XiaoMi-AI文件搜索系统
World File Search SystemConv



LFJR - ANGERS MARCE - dircam
Identi 识别 RNAV CONV 坐标 识别 RNAV CONV 坐标 识别 RNAV CONV 坐标 识别 RNAV CONV 坐标 识别 RNAV CONV 坐标 fi 识别 RNAV CONV 坐标 识别 RNAV CONV 坐标 c 识别 RNAV CONV 坐标 ati 识别 RNAV CONV 坐标 识别 RNAV CONV 坐标 识别 RNAV CONV 坐标 on 识别 RNAV CONV 坐标 识别 RNAV CONV 坐标 识别 RNAV CONV 坐标 识别 RNAV CONV 坐标 识别 RNAV CONV 坐标 识别 RNAV CONV 坐标 识别 RNAV CONV 坐标 C 识别 RNAV CONV 坐标 O 识别 RNAV CONV 坐标 N 识别 RNAV CONV 坐标 V 识别 RNAV CONV 坐标

通过常规T细胞获得抑制功能,限制了Treg Depettion
调节性T(T Reg)细胞有助于免疫稳态,但抑制了对癌症的免疫反应。破坏T Reg细胞介导的癌症免疫抑制的策略已达到有限的临床成功,但是对治疗衰竭的非衍生机制知之甚少。通过对小鼠的T reg细胞靶向免疫疗法进行建模,我们发现CD4 + FOXP3-常规T(T Conv)细胞在耗尽Foxp3 + T Reg细胞时获得抑制功能,从而限制了治疗功效。foxp3 -t conver细胞在消融T reg细胞时采用T型细胞样转录曲线,并获得抑制T细胞激活和增殖的能力。sup-压力活性富含。在T型细胞耗竭后,CCR8 + T CORS细胞会经历全身性和肿瘤内激活和扩张,并介导IL-10-依赖性抑制抗肿瘤免疫。因此,T细胞内IL10的有条件缺失增强了小鼠T型细胞耗竭后的抗肿瘤免疫力,而IL-10信号传导的抗体阻断随着T reg细胞的耗竭协同以克服治疗耐药性。这些发现揭示了T Conv细胞在治疗性T型细胞耗竭后释放的T Cons细胞的二级免疫抑制层,并表明在T细胞谱系中更广泛考虑抑制功能以开发有效的T reg toR taR剂量剂量的治疗疗法。

无线电使用说明书自然资源部...
TGS 区域 A 区域 B 区域 C 区域 D 1 DNR PMCC DNR PMCC NB MA 1 公共 1 2 DNR E - 1 火警控制 NB MA 2 公共 2 3 DNR E – 2 DNR-火警1 NB MA 3 转换 RP1 4 DNR E – 3 DNR-火警2 NB MA 4 转换 RP2 5 DNR E – 4 DNR-火警3 NB MA 5 转换 RP3 6 DNR E – 5 DNR-火警4 NB MA 6 转换 RP4 7 DNR E – 6 DNR-火警5 NB MA 7 事件 1 8 DNR W – 1 空中操作 (n/a) NB MA 8 事件 2 9 DNR W – 2 DNR SX1 (NS) NB MA 9 事件 3 10 DNR W - 3 DNR SX2 NB MA 10 边界 1 11 DNR W - 4 DNR PARKS1 NB MA 11 边界 2 12 DNR W - 5 DNR PARKS2 NB MA 12 GNB SX 1 13 DNR W - 6 BRNCH OP1 NB MA 13 GNB SX 2 14 DNR OPS 1 BRNCH OP2 NB MA 14 SX 全部 1 15 DNR OPS 2 BRNCH OP3 NB MA 15 SX 全部 2 16 DNR OPS 3 BRNCH OP4 NB MA 16 SX 全部 3

一项多机构研究,用于研究小鼠全脑电子闪光后的保留效果:功能,电生理和神经源性终点的可重复性和时间演变
背景和目的:已证明超高剂量率放疗(FLASH)可减轻与常规剂量速率放疗(CORS)相关的正常组织毒性,而不会在临时性模型中损害肿瘤。包括Flash在内的临床前辐射研究中的一个巨大挑战正在验证多个机构的物理剂量法和生物学效应。材料和方法:我们先前使用标准化的幻影和剂量计在单独的机构在单独的机构中证明了两种不同的电子闪存设备的剂量学重复性。在这项研究中,在这两个机构中给出了无肿瘤的成年雌性小鼠的整个脑闪光灯和CORN辐照,并评估了多个神经生物学终点的可重复性和时间演化。结果:在机构之间,在机构之间复制了新型对象识别(射线后4个月)和电生理长期增强(LTP,5个月)的行为表现的闪光释放。在海马神经发生(SOX2,Doublecortin),神经炎症(小胶质细胞激活)和电生理学(LTP)的闪光和CONS之间的差异未在早期(48 h至2周)观察到,但是不成熟的神经元的恢复较大。结论:总而言之,我们证明了具有经过验证的剂量法的两个不同机构的两个不同机构之间对大脑的可再现闪光释放影响。闪光节省效果对评估的端点的效果在稍后但最早的时间点表现出来。

TH06 特点 描述 应用
1. 启动 RH 测量也会自动启动温度测量。总转换时间为 t CONV (RH) + t CONV (T)。 2. 没有转换或正在进行的 I 2 C 事务。典型值在 25 °C 下测量。 3. 上电期间发生一次。持续时间 <5 毫秒。 4. 在执行复位、读/写用户寄存器、读取 EID 和读取固件版本的 I 2 C 命令期间发生。当 I 2 C 时钟速度 >100 kHz(2 字节命令 >200 kHz)时,持续时间 <100 µs。 5. 用户寄存器写入后 IDD。在同一总线上启动任何其他后续 I 2 C 事务(例如用户寄存器读取、启动 RH 测量或指向其他 I 2 C 设备的通信)将使设备转换为待机模式。 6. 启用 HTRE 位时,会产生额外的电流消耗。有关更多信息,请参阅“4.4. 加热器”一节
X -2023
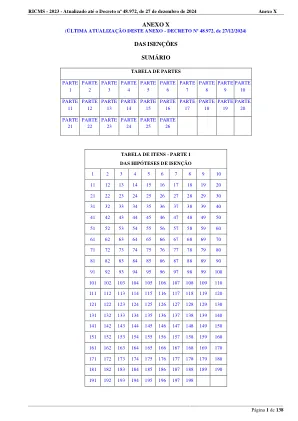
tation 1内部工厂输出操作。12/31/2025 ICMS协议100/97 2以下产品的内部出口操作:12/31/2025 ICMS协议100/97 A)肥沃鸡蛋; b)旨在在农业中独家使用的石灰石或石膏,作为遮瑕膏或土壤恢复器; c)动物粪便。3遗传种子,基本种子,第一代认证种子-C1,第二代认证种子-C2,第一代非认证的种子-S1和第二代非认证的种子-S2,旨在播种,根据认证或监管实体的控制,并与联邦法律的规定相吻合。 10,586,2020年12月18日,以及由农业,牲畜和供应部的器官建立的要求 - MAPA或联邦公共行政,州或联邦区的其他机构和实体,这些机构和实体与该部保持协议。

将 EEGNet 与 SPDNet 相结合,实现端到端……
摘要 — 想象语音是一种心理任务,个人在内部模拟提示的发音而无需实际发声。最近,由于其作为脑机接口 (BCI) 范例的简单性和直观性,它引起了广泛关注。因此,从脑信号中解码想象语音成为一项关键挑战,需要使用文献中记录的各种信号处理和机器学习技术来解决。最常用的神经成像方法是脑电图 (EEG),因为它具有非侵入性、低成本和高时间分辨率。最近从 EEG 信号中解读想象语音的尝试部署了卷积神经网络 (CNN) 架构,例如浅层卷积网络、深度卷积网络和 EEGNet,而其他尝试使用交叉协方差 (CCV) 矩阵作为信号表示的替代形式。我们的新架构将 EEGNet 与 CCV 矩阵相结合,使用 SPDNet 架构中提出的双线性变换从后者中提取判别特征。我们的方法在两个公开可用的数据集上得到了验证,并且表现出与最先进的性能相当的性能,同时大大超越了两个数据集上的 EEGNet 性能。

计算机视觉和深度学习在水下栖息地鱼类分类中的应用:一项调查
图 5 演示了流行的 CNN 架构 UNET(Ronneberger 等人,2015 年)。UNET 的第一个组件是编码器,用于从输入图像中提取特征。第二个组件是解码器,用于输出每个像素的分数。该网络由五个不同的层组成,包括卷积层 (Conv Layer)、整流线性单元 (ReLU)、池化、反卷积层 (DeConv) 和 SoftMax。在这里,DNN 层的任务是只给输入图像中属于鱼身的像素高分,从而得到所示的白色斑点输出,显示鱼的位置