XiaoMi-AI文件搜索系统
World File Search SystemClass

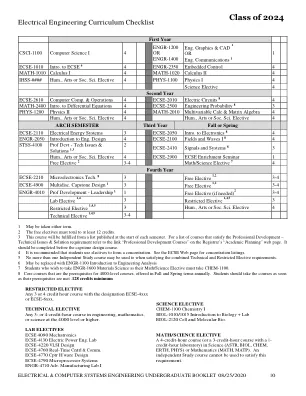
2024级
1可以任一个任期。2免费选修课必须至少达到12个学分。3本课程将从每个学期开始时发布的列表中完成。有关满足专业发展的课程列表 - 技术问题和解决方案要求请参阅注册商“学术计划”网页上的链接“专业发展课程”。它应该在顶峰设计课程之前完成。4建议学生使用选修课来形成集中度。有关集中列表,请参见ECSE网页。5在满足合并的技术和限制选择性要求时,不超过一门独立学习课程。6可以用Engr-1100工程分析简介代替7位希望服用Engr-1600材料科学的学生,因为他们的数学/科学选修课必须服用Chem-1100。8个核心课程是每年秋季和春季提供4000级课程的先决条件。学生应在满足先决条件后立即参加课程。128个学分最低



课程:XII - 经济学
由德里教科书局秘书 Rajesh Kumar 出版,地址:25/2, Institutional Area, Pankha Road, New Delhi-58,印刷地址:Arihant Offcet, New Delhi-110043


'A' 级 - 航空事故
A 类死亡人数/死亡率 财年比较:1/0.29 0/0.00 23 财年死亡人数/死亡率:0/0.00 10 年平均值 (2014 财年-2023 财年) 死亡人数/死亡率:2.20/0.64

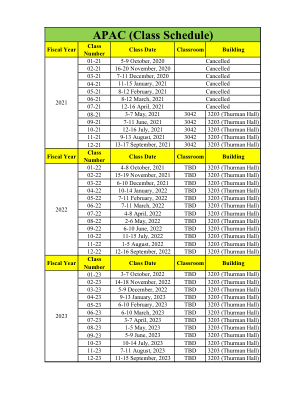
亚太地区(课程表)
01-22 2021 年 10 月 4-8 日 待定 3203(瑟曼大厅) 02-22 2021 年 11 月 15-19 日 待定 3203(瑟曼大厅) 03-22 2021 年 12 月 6-10 日 待定 3203(瑟曼大厅) 04-22 2022 年 1 月 10-14 日 待定 3203(瑟曼大厅) 05-22 2022 年 2 月 7-11 日 待定 3203(瑟曼大厅) 06-22 2022 年 3 月 7-11 日 待定 3203(瑟曼大厅) 07-22 2022 年 4 月 4-8 日 待定 3203(瑟曼大厅) 08-22 2022 年 5 月 2-6 日 待定 3203(瑟曼Hall) 09-22 2022 年 6 月 6-10 日 TBD 3203 (Thurman Hall) 10-22 2022 年 7 月 11-15 日 TBD 3203 (Thurman Hall) 11-22 2022 年 8 月 1-5 日 TBD 3203 (Thurman Hall) 12-22 2022 年 9 月 12-16 日 TBD 3203 (Thurman Hall)
