XiaoMi-AI文件搜索系统
World File Search System代码的

教程“基于代码的密码学”
• n = pq 的整数因式分解:如果 n 适合 s 位,则对 2 s + 3 个量子位进行大约 O(s 3 log s)次运算 • 离散对数问题的类似变体也存在 ⇒ 会破坏经典 PKC(RSA、ElGamal……)


对基于代码的密码学的调查
量子技术的改进正在威胁到我们的日常网络安全,因为有能力的量子计算机可能会破坏当前使用的所有不对称加密系统。在为量子时代的量子时代做准备时,国家标准技术研究所(NIST)于2016年启动了公共钥匙加密的标准化过程(PKE)方案,密钥包装机制(KEM)和数字签名方案。在2023年,NIST额外呼吁Quantum后签名。在本章中,我们旨在提供有关基于代码的密码学的调查,重点是PKE和签名方案。我们涵盖了基于代码的密码学中引入的主要框架,并分析了其安全性假设。我们在讲座风格中提供数学背景,目的是吸引更多的受众。
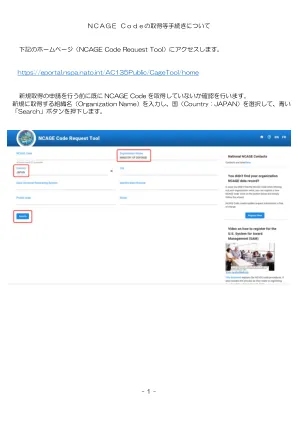
关于获得NCAGE代码的程序
活动类型·商品制造商?* (您是商品制造商吗?) ・商品供应商?* (您是产品销售商吗?) ・服务提供商?* (您是服务提供商吗?) ・公共标准的制定?*(公共标准的制定?) ・政府部门或单位 *(是政府部门或单位吗?) ・军事标准组织 *(是军事标准组织吗?) ・其他(其他)未来业务(未来业务) ・投标邀请函需要 NCAGE 代码吗?*

基于遗传代码的进化 - 保守派...
遗传密码是分子生物学的基础,已经使科学家着迷了数十年。它是将DNA中核苷酸序列转化为形成蛋白质的氨基酸的通用语言。然而,尽管它在生物学中起着至关重要的作用,但遗传密码并不是静态的。它随着时间的流逝而发展,适应环境压力和生物学需求。推动遗传密码演变的关键因素之一是密码子保守变化的概念。这些变化,涉及密码子序列的修改而不改变所得蛋白质,突出了遗传密码的灵活性和适应性。本文解释了遗传密码通过密码子的保守变化,这种进化背后的机制以及对理解生命复杂性的影响而发展的。

稳定器代码的清理引理
因此,具体而言,如果 M 上不支持任何逻辑运算符,则完整的 k 量子比特逻辑 Pauli 群可在其补码上得到支持。如果擦除 M 中的量子比特是一个可纠正错误,则我们说子集 M 是可纠正的。根据稳定器代码的纠错条件,我们可以说,如果 M 是可纠正的,则任何在 M 上支持的 Pauli 运算符要么与稳定器反向交换,要么包含在稳定器中。相反,如果 M 不可纠正,则存在一个在 M 上支持的非平凡 Pauli 运算符,它与稳定器交换但不包含在稳定器中;也就是说,如果 M 不可纠正,则存在一个在 M 上支持的非平凡逻辑运算符。为了证明清理引理,我们按如下方式进行。我们将阿贝尔化的 n 量子比特泡利群 P 视为二进制域 F 2 上的 (2 n ) 维向量空间,并称如果 P 的相应元素可交换,则向量 x 和 y 是正交的。令 PM 表示 P 的子空间,该子空间由 n 个量子比特的子集 M 支撑。令 S 表示 [[ n, k ]] 量子稳定器代码的稳定器。令 [ T ] 表示子空间 T 的维数。我们可以将 S 表示为 S = SM ⊕ SM c ⊕ S ′ 。(3)


连接网络代码的技术帮助...
开发水电项目通常是公共政策的一部分,目的是提高可再生能源产生的能源份额,因此在许多情况下都获得了支持。此支持可以采取多种形式:以投资援助或运营援助形式的直接财政支持(纳税人或 - 企业),保证有助于促进外部资金,转移或租赁土地,获得水资源的机会,建设基础设施,以建造工厂的连接等。国家的任何此类支持都可以作为国家援助,因此必须得到主管国家援助机构的通知,评估和批准。任何这种构成国家援助的措施只有在确保对共同利益目标的积极影响超过其对贸易和竞争的潜在负面影响时,才能获得批准。

人工智能驱动的无代码的比较研究
1。引言人工智能(AI)和机器学习(ML)的整合彻底改变了药物发现和开发领域,利用了计算机科学,数学和物理学的优势。缓慢的营养,巨大的成本和值得注意的失败率Mar传统的药物开发方法。小分子药物的平均开发时间表约为15年,成本超过20亿美元[1]。这些数字已经升级,到2023年开发的新药达到61.6亿美元[2-4]。广泛的反复试验和错误有助于长时间的时间表和高局部负担。AI和ML技术可以显着增强药物发现过程。通过促进虚拟筛查,药物设计和药物靶向相互作用建模,AI可以快速准确地预测生物学能力[5]。ML算法可以分析复杂的生物学数据,包括基因组和蛋白质组学信息,以识别新型的药物靶标和生物标志物[6,7]。这种数据驱动的方法加速了发现过程,改善了治疗的精度和个性化。尽管有这些优势,但AI/ML在药物开发中的应用仍面临与数据质量,算法偏见和模型可解释性有关的挑战[8,9]。ad-

基于代码的假设的有损加密
在2005年推出的错误(LWE)假设[REG05]的学习已成为设计后量子加密术的Baiss。lwe及其结构化变体,例如ring-lwe [lpr10]或ntru [hps98],是构建许多高级加密启示剂的核心GVW15],非交互式零知识[PS19],简洁的论证[CJJ22]以及经典的[GKW17,WZ17,GKW18,LMW23]和量子加密[BCM + 18,MAH18B]的许多其他进步。虽然LWE在产生高级原语方面具有令人惊讶的表现力,但其他量子后的假设,例如与噪音[BFKL94],同基因[COU06,RS06,CLM + 18]和多变量四边形[HAR82]相近的疾病,以前的疾病是指定的,这使得直到直接的指示,这使得Inderiveive of to Inderiveive negripivessive to and Imply to negriptive for nightimivess,量子后密码学。这种状况高度令人满意,因为我们想在假设的假设中有一定的多样性,这意味着对冲针对意外的隐式分析突破。的确,最近的作品[CD23A,MMP + 23,ROB23]使Sidh在多项式时间中经典损坏的Quantum假设曾经是宽松的。这项工作旨在解决可能导致高级量化后加密术的技术和假设方面的停滞。在大多数情况下,这种假设缺乏多功能性可能归因于缺乏利用其他量词后假设的技术。这项工作的重点在于基于代码的加密假设,例如噪声(LPN)假设[BFKL94]及其变体的学习奇偶校验。与噪声的学习奇偶校验认为,被稀疏噪声扰动的随机线性方程(带有种植的秘密解决方案)出现了。即: