XiaoMi-AI文件搜索系统
World File Search SystemBsaI

GO-CRISP 克隆协议
使用下面的引物模板(表 1),片段 2 可以通过 PCR 扩增(图 4A)。我们建议使用 gRNA NIA TLS1/2 作为 PCR 模板。“NNNNNNNNNNNNNNNNNNNN”(表 1)代表应由 gRNA 靶序列替换的核苷酸。用于创建 NIA1 靶向片段 2 的引物列于下方作为示例(表 1)——这些引物用于创建 gRNA NIA TLS1/2。引物还在片段末端添加了 BsaI 切割位点(图 4A),这些位点与 gRNA 片段 1 TLS1/2 中的双 BsaI 位点兼容。

通过 CRISPR/Cas9 双重靶向对 StERF3 基因进行功能性抑制可增强 Solanum Tuberosum L. 对晚疫病的抵抗力。
分别使用嵌合引物UF/UT (-)和gRT (+)/gR-R进行扩增,其中靶序列被设计在gRT (+)和UT (-)引物中。在嵌套PCR位点特异性引物对的第二个PCR反应中,使用含有BsaI切割位点的Pps/Pgs来扩增带有靶序列的sgRNA表达盒。BsaI位点被设计在用于Golden Gate连接的位点特异性引物中。BsaI属于IIs型限制性内切酶,具有一种新的切割特性,可以产生非回文的独特粘性末端,从而避免自连接和连接不相容末端[39]。我们使用Golden Gate克隆策略制备了pYLCRISPR/Cas9Pubi-BstERF3构建体,该构建体携带两个由OsU6a启动子驱动的sgRNA表达盒,用于马铃薯的基因靶向。

crispr-tsko的金门装配
在第一步中,将六个金门入口向量合并为目标向量。有各种可以使用的金门目标向量,其中包含可以使用的不同植物和/或视觉标记物(请参阅补充数据集1中的金门目标矢量(CCDB +)1)。第一个入口向量(AB)包含组织特异性表达的启动子。第三个入口矢量(CD)包含核酸酶,可以与N末端(BC)或C末端标签(DE)结合使用。另外,如果不需要标签,则使用链接序列。第五入口矢量(EF)包含工厂终结器。选择的第六个黄金入口向量(FG)取决于最终目标。要克隆与一个或两个GRNA兼容的矢量,请使用未武装的GRNA进入矢量PGG-F-F-ATU6-26-AARI-AARI-AARI-G(请参阅补充数据集1中的未武装GRNA进入向量1)。要克隆与多个GRNA兼容的矢量,请使用可变的链接器PGG-F-a-aari-sacb-aari-g-g(请参阅补充数据集1中的可变链接器)。由于我们的克隆策略使用限制酶Bsai和Aari,因此要求所有向量都需要无BSAI和AARI-FIME(除了克隆位点)。

BioXp® Select DNA 克隆试剂盒、Golden Gate 组装体...
图 1. BioXp 上的 Golden Gate 组装。Golden Gate 组装概览。要克隆的插入 DNA 带有侧翼 GG 酶识别位点(BsaI 和/或 BsmBI),可以作为合成基因片段或 PCR 扩增子(1A)和(1B)或预克隆载体格式(1C)获取。用户可以输入任何具有兼容 GG 突出端(以粉色和紫色显示)的所需目标载体(2)。用户在 BioXp 3250 上输入 96 孔板和 GG 克隆条(4)。GG 克隆产品在 BioXp 运行后作为输出交付(5)。

基因编辑φx174
There are no restriction sites for the following enzymes: AarI(x), Acc65I, AcuI, AfeI, AgeI, AlwI, AlwNI, ApaI, AscI, AsiSI, AvrII, BamHI, BanII, BclI, BglI, BglII, BlpI, BmgBI, BmrI, BmtI, BsaI, BsaXI, BsgI, BsmBI, BspDI, BspEI, BsrFI, BsrGI, BstBI, BstEII, BstYI, BstZ17I, Bsu36I, ClaI, DpnI, DpnI, EagI, EcoN, EcoO1 FseI, FspAI(x), HindIII, I-CeeI, I-SceI, CPNI,MBOI,MSCI,NEI,NCOI,NDEI,NGOMIV,NHEI,NENI,NSSII,NSSII,NSPI,PFLI,PFLI,PMMI,PMLI,PMLI,P; PMLI,P; PMLI,P; PMLI,PPUTMI,PPHMI,PPHMI,PPHMI,PPHMI,PPHMI,P; PSPOME,PSPXI,PVI,PVII,RSRII,SACI,SALI,SALI,SANDI(X),SAU3AI,SBFI,SFII,SFII,SFII,SGRI,SGRI,SGRI,SMAI,SMAI,SMAI,SNABI,SPEI,SPEI,SPEI,SPHI,SPHI,SPHI,SRFMI(SRFMI(X)

φx174
There are no restriction sites for the following enzymes: AarI(x), Acc65I, AcuI, AfeI, AgeI, AlwI, AlwNI, ApaI, AscI, AsiSI, AvrII, BamHI, BanII, BclI, BglI, BglII, BlpI, BmgBI, BmrI, BmtI, BsaI, BsaXI, BsgI, BsmBI, BspDI, BspEI, BsrFI, BsrGI, BstBI, BstEII, BstYI, BstZ17I, Bsu36I, ClaI, DpnI, DpnI, EagI, EcoN, EcoO1 FseI, FspAI(x), HindIII, I-CeeI, I-SceI, CPNI,MBOI,MSCI,NEI,NCOI,NDEI,NGOMIV,NHEI,NENI,NSSII,NSSII,NSPI,PFLI,PFLI,PMMI,PMLI,PMLI,P; PMLI,P; PMLI,P; PMLI,PPUTMI,PPHMI,PPHMI,PPHMI,PPHMI,PPHMI,P; PSPOME,PSPXI,PVI,PVII,RSRII,SACI,SALI,SALI,SANDI(X),SAU3AI,SBFI,SFII,SFII,SFII,SGRI,SGRI,SGRI,SMAI,SMAI,SMAI,SNABI,SPEI,SPEI,SPEI,SPHI,SPHI,SPHI,SRFMI(SRFMI(X)

蓖麻植物中的 CRISPR/Cas9 介导基因组编辑......
摘要 动机:CRISPR/Cas9 技术已被开发为最有效和最广泛使用的基因组编辑工具,用于修改众多植物的基因组,其中双链 DNA 中的 cas9 切割由单个向导 RNA(sgRNA)中包含的 20 个核苷酸序列驱动。然而,使用 CRISPR/Cas9 同时编辑多个目标仍然是该领域的技术挑战(Ma 等人,2014 年)。方法:在本研究中,使用 Golden Gate Assembly 克隆策略生成多个 CRISPR/cas9 编辑结构以用于蓖麻植物。模块化克隆系统使用 IIS 型酶在其识别位点外切割,从而允许有效组装具有兼容突出端的 DNA 片段,从而同时促进多个序列的正确取向(Engler 等人,2014 年)。我们的主要目标是获得一种遗传构建体,允许在同一个质粒载体中表达两个 sgRNA 和 cas9 核酸酶,以便通过农杆菌感染转化蓖麻。选择了两个针对 FAH12 蓖麻羟化酶的 CRISPR 靶标以避免可能的脱靶。这些靶标包含在 sgRNA 中并克隆到 0 级质粒中,每个质粒两侧都有 BsaI 酶的限制位点。Golden Gate 1 级反应包括几个 BsaI 消化和连接循环,将 U6 启动子与两个 sgRNA 分别组装到 1 级质粒中,两侧都有 BpiI 限制位点。同时,cas9 酶在双强 35S 启动子的控制下克隆,随后是来自 0 级质粒的胭脂碱合酶 (nosT) 终止子,包括这些元素,克隆到另一个 1 级质粒中,两侧也有 BpiI 限制位点。然后,用 BpiI 消化所有 1 级元件(U6-sgRNA1、U6-sgRNA2、2x35S-cas9-nosT)时,会出现兼容的突出端,这些突出端可以以正确的顺序和方向组装成 2 级结构。最终结果是 2 级质粒,其中包括 FAH12 羟化酶的 CRISPR/cas9 多重基因组编辑所需的所有元件。该构建体将转移到农杆菌中,以便以后进行蓖麻胚转化。

使用综合性
多个组件部分的长DNA序列的一锅组装是现代合成生物学构建的迅速产生的关键。的一锅组装方法的方法是由短悬垂链接的多个片段(例如金门)取决于准确和公正的连接。迄今为止的连接设计很大程度上取决于使用经验法则和经验成功的使用,而不是有关连接酶保真度和偏见的详细数据。在这项研究中,我们应用了太平洋生物科学单分子实时测序技术来直接测量单个实验中每个可能的5'基础悬垂配对的连接频率。使用IIS类型限制酶BSAI,已应用此综合数据集来预测金门组装(GGA)的准确性。基于连接数据设计的十个片段组件,其连接数据预计会导致高或低的保真度组件。实验结果不仅证实了总体准确性,还确认了观察到的特定不匹配连接误差及其相对频率。数据进一步用于设计LAC操纵子的12-或24-片段组件,这些组件被证明以高忠诚度和效率组装。因此,连接酶保真度数据允许预测高准确的悬垂对套件的设计比经验法则更大的灵活性,即使在定义的编码区域内,也可以在没有天然DNA序列修改的情况下,在高准确的连接点上安装> 20个片段。

高粱高粱醇溶蛋白基因定点诱变的双元载体构建
高粱 (Sorghum bicolor (L.) Moench) 是世界主要的农业生产谷物作物之一,在干旱地区具有特殊重要性。然而,与其他谷物不同,高粱的营养价值较低,这是由于其种子储存蛋白 (kafirins) 对蛋白酶消化具有抗性等原因造成的。提高高粱营养价值的有效方法之一是获得部分或完全抑制 kafirins 合成或改变 kafirins 氨基酸组成的突变体。利用基因组编辑可以通过在 α- 和 γ-kafirin 基因的核苷酸序列中引入突变来解决此问题。在本研究中,选择了基因组靶基序 (23 bp 序列) 以将突变引入高粱的 α- 和 γ-KAFIRIN 基因。使用在线工具 CRISPROR 和 CHOPCHOP 进行 gRNA 的设计。为 α-KAFIRIN (k1C5) 和 γ-KAFIRIN (gKAF1) 基因选择了两个最合适的靶标。在 BsaI (Eco31I) 位点将相应序列插入通用载体 pSH121。通过 DNA 测序验证克隆过程。使用 SfiI 限制位点将所得构建体亚克隆到兼容的二元载体 B479p7oUZm-LH 中。通过使用 MluI 和 SfiI 切割位点的限制分析确认二元载体的正确组装。通过电穿孔将创建的四个载体 (1C - 4C) 转移到农杆菌菌株 AGL0 中。目前,该载体系列用于使用未成熟胚外植体对高粱进行稳定转化。
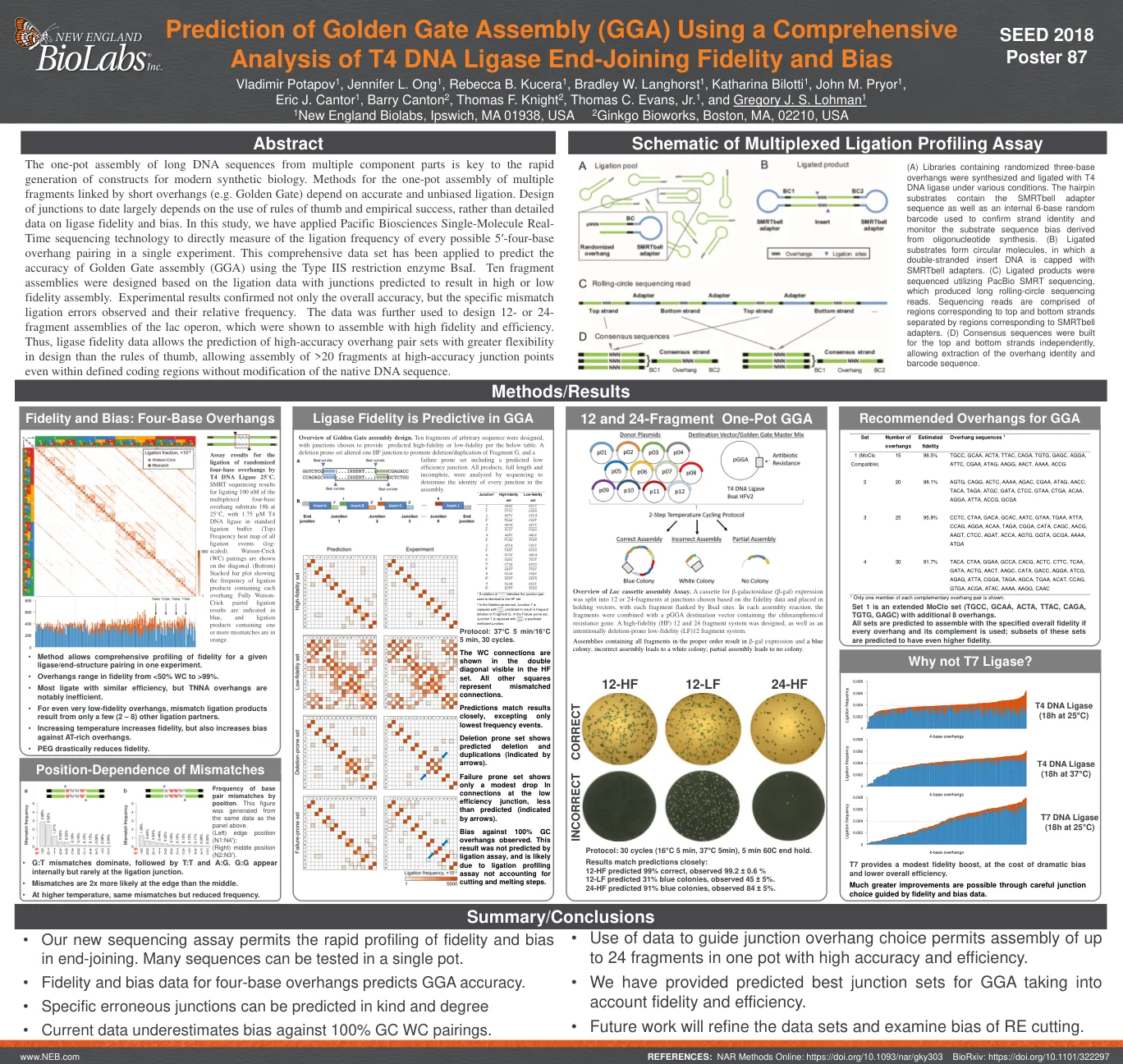
使用综合方法预测金门组装 (GGA)
一锅法组装来自多个组成部分的长 DNA 序列是快速生成现代合成生物学构建体的关键。一锅法组装由短悬垂结构(例如 Golden Gate)连接的多个片段的方法取决于准确和无偏的连接。迄今为止,连接点的设计很大程度上取决于经验法则和经验成功,而不是连接酶保真度和偏向性的详细数据。在本研究中,我们应用 Pacific Biosciences 单分子实时测序技术在一次实验中直接测量每个可能的 5′-四碱基悬垂结构配对的连接频率。该综合数据集已用于预测使用 IIS 型限制性酶 BsaI 的 Golden Gate 组装 (GGA) 的准确性。根据连接数据设计了十个片段组装,其中连接点预测会导致高或低保真度组装。实验结果不仅证实了总体准确性,还证实了观察到的特定错配连接错误及其相对频率。这些数据还用于设计 12 或 24 个片段的乳糖操纵子组装体,结果表明组装体具有高保真度和高效率。因此,连接酶保真度数据可以预测高精度突出端对集,设计灵活性比经验法则更高,即使在定义的编码区域内也可以在高精度连接点组装 20 多个片段,而无需修改天然 DNA 序列。