XiaoMi-AI文件搜索系统
World File Search SystemClassification


实时系统的分类 实时系统的分类 ...
• Brown 和 Campbell (1950):(仅限论文) • 使用实时操作的计算机作为控制系统的一部分。(模拟计算元素) • 第一台专为 R.T.S. 开发的数字计算机用于机载操作。1954 年,数字计算机成功用于自动飞行和武器控制系统。 • 第一个工业计算机安装于 1958 年 9 月,用于路易斯安那州斯特林发电站的工厂监控。 • 第一个工业计算机控制装置由德士古公司制造,该公司于 1959 年 3 月 15 日在德克萨斯州的亚瑟港炼油厂安装了 RW-300 系统 • 第一个 DDC 计算机系统是 Ferranti Argus 200 系统,于 1962 年 11 月在英国兰开夏郡的 ICI 安装。它有 120 个控制回路和 256 个测量值。 • 1974 年微处理器的问世使得经济地使用 DDC 和分布式计算机控制系统成为可能。





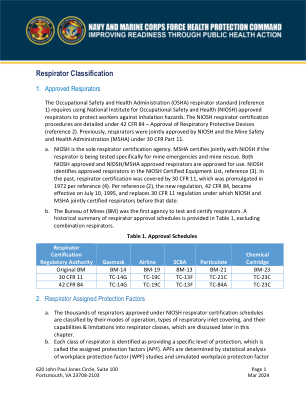
呼吸器分类
(SWPF)研究评估了密封面处呼吸道入口覆盖物(例如面罩)的泄漏量、阀门周围的泄漏量以及通过或围绕滤毒罐或滤毒罐的泄漏量。通过在 WPF 研究和 SWPF 研究期间考虑和测量这些变量的影响,可以估计防护程度并将其与安全系数相结合以分配防护系数。(1)WPF 通过将测得的呼吸器外部工作场所污染物浓度(C out )除以呼吸器内部浓度(C in )来测量呼吸器在工作场所提供的预期防护水平。SWPF 研究与 WPF 类似,但在模拟实验室环境中而不是在工作场所进行测量。(2)APF 表示 C out 与 C in 的最小比率,仅适用于在综合呼吸器计划中使用呼吸器的情况。OSHA 将 APF 定义为“当雇主实施持续有效的呼吸保护计划时,呼吸器或呼吸器类别预计为员工提供的工作场所呼吸保护水平。”附录 A 包含指定保护因素的表。

