XiaoMi-AI文件搜索系统
World File Search SystemCoCo

不23-1787 _____________加文可可,阿佩尔
5上诉人认为“‘[w]在这里。。。这些问题纯粹是合法的,并且审查的成熟是漫长的,``还押在豁免权索赔上是不合适的。'”上诉Br。20(在Re Montgomery Cnty中引用。,215 F.3d 367,374–75(3d Cir。2000));另请参见Oliver诉Roquet,858 F.3d 180,189 n.4,196(3d Cir。2017)(发现被告有权在上诉中获得合格的豁免权,即使地方法院在简易判决阶段没有解决该问题)。值得注意的是,被上诉人引用的案件涉及拒绝简易判决的情况,因此被暗示拒绝了合格的免疫力。鉴于地方法院对被上诉人批准了简易判决,此事涉及有争议的事实问题(不是纯粹的法律问题),因此本案的情况并不完全符合蒙哥马利股份的参数。

分析Nata de Coco
分析Nata de Coco的肿胀特征:质量控制挑战和解决方案的研究Mirza Auly Yahya 1,Amalya Nurul Khairi 1,2*,ABM Heral Uddin 3,Andi Patiware Metareakusuma 4 1食品技术研究计划,工业技术,工业技术,Ahmad dahlan dahlan dahlan dahlan dahlan dahlan dahlan dahlan dahlan dahlan dahlan dahlan jl jl jl j l。艾哈迈德·亚尼(Ahmad Yani),塔玛南(Tamanan),班田(Banguntapan),班尔图尔(Bantulapan),班尔图尔(Bantul),年约会特殊地区,55166,印度尼西亚2艾哈迈德·达兰(Ahmad Dahlan Halal)中心,艾哈迈德·达兰大学(Ahmad Dahlan University),JL。S.H. Soepomo博士,沃格博托,乌姆布拉霍,Yogyakarta特殊地区,55164,印度尼西亚3号制药系,药物科,国际伊斯兰大学马来西亚国际伊斯兰大学马来西亚,马来西亚。 苏丹·艾哈迈德·沙阿(Sultan Ahmad Shah),班达·伊德拉·马哈塔(Bandar Indera Mahkota),库坦(Kuantan),帕汉(Pahang darul Makmur),25200年,马来西亚4人文与自然研究所(Rihn),457-4 Motoyama,Kamigamo,Kamigamo,Kamu-ku,Kamu-Ku,Kamu-ku,Kyoto,Kyoto,603-8047,日本 *,日本 *S.H. Soepomo博士,沃格博托,乌姆布拉霍,Yogyakarta特殊地区,55164,印度尼西亚3号制药系,药物科,国际伊斯兰大学马来西亚国际伊斯兰大学马来西亚,马来西亚。苏丹·艾哈迈德·沙阿(Sultan Ahmad Shah),班达·伊德拉·马哈塔(Bandar Indera Mahkota),库坦(Kuantan),帕汉(Pahang darul Makmur),25200年,马来西亚4人文与自然研究所(Rihn),457-4 Motoyama,Kamigamo,Kamigamo,Kamu-ku,Kamu-Ku,Kamu-ku,Kyoto,Kyoto,603-8047,日本 *,日本 *

Nata De Coco 生物纤维素干燥工艺的潜在用途...
摘要 — 印度尼西亚是世界第二大椰子生产国,其产品之一是椰果,椰果由椰子水通过发酵工艺加工而成。椰果是生物纤维素的一种来源,可用作高级隔音材料的原料。本研究的目的是确定生物纤维素椰果的干燥工艺,以用于隔音的潜在应用,并通过测试水分含量和扫描电子显微镜 (SEM) 分析形成的纤维素纤维。干燥过程在 (95 -100) o C 的温度下进行。在干燥的前 10 分钟内,椰果中遗忘的水蒸气似乎几乎是总水分含量的 ± (30-40)%,即游离水。这是因为椰果样品中所含的游离水含量仍然很大且容易释放,而在干燥的最后阶段,蒸发水分需要很长时间,因为它是结合水。干燥一直进行到获得恒定质量。本研究中平衡含水量 (Me) 的值采用亨德森方程,计算得出的值为 16.430828706902。在干燥结果中发现,干燥产生的生物纤维素椰果含有少量水分,真菌生长的可能性越来越小,从形态学上看生物纤维素可以用作隔音材料,因为它有孔隙和凹痕来容纳传入的声能,因此隔音应用的潜力很大。关键词:椰果、生物纤维素、隔音、吸音系数。1. 引言印度尼西亚是世界上第二大椰子生产国,椰子种植面积为 388 万公顷,如果使用比例为 97%(小农庄园),椰子产量最多可达 320 万吨。 34 年来,椰子种植园从 1980 年的 166 万公顷增加到 2017 年的 389 万公顷(工业部,2010 年)。与斯里兰卡和印度相比,印尼的椰子生产力仍然较低。无论是出口还是国内市场,对椰子制品的需求都在持续增长。椰子衍生产业可以通过多样化加工产品来发展,包括椰果、椰干、初榨油、油脂化学品和椰干。椰果的主要产品除了作为出口材料外,还可以通过多样化椰果衍生产品来利用其他潜力。将椰果中所含的生物纤维素用于生物片材、生物纤维素面膜、生物纤维纸浆和生物纤维粉,为产品多样化和增加出口提供了机会。目前,有很多向发达国家出口生物片材产品、生物纤维素面膜、生物纤维纸浆和生物纤维粉的需求 [10]。生物纤维素是一种由微生物发酵椰子水产生的多糖。椰果或其他使用微生物木醋杆菌的材料,如果将其放入在受控过程中富含氮和碳的椰子水中,它将能够形成椰果纤维。在这种情况下,细菌会产生酶,可以将糖排列成纤维素纤维链。在椰子水中生长的众多微生物中,成千上万的
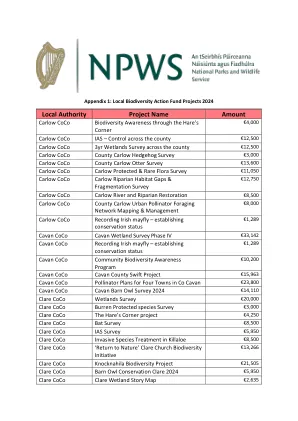
本地生物多样性行动基金项目2024
Cavan CoCo Cavan County Swift Project €15,963 Cavan CoCo Pollinator Plans for Four Towns in Co Cavan €23,800 Cavan CoCo Cavan Barn Owl Survey 2024 €14,110 Clare CoCo Wetlands Survey €20,000 Clare CoCo Burren Protected species Survey €3,000 Clare CoCo The Hare's Corner project €4,250 Clare CoCo Bat Survey €8,500 Clare Coco IAS调查€5,950克莱尔可可入侵物种在基拉洛(Killaloe)€8,500 Clare Coco“回到大自然” Clare Church Biovertity Initiative

金属 - 有机框架的时空设计DUT-8(M)
可切换金属 - 有机框架(MOF)随着时间的流逝而改变其结构,并有选择地打开其吸附的客体分子,从而导致高度选择性的分离,压力扩增,感应和驱动应用。MOF的3D工程已经达到了高水平的成熟度,但是Spatiotem -Poral Evolution通过T-轴设计在第四维(时间)中开辟了一种新的视角,从本质上利用了故意调整激活障碍。这项工作演示了第一个示例,其中可切换MOF(DUT-8,[M 1 M 2(2,6-NDC)2 DABCO] N,2,6- ndc = 2,6- ndc = 2,6-萘二羧酸盐,dabco,dabco = 1,4diazabicyclo [2.2.2] coco coco coco coco coco coco coco coco coco coco coco coco coco,m 1 =时间响应是故意通过钴含量变化来调整的。提出了一系列高级分析方法,用于分析使用蒸气吸附刺激的开关动力学,使用原位时间分辨技术,从集合吸附和先进的同步体X射线X射线衍射实验到单个晶体分析等级。基于微流体通道中各个晶体的显微镜观察的新分析技术揭示了到目前为止报道的吸附切换的最低限制。晶体集合的时空响应的差异源自统计上的诱导时间,并随着钴含量的增加而变化,反映了激活屏障的增加。

1 新型平流层-对流层雷达风...
ST 系统(即为近地至 16 公里以上的系统设计的系统)最常用的天线元件类型是同轴共线 (COCO)。COCO 元件通常是天线罩材料(玻璃纤维或塑料)内部的中心馈电半偶极子阵列,长约 5 米以上,直径约 8 厘米。许多 COCO 以阵列形式设置,通过使用波束转向单元 (BSU),阵列可以指向轴外和垂直方向。始终使用两个相互垂直的 COCO 阵列,因此天线可以指向三个或五个方向(例如,N、E、V 或 N、S、E、W、V)。COCO 阵列的性能相当不错,但也存在一些局限性,包括:1) 大元件尺寸难以在阵列中运输和更换,2) 天线指向方向仅限于 3 或 5 个方向,3) 难以进行幅度锥化,因此旁瓣难以管理,4) 带宽非常窄,因此在传输后会“振铃”(这会阻止低高度数据捕获),5) 它们是专用部件,不一定易于制造,6) 单个 COCO 元件故障会对整个天线波束产生重大影响,7) BSU 使用高功率机械继电器,其磨损时间最短为 18 个月。

(b):Duygu Alpaslan,TubaErşenDudu,Busra Moran Bozer,Nahit Aktas,Mustafa Turk(2025)。由可可>产生的聚(CNO)和聚(CCO)有机粒子
摘要随着癌症病例数量的增加,建议这些病例的解决方案方法也非常重要。在提出的研究范围内,我们旨在通过合成聚(椰子油)(P(CNO))和聚(Cacao Oil)(P(P(CCO))有机粒子从椰子和可可油中开发癌症免疫疗法的替代材料。通过各种表征方法阐明了使用氧化还原聚合技术合成的这些颗粒的结构特征。通过傅立叶变换红外光谱(FT-IR)确定P(CNO)和P(CCO)有机粒子的化学结构和官能团。使用Zetasizer设备的动态光散射(DLS)方法确定有机粒径和Zeta电位值。通过扫描电子显微镜(SEM)确定颗粒的形态特征。生物活性性能。在这项研究中,还研究了P(CNO)和P(CCO)有机粒子对L-929成纤维细胞和CAPAN-1胰腺癌细胞系的细胞毒性和凋亡过程的影响。P(CNO)和P(CCO)有机粒子Capan-1细胞系

引文 Pepe G, Coco R, Corica D, Luppino G, Morabito LA, Lugarà C, Abbate T, Zirilli G, Aversa T, Stagi S 和 Wasniewska M (2024) 内分泌失调
雷特综合征 (RTT;OMIM ID 312750) 是一种严重的神经发育障碍,几乎只发生在女性身上,主要发生在 6 个月大的婴儿身上 ( 1 )。每 15,000 名新生儿中就有 1 名患有此病 ( 2 )。它是继唐氏综合征之后导致女孩智力障碍的第二大遗传病因 ( 3 )。在 90 – 95% 的病例中,甲基-CpG 结合蛋白 2 基因突变是导致大多数典型 RTT 和较小比例非典型 RTT 的原因。另一方面,具有 Rett 表型的患者会同时患有由细胞周期蛋白依赖性蛋白激酶样 5 基因 ( CDKL5 ) 突变引起的早发性癫痫 ( 4 )。另一种称为 FOXG1 的基因与非典型 RTT 或 RTT 样表型有关,并且可能表现出保留的功能和特定的临床特征 ( 5 )。 1999 年,首次描述了甲基-CpG 结合蛋白 2 ( MeCP2 ) 基因突变。MeCP2 基因编码甲基-CpG 结合蛋白 2 ( MeCP2 ),该蛋白与基因的长期沉默有关,并在所有组织中表达 ( 6 )。MeCP2 基因突变主要导致功能丧失,是 RTT(一种影响 X 染色体的疾病)的主要原因 ( 7 )。由于大约 95% 的突变是新生的,因此产前检测和/或 Rett 综合征的遗传咨询通常无济于事。MeCP2 在大脑功能和神经元发育中起着关键作用,无论是在神经元分化开始时还是之后 ( 8 )。RTT 患者一开始看起来都很“健康”。然而,从 6 到 18 个月大的时候,这些儿童会经历早期发育里程碑的退化,运动技能、眼神交流、言语和运动控制能力下降,头部生长减速,并出现明显的重复性、无目的的手部运动 (9)。随着时间的推移,通常会出现一系列神经系统问题,包括焦虑、呼吸问题(呼吸节律失常)和癫痫发作 (10)。RTT 的临床表型高度多变,可分为两大类:典型 (经典) RTT 和非典型 (变异) RTT。典型 RTT 的诊断标准需要一段时间的退化,然后恢复或稳定,并满足所有主要标准(失去有目的的手部技能、失去口语、步态异常和刻板的手部动作)(3)。进一步的表现可以包括自闭症特征、间歇性呼吸异常、自主神经系统功能障碍、心脏异常和睡眠障碍。除了典型或经典的 RTT 外,一些患者可能表现出许多(但不是全部) RTT 临床特征,因此存在“变异型”或“非典型型” RTT(11)。这些包括三种主要变异型:保留言语、早发性癫痫和先天性变异(12)。曲奈肽是目前 FDA 自 2023 年以来批准的唯一一种 RTT 疾病改良疗法,是一种潜在的有效且安全的治疗机会(13)。不同的药物,包括醋酸格拉替雷和右美沙芬,已在小规模临床试验中进行了研究,但效果不显著 ( 14 )。基因疗法目前正处于药物开发阶段,可能带来新的治愈机会 ( 15 )。最初,RTT 被认为是一种纯粹的神经系统病理,但近年来,它已成为一种复杂且


奢侈品领域的数字转换
5 Gabrielle Bonheur Chanel的化名Coco Chanel是法国设计师,他的工作能够彻底改变女性气质的概念,并将自己施加在20世纪的时装设计和流行文化中。创立了以其名字叫Chanel的时装屋。6 Thorstein Bunde Veblen是美国经济学家和社会学家,是经济制度主义的主要指数之一。