致(图 1)。然而,SIFT2 实现了比 SIFT 更优秀的模型拟合,同时保留了初始重建中的所有流线(而 SIFT 必须去除大约 96% 的流线)。根据近似 L 曲线分析选择。SIFT 和 SIFT2 方法都以流线密度与通过 CSD 得出的体积估计值高度一致的方式操纵重建(图 1)。然而,SIFT2 实现了比 SIFT 更好的模型拟合,同时保留了初始重建中的所有流线(而 SIFT 必须删除大约 96% 的所有流线)。根据近似 L 曲线分析选择。SIFT 和 SIFT2 方法都以流线密度与通过 CSD 得出的体积估计值高度一致的方式操纵重建(图 1)。然而,SIFT2 实现了比 SIFT 更好的模型拟合,同时保留了初始重建中的所有流线(而 SIFT 必须删除大约 96% 的所有流线)。

原始人的自然经济
焦磷酸测序:Roche模板由EMPCR 1制备,其中1-20万珠沉积在PTP井中。较小的珠,带有连接的硫酸酶和荧光素酶围绕模板珠。单个DNTP依次流过井,以预定的顺序分配。在掺入补体DNTP时,释放的PP I被转换为ATP,从荧光素蛋白到羟基二耐蛋白的氧化产生光。读取平均400个基础作为流程图。对于均聚物,重复多达六个核苷酸,添加的DNTP的数量与光信号成正比。插入是最常见的错误类型,其次是删除。通过连接测序:将约1亿个EMPCR的模板珠沉积在载玻片上。在退火时,添加了1,2个探针的库。适当的条件使选择性杂交和探针结扎到互补位置。1,2探针的第一个(y)和第二(z)位置被设计为审讯库,因此16个二核苷酸由四种染料编码。在四色成像之后,将带状的1,2探针化学裂解以产生5'-PO 4组(P)。杂交,连接,成像和裂解的循环又重复了六次。然后从模板中剥离扩展引物,并使用N – 1底漆进行第二个连接弹,该底漆将询问底座重置为左侧的一个位置。询问每个基础两倍,提高了颜色调用的准确性。随后发生了七个连接周期,然后再进行三个结扎弹。然后将35个数据位组成的字符串在色彩空间中编码,然后对准参考基因组以解码DNA序列。替换是最常见的错误类型。可逆终结器:DNA片段的Illumina Bridge放大是在载玻片的八个通道上随机分布的,高密度向前和反向引物共价附加到其上。固相扩增可从单个ssDNA模板产生约8000万个MC。将底漆退火到每个MC中模板的自由末端。聚合酶延伸,然后终止从四个RTs组中的DNA合成,每组用不同的染料标记。未合并的RT被洗净,通过四颜色成像进行基础识别,并通过化学裂解去除阻塞和染料组以允许下一个周期。给定MC的颜色图像提供了〜45个基础的读取。替换是最常见的错误类型。使用RTS进行单分子测序:Helicos数十亿个未夸大的ssDNA模板是用poly(da)尾巴制备的,这些尾巴与聚(DT)引物杂交,共同连接到载玻片上。对于一通测序,该引物 - 模板复合物就足够了。两通序测序涉及复制模板链,删除原始模板,并退火向表面(未显示)。与Illumina的RT不同,这四个Helicos RT用相同的染料标记,并以预定的顺序单独分配。融合事件导致荧光信号。使用单分子消除了Dephasing的问题,其中给定MC内的数千个复制模板不会有效地扩展其引物。删除是最常见的误差类型,可以通过提供约25个基本共识读取的两次测序可大大降低。的应用和挑战100篇论文描述了这些创新的成果。虽然改进继续,但读取长度限制,错误类型和频率显着影响组装策略。对于简短(<100个基本)读取平台,通过映射到参考基因组来指导组装。结合Sanger和Roche数据(100个基本读数)改善了从头组件2,并且随着焦磷酸测序读取长度的改进,使用混合Roche(250键读数)和Illumina数据进行了改善,已经描述了从头组装。最近使用Roche 4和Illumina平台报告了第一个个性化基因组测序项目。Roche,Illumina和AB平台在1,000个基因组项目中被用于生成人类遗传变异的详细图表以及人类微生物组项目,以将微生物组动态与人类健康相关联。应用不限于测序基因组。共识计数分析5最近出现了,从而实现了转录因子结合,mRNA剪接,DNA甲基化,小RNA,染色质结构和DNase超敏位点的全局分析。配对的测序方案。这些不仅对从头组件很重要,而且对于识别结构变化和映射mRNA剪接同工型。展望未来,太平洋生物科学,多佛系统(Polonator G.007),Visigen Biotechnologies,Lasergen,Inc。,Intelligent Bio-Symys,完整的基因组学和牛津Nanopore技术等公司的平台开发。