机构名称:
¥ 1.0
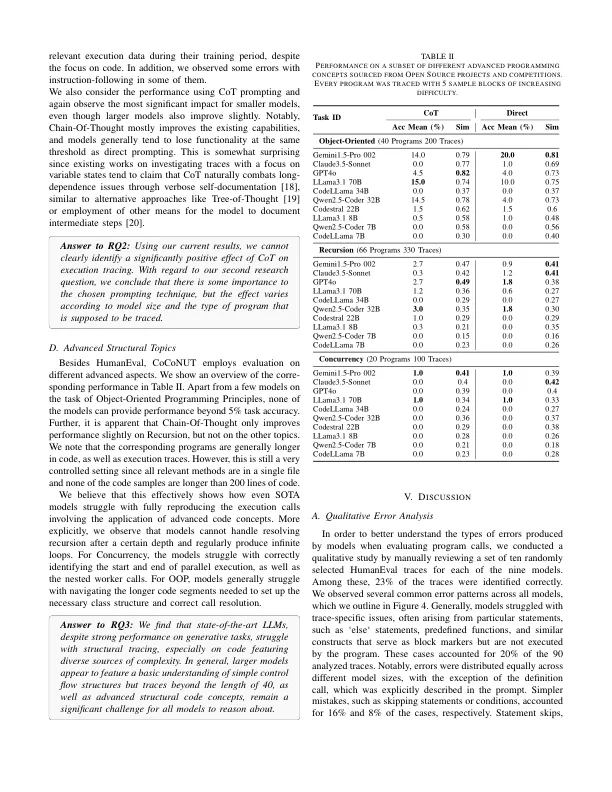
摘要 - LARGE语言模型(LLMS)已显示出涉及结构化和非结构化文本数据的各种任务中的不断表现。最近,LLMS表现出了非凡的能力,可以在不同的编程语言上生成代码。针对代码生成,维修或完成的各种基准测试的最新结果表明,某些模型具有与人类相当甚至超过人类的编程能力。在这项工作中,我们证明了这种基准上的高性能与人类的先天能力理解代码的结构控制流。为此,我们从Hu-Maneval基准测试中提取代码解决方案,相关模型在其上执行非常强烈的执行,并使用从相应的测试集采样的函数调用来追踪其执行路径。使用此数据集,我们研究了7个最先进的LLM与执行跟踪匹配的能力,并发现尽管该模型能够生成语义上相同的代码,但它们仅具有跟踪执行路径的能力有限,尤其是对于更长的轨迹和特定的控制结构。我们发现,即使是表现最佳的模型,Gemini 1.5 Pro只能完全正确地生成47%的人道任务的轨迹。此外,我们引入了一个不在人道主义的三个关键结构的子集,或者仅在有限的范围内包含:递归,并行处理和面向对象的编程原理,包括诸如继承和多态性之类的概念。是oop,我们表明,没有研究的模型在相关痕迹上的平均准确度超过5%。通过无处不在的人道任务进行这些专门的部分,我们介绍了基准椰子:用于导航理解和测试的代码控制流程,该椰子可以衡量模型在相关呼叫(包括高级结构组件)中跟踪代码执行的模型。我们得出的结论是,当前一代LLM仍需要显着改进以增强其代码推理能力。我们希望我们的数据集可以帮助研究人员在不久的将来弥合这一差距。索引术语 - 代码理解,大语言模型,代码执行,基准
椰子:结构代码理解不会从树中掉出来
主要关键词




相关文件推荐