XiaoMi-AI文件搜索系统
World File Search SystemBures

双重性的双重性和形状距离,对比较神经表示的影响
已经提出了神经网络表示之间的多种(DIS)相似性度量,从而导致了零散的研究景观。这些措施中的大多数属于两个类别之一。首先,诸如线性回归,规范相关分析(CCA)和形状距离之类的措施,都学习神经单位之间的明确映射,以量化相似性,同时考虑预期的不断增长。第二,诸如表示相似性分析(RSA),中心内核比对(CKA)和归一化Bures相似性(NBS)之类的措施都量化了摘要统计数据中的相似性,例如逐个刺激的内核矩阵,它们已经不一致地是预期的。在这里,我们通过观察Riemannian形状距离的余弦(从类别1)等于NB(来自类别2)来统一这两个广泛的方法的步骤。我们探讨了这种联系如何导致形状距离和NB的新解释,并将这些措施的对比与CKA进行对比,这是深度学习文献中的流行相似性度量。

群作用和单调量子度量张量
作用 β 在 S 上是传递的,并将其变成齐次流形[2-5]。因此,U(H) 正则作用的基本向量场形成 GL(H) 作用的基本向量场代数的李子代数。[6] 证明了,为了描述 β 的基本向量场,只需考虑 U(H) 在 S(H) 上的正则作用的基本向量场以及与期望值函数 la(ρ)=Tr(aρ) 相关的梯度向量场,其中 a 是 H 上有界线性算子空间 B(H) 中的任意自伴元素,借助于所谓的 Bures-Helstrom 度量张量 [7-12]。这个例子提供了酉群 U(H)、S(H) 的 GL(H) - 齐次流形结构、Bures–Helstrom 度量张量和期望值函数之间的意外联系。然而,这并不是单调度量张量与一般线性群 GL(H) “相互作用”的唯一例子。事实上,在 [6] 中,还证明了 U(H) 正则作用的基本向量场以及与期望值函数相关的梯度向量场通过 Wigner–Yanase 度量


将曼德尔斯塔姆-塔姆量子速度极限扩展到混合态系统
摘要 Mandelstam-Tamm 量子速度极限 (QSL) 对纯态封闭系统的演化速度设定了一个上限。在本文中,我们推导出该 QSL 的几种扩展,以用于混合态封闭系统。我们还比较了这些扩展的强度并检查了它们的紧密性。Mandelstam-Tamm QSL 最广泛使用的扩展源自 Uhlmann 的能量色散估计。我们仔细分析了该估计的底层几何,该分析表明 Bures 度量或等效的量子 Fisher 信息很少会产生紧密扩展。这一观察结果引导我们解决是否存在 Mandelstam-Tamm QSL 的最紧密通用扩展。使用与 Uhlmann 开发的几何构造类似的几何构造,我们证明了情况确实如此。此外,我们表明混合态的紧密演化通常由时变哈密顿量产生,这与纯态系统的情况形成对比。

量子限制相位不敏感的最佳增益感应......
相位不敏感光放大器均匀放大输入场的每个正交部分,具有基础和技术重要性。我们发现使用多模探针估计量子限制相位不敏感放大器增益的精度存在量子极限,该多模探针也可能与辅助系统纠缠。与损耗参数的感测形成鲜明对比的是,探针的平均光子数 N 和输入模式数 M 被发现是等效且可互换的最佳增益感测资源。所有纯态探针在放大器输入模式上的简化状态在多模数基础上对角化,在相同的增益独立测量下被证明是量子最优的。我们将使用经典探针可实现的最佳精度与基于显式光子计数的估计器对量子探针的性能进行了比较,并表明即使对于单光子探针和低效光电检测也存在优势。还推导出了两个产品放大器通道之间能量受限 Bures 距离的闭式表达式。

信息几何、Jordan 代数和共轭轨道构造
摘要。Jordan 代数自然出现在 (量子) 信息几何中,我们希望了解它们在该框架内的作用和结构。受 Kirillov 对余伴轨道辛结构的讨论的启发,我们在实 Jordan 代数的情况下提供了类似的构造。给定一个实数、有限维、形式上实数的 Jordan 代数 J ,我们利用由对偶 J ⋆ 上的 Jordan 积确定的广义分布在分布的叶子上诱导一个伪黎曼度量张量。特别是,这些叶子是李群的轨道,李群是 J 的结构群,与余伴轨道的情况类似。然而,这一次与李代数情况相反,我们证明 J ∗ 中并非所有点都位于正则 Jordan 分布的叶子上。当叶子节点包含在 J 上的正线性泛函锥中时,伪黎曼结构就变为黎曼结构,并且对于适当的 J 选择,它与有限样本空间上非正则化概率分布的 Fisher-Rao 度量相一致,或者与有限级量子系统的非正则化忠实量子态的 Bures-Helstrom 度量相一致,从而表明 Jordan 代数数学与经典和量子信息几何之间的直接联系。

量子卡方断层扫描和互信息测试
量子态层析成像——从 𝑛 副本中学习 𝑑 维量子态——是量子信息科学中一项普遍存在的任务。它是从 𝑛 样本中学习 𝑑 结果概率分布的经典任务的量子类似物。更详细地说,目标是设计一种算法,给定某个(通常是混合的)量子态 𝜌 ∈ C 𝑑 × 𝑑 的 𝜌 ⊗ 𝑛 ,输出(经典描述)估计值 2 ̂︀ 𝜌,该估计值以高概率“𝜖 接近”𝜌。主要挑战是最小化样本(复制)复杂度 𝑛 作为 𝑑 和 𝜖(有时还有其他参数,例如 𝑟 = rank 𝜌 )的函数。我们还将关注设计仅进行单次复制(而不是集体)测量的算法的实际问题。指定量子断层扫描任务的一个重要方面是“ 𝜖 -close”的含义;即,判断算法估计的损失函数是什么。有很多自然的方法可以测量两个量子态的发散度——甚至比两个经典概率分布的发散度还要多——并且所选择的精确测量方法会对必要的样本复杂度以及最终估计对未来应用的效用产生很大的影响。本文的主要目标是展示一种新的断层扫描算法,该算法实现了最严格的准确度概念(Bures)𝜒 2 -发散度,同时具有与使用不忠诚度作为损失函数的先前已知算法基本相同的样本复杂度。然后,我们给出了一个应用,即量子互信息测试问题,这关键依赖于我们实现关于𝜒 2 -发散度的有效状态断层扫描的能力。

量子卡方断层扫描和互信息测试
量子态断层扫描(从 𝑛 个副本中学习 𝑑 维量子态)是量子信息科学中一项普遍存在的任务。它是从 𝑛 个样本中学习 𝑑 结果概率分布的经典任务的量子类似物。更详细地说,目标是设计一种算法,给定某个(通常是混合的)量子态 𝜌 ∈ C 𝑑 × 𝑑 的 𝜌 ⊗ 𝑛,输出一个估计值 2 ̂︀ 𝜌(的经典描述),该估计值以高概率“𝜖 接近”𝜌。主要挑战是将样本(副本)复杂度 𝑛 最小化为 𝑑 和 𝜖(有时还有其他参数,例如 𝑟 = 秩 𝜌 )的函数。我们还将关注设计仅进行单次(而不是集体)测量的算法的实际问题。指定量子断层扫描任务的一个重要方面是“𝜖-close”的含义;即,判断算法估计的损失函数是什么。有很多自然的方法可以测量两个量子态的发散度——甚至比两个经典概率分布的发散度还要多——并且所选择的精确测量方法会对必要的样本复杂度以及最终估计对未来应用的效用产生很大的影响。本文的主要目标是展示一种新的断层扫描算法,该算法实现最严格的准确度概念(Bures)𝜒 2 -发散度,同时具有与以前使用不忠诚度作为损失函数的算法基本相同的样本复杂度。然后,我们给出了一个应用,即量子互信息测试问题,这关键依赖于我们实现关于𝜒 2 -发散度的有效状态断层扫描的能力。
![arXiv:2212.03796v3 [quant-ph] 2024 年 10 月 4 日](/simg/5\556eb4fe5062250c9ddec40d867b5a857c06018f.webp)
arXiv:2212.03796v3 [quant-ph] 2024 年 10 月 4 日
在本文中,我们应用量子信道和开放系统状态演化的理论,提出了一种用于量子隐马尔可夫模型 (QHMM) 的酉参数化和高效学习算法。我们将任何具有非平凡算子和表示的量子信道视为具有隐藏动态和可测量发射的随机系统。通过利用量子信道更丰富的动态,特别是通过混合状态,我们证明了量子随机生成器比经典生成器具有更高的效率。具体而言,我们证明了可以在量子希尔伯特空间中使用比经典随机向量空间少二次的维度来模拟随机过程。为了在量子硬件上的电路计算模型中实现 QHMM,我们采用了 Stinespring 的扩张构造。我们表明,可以使用具有中间电路测量的量子电路有效地实现和模拟任何 QHMM。在酉电路的假设空间中,可行的 QHMM 学习的一个关键优势在于 Stinespring 扩张的连续性。具体而言,如果通道的酉参数化在算子范数中接近,则相应通道在钻石范数和 Bures 距离中也将接近。此属性为定义具有连续适应度景观的高效学习算法奠定了基础。通过采用 QHMM 的酉参数化,我们建立了一个正式的生成学习模型。该模型形式化了目标随机过程语言的经验分布,定义了量子电路的假设空间,并引入了一个经验随机散度度量——假设适应度——作为学习成功的标准。我们证明,该学习模型具有平滑的搜索景观,这归因于 Stinespring 扩张的连续性。假设空间和适应度空间之间的平滑映射有助于开发高效的启发式和梯度下降算法。我们考虑了四种随机过程语言的例子,并使用超参数自适应进化搜索和多参数非线性优化技术训练 QHMM,这些技术应用于参数化的量子拟设电路。我们通过在量子硬件上运行最优电路来确认我们的结果。
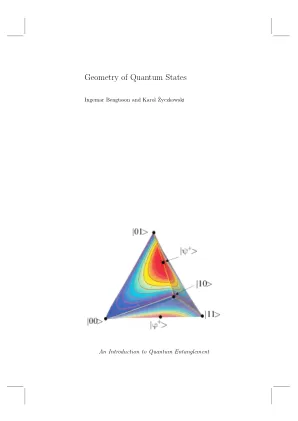
量子态的几何
[1] S. Abe。关于非广延物理中广义熵的 q 变形理论方面的注释。Phys. Lett.,A 224:326,1997 年。[2] S. Abe 和 AK Rajagopal。非加性条件熵及其对局部现实主义的意义。Physica,A 289:157,2001 年。[3] L. Accardi。非相对论量子力学作为非交换马尔可夫过程。Adv. Math.,20:329,1976 年。[4] A. Ac´ın、A. Andrianov、L. Costa、E. Jan´e、JI Latorre 和 R. Tarrach。三量子比特态的广义 Schmidt 分解和分类。Phys. Rev. Lett. ,85:1560,2000 年。[5] A. Ac´ın、A. Andrianov、E. Jan´e 和 R. Tarrach。三量子比特纯态正则形式。J. Phys.,A 34:6725,2001 年。[6] M. Adelman、JV Corbett 和 C. A Hurst。状态空间的几何形状。Found. Phys.,23:211,1993 年。[7] G. Agarwal。原子相干态表示态多极子与广义相空间分布之间的关系。Phys. Rev.,A 24:2889,1981 年。[8] SJ Akhtarshenas 和 M. A Jafarizadeh。贝尔可分解态的纠缠稳健性。E. Phys. J. ,D 25:293,2003 年。[9] SJ Akhtarshenas 和 MA Jafarizadeh。某些二分系统的最佳 Lewenstein-Sanpera 分解。J. Phys. ,A 37:2965,2004 年。[10] PM Alberti。关于 C ∗ 代数上的转移概率的注记。Lett. Math. Phys. ,7:25,1983 年。[11] PM Alberti 和 A. Uhlmann。状态空间中的耗散运动。Teubner,莱比锡,1981 年。[12] PM Alberti 和 A. Uhlmann。随机性和偏序:双随机映射和酉混合。Reidel,1982 年。[13] PM Alberti 和 A. Uhlmann。关于 w ∗ -代数上内导出正线性形式之间的 Bures 距离和 ∗ -代数转移概率。应用数学学报,60:1,2000 年。[14] S. Albeverio、K. Chen 和 S.-M. Fei。广义约化标准