XiaoMi-AI文件搜索系统
World File Search SystemDGX

为以数据中心为中心的企业提供大规模人工智能
为了满足各种工作负载的要求,配备 NVIDIA DGX A100 的 DDN A 3 I 利用了 DDN AI200X、AI400X 和 AI7990X 存储设备。AI200X 和 AI400X 是全 NVMe、完全集成的并行文件存储设备,可为应用程序提供高达 48GB/s 的吞吐量和超过 3M IOPS,甚至可以加速最密集的 I/O 工作负载。AI200X 和 AI400X 经过专门优化,可充分利用 GPU 计算资源,确保最高效率,同时轻松管理艰难的数据操作。AI7990X 是一种混合并行文件存储设备,它将闪存和深度可扩展容量磁盘集成在一个统一的系统中,以实现简单性和灵活性。这种集成使热训练数据和大型库的共置变得容易,同时保持最佳系统效率。AI7990X 的性能优于竞争平台,并为您不断增长的数据库提供容量磁盘的经济性。

Applied Digital 使用 Supermicro AI 服务器
Applied Digital 认为,最适合其用户的系统是 Supermicro SYS- 821GE-TNHR,它配备双第四代英特尔® 至强® 铂金处理器 8462Y+。这些服务器使用 NVIDIA HGX H100 GPU,每个 GPU 配备 80GB 内存。NVIDIA H100 为 HPC 提供 67 万亿次浮点运算的 FP64 Tensor Core 计算,而融合 AI 的 HPC 应用程序可以利用 H100 的 TF32 精度实现单精度矩阵乘法运算的 1 千万亿次浮点运算吞吐量。该系统在计算节点内托管八个 H100 Tensor Core GPU 和 900GB/s NVSwitch,用于 GPU 到 GPU 的通信。Applied Digital 选择 2TB 的系统 RAM 来在转移到 GPU 内存之前暂存工作负载。对于网络,Applied Digital 使用 100GbE 进行带内管理和对象存储,并使用 NDR 结构进行 GPU Direct 和融合闪存文件系统流量。利用 NVIDIA DGX 参考架构,Applied Digital 可扩展到在单个并行计算集群中工作的数千个 H100 GPU。
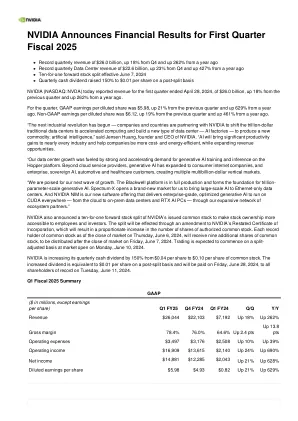
NVIDIA 宣布 2025 财年第一季度财务业绩
第一季度营收创纪录达到 226 亿美元,较上一季度增长 23%,较去年同期增长 427%。推出 NVIDIA Blackwell 平台,推动万亿参数级 AI 计算新时代,以及由 Blackwell 驱动的用于生成式 AI 超级计算的 DGX SuperPOD™。宣布分别用于 InfiniBand 和以太网的 NVIDIA Quantum 和 NVIDIA Spectrum™ X800 系列交换机,针对万亿参数 GPU 计算和 AI 基础架构进行了优化。推出搭载 NVIDIA NIM 推理微服务的 NVIDIA AI Enterprise 5.0,以加速企业应用开发。宣布台积电和新思科技将与 NVIDIA cuLitho 合作投入生产,以加速计算光刻,这是半导体制造业计算最密集的工作负载。宣布全球九台新型超级计算机正在使用 Grace Hopper 超级芯片,开启 AI 超级计算新时代。揭晓 Grace Hopper 超级芯片为 Green500 榜单上全球最节能超级计算机的前三名机器提供动力。扩大与 AWS、Google Cloud、Microsoft 和 Oracle 的合作,以推动生成式 AI 创新。与 Johnson & Johnson MedTech 合作,将 AI 功能引入手术支持。

NVIDIA 医疗保健和生命科学 - Kimberly Powell
除本文所载历史信息外,本演示文稿中的某些事项包括但不限于以下陈述:我们的市场机会;我们的产品和技术的优势、影响、性能、功能和可用性,包括 NVIDIA AI Agent Platform、NVIDIA AI Blueprints、NVIDIA NeMo、NVIDIA NIM、NVIDIA BioNeMo Platform、NVIDIA Clara、NVIDIA DGX、NVIDIA Cosmos、NVIDIA Omniverse、NVIDIA Holoscan、NVIDIA IGX、NVIDIA AI Enterprise Agents 以及 NVIDIA Isacc Robotics 和 AI Instruments;我们与第三方的合作;人工智能革命推动全球行业大幅增长且仍在加速;医疗保健迅速成为一个科技行业;以及每个传感器、每个房间、每家医院都变成机器人,均为前瞻性陈述。这些前瞻性陈述以及本演示文稿中超出历史事实的任何其他前瞻性陈述都受风险和不确定性的影响,这些风险和不确定性可能会导致实际结果大不相同。可能导致实际结果大不相同的重要因素包括:全球经济状况;我们对第三方制造、组装、包装和测试我们产品的依赖;技术发展和竞争的影响;新产品和新技术的开发或现有产品和技术的增强;市场对我们产品或我们合作伙伴产品的接受度;设计、制造或软件缺陷;消费者偏好和需求的变化;行业标准和界面的变化;我们的产品或技术集成到系统中时意外的性能损失和其他因素。

NVIDIA BLUEFIEL-2以太网DPU用户指南
6开始使用Fabric Manager 13 6.1基本组件。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。13 6.1.1面料管理器服务。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。13 6.1.2软件开发套件。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。13 6.2 NVSWWITCH和NVLINK初始化。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。13 6.3支持的平台。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。15 6.3.1硬件体系结构。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。15 6.3.2 NVIDIA服务器体系结构。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。15 6.3.3 OS环境。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。15 6.4支持的部署模型。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。15 6.5其他NVIDIA软件包。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。16 6.6安装。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。基于NVSWWITCH的DGX服务器系统上的16 6.6.1。。。。。。。。。。。。。。。。。。。。。。。。。。。。16 6.6.2在基于NVSWWITCH的NVIDIA HGX服务器系统上。。。。。。。。。。。。。。。。。。。。。16 6.7管理面料管理器服务。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。17 6.7.1启动面料管理器。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。17 6.7.2停止面料管理器。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。17 6.7.3检查面料管理器状态。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。18 6.7.4启用Fabric Manager服务以自动启动。。。。。。。。。。。。。。。。。18 6.7.5禁用Fabric Manager服务自动启动在启动时。。。。。。。。。。。。。。。。。。18 6.7.6检查面料管理器系统日志消息。。。。。。。。。。。。。。。。。。。。。。。。18 6.8 Fabric Manager启动选项。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。18 6.9 Fabric Manager服务文件。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。基于Linux的系统上的19 6.9.1。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。19 6.10运行织物管理器作为非根。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。20 6.11 Fabric Manager配置选项。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。21 6.11.1记录相关的配置项目。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。21 6.11.1.1设置日志文件位置和名称。。。。。。。。。。。。。。。。。。。。。。。。。21 6.11.1.2设置所需的日志级别。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。21 6.11.1.3设置日志文件附加行为。。。。。。。。。。。。。。。。。。。。。。。。。。。。。22 6.11.1.4设置日志文件大小。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。22 6.11.1.5将日志重定向到Syslog。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。22 6.11.1.6旋转设置。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。22 6.11.2操作模式相关的配置项目。。。。。。。。。。。。。。。。。。。。。。。。。。。。。23

丰田,Aurora和Continental加入NVIDIA合作伙伴的成长名单,将下一代高度自动化和自动驾驶汽车舰队
本新闻稿中的某些陈述包括但不限于:NVIDIA产品,服务和技术的好处,影响和性能,包括NVIDIA加速计算和AI,NVIDIA DRIVE AGX ORIN,NVIDIA DRIVEOS操作系统; NVIDIA CUDA AV平台,NVIDIA DRIVE ORIN,NVIDIA DGX系统,Nvidia Omniverse平台和NVIDIA OVX系统; Nvidia Cosmos,第三方使用或采用NVIDIA的产品和技术,收益和影响以及其产品的功能,性能和可用性;汽车是最大的AI和机器人行业之一; NVIDIA带来了二十年的汽车计算,安全专业知识及其CUDA AV平台来转变数万亿美元的汽车行业,这是前瞻性陈述,这些陈述受风险和不确定性的影响,可能会导致结果与期望实质上不同。向SEC提交的报告的副本已发布在公司网站上,可在NVIDIA上免费获得。这些前瞻性陈述不能保证未来的绩效,并且仅在此日期开始说话,除了法律要求外,Nvidia违反了更新这些前瞻性陈述以反映未来事件或情况的任何义务。可能导致实际结果差异的重要因素包括:全球经济状况;我们依靠第三方制造,组装,包装和测试我们的产品;技术发展和竞争的影响;开发新产品和技术或对我们现有产品和技术的增强;市场接受我们的产品或合作伙伴的产品;设计,制造或软件缺陷;消费者偏好或需求的变化;行业标准和界面的变化;集成到系统中时,我们的产品或技术的性能意外丧失;以及其他因素不时详细介绍了与美国证券交易委员会(SEC)或SEC的NVIDIA文件中详细介绍的,包括但不限于其表格10-K和表格10-Q的季度报告的年度报告。

Nvidia Corporation 2024年股东年会...
问:您能否讨论NVIDIA维持其竞争优势的策略?您对行业中其他玩家开发竞争产品的威胁有何看法?A:我们对这个问题的回答出现在2024年年度会议广播中的25:30。问:NVIDIA的量子计算开发计划是什么?A:我们对这个问题的回答出现在2024年年度会议广播中的27:19。问:公司的多元化策略是什么,特别是进入制药行业的?A:我们对这个问题的回答出现在2024年年度会议广播中的28:33。问:您能谈谈我们解决当前半导体供应链挑战的策略吗?NVIDIA如何确保为客户提供稳定的半导体供应?A:我们对这个问题的回答出现在2024年年度会议广播中的30:47。问:NVIDIA在确保人工智能具有适当的护栏方面做了什么?A:我们对这个问题的回答出现在2024年年度会议广播中的31:26。问:您能谈谈公司对公司可持续性事务的方法,包括多样性和气候变化吗?A:我们对这个问题的回答出现在2024年年度会议广播中的32:40。问:您能谈谈新兴的液体神经网络技术以及它如何影响现有的AI模型和您的业务?A:加速计算使工程师和科学家能够发明未来。我们喜欢看到建立和开发AI的新颖和创新的方法。问:请讨论Nvidia与主权AI有关的努力。A:主权AI是指一个国家或土著社区使用其自己的基础设施,数据,劳动力和商业网络生产人工智能的能力。国家和土著社区正在通过各种模型来建立国内计算能力。例如,日本计划投资关键的数字基础设施提供商,包括KDDI,Sakura Internet和Softbank,以建立美国主权AI基础架构。ILIAD集团的子公司总部位于法国的Scaleway正在建立欧洲最强大的云本地AI超级计算机。 在意大利,瑞士郡集团将建立该国的第一个也是最强大的NVIDIA DGX驱动的超级计算机,以开发以意大利语为单位的第一个LLM。 和在新加坡,国家超级计算中心正在使用Nvidia Hopper GPU升级,而Singtel正在东南亚的NVIDIA加速AI工厂。 Nvidia Inception公司 te hiku Media已成功地创建了从长者和其他社区成员收集的毛利语LLM和定制数据集。 te hiku正在扩大这一成功,并计划为土著社区和新西兰研究人员建立一个数据中心,以结合政府资金和私人投资来培训AI模型。 NVIDIA提供端到端的计算到网络技术,全栈软件,AI专业知识以及丰富的合作伙伴和客户生态系统的能力,允许主权AI和区域云提供商启动其国家的AI抱负。ILIAD集团的子公司总部位于法国的Scaleway正在建立欧洲最强大的云本地AI超级计算机。在意大利,瑞士郡集团将建立该国的第一个也是最强大的NVIDIA DGX驱动的超级计算机,以开发以意大利语为单位的第一个LLM。和在新加坡,国家超级计算中心正在使用Nvidia Hopper GPU升级,而Singtel正在东南亚的NVIDIA加速AI工厂。te hiku Media已成功地创建了从长者和其他社区成员收集的毛利语LLM和定制数据集。te hiku正在扩大这一成功,并计划为土著社区和新西兰研究人员建立一个数据中心,以结合政府资金和私人投资来培训AI模型。NVIDIA提供端到端的计算到网络技术,全栈软件,AI专业知识以及丰富的合作伙伴和客户生态系统的能力,允许主权AI和区域云提供商启动其国家的AI抱负。

机器人工厂将工业数字化作为电子制造商采用Nvidia AI和Omniverse
本新闻稿中的某些陈述包括但不限于:我们的产品,服务和技术的好处,影响,性能和可用性,包括Nvidia Metropolis Vision AI,Nvidia Omniverse,Nvidia Isaac AI Isaac AI机器人,NVIDIA ISAAC iSAAC iSAAC PECTERPERS ACCELOR ACCELORIAS ISAAC ISAAC MANIPIA ISAAAC MANIPIA ISAAAC MANIPIA ISAAAC ISAAIA ia vidia Isaaia Isaaia ia aacia ia aacia aaac ia aacia aaac ia aaac ia aacia aaac ia aacia ia vilulator, NVIDIA NEMO,NVIDIA NIM,NVIDIA DGX和NVIDIA HGX服务器和NVIDIA HGX系统;第三方使用并采用我们的技术和产品,我们与第三方的合作以及其优势和影响以及其产品的功能,性能和可用性;由于生成AI和数字双胞胎技术的变革影响,每个工厂都变得越来越自治。借助Nvidia Omniverse,Metropolis和Isaac,工业生态系统能够加速其对自主技术的采用,帮助他们提高运营效率和较低的成本,而前瞻性陈述是受风险和不确定性的影响,可能会导致结果与预期产生重大不同。向SEC提交的报告的副本已发布在公司网站上,可在NVIDIA上免费获得。这些前瞻性陈述不能保证未来的表现,并且仅在此日期开始说话,除了法律要求外,Nvidia违反了更新这些前瞻性陈述以反映未来事件或情况的任何义务。可能导致实际结果差异的重要因素包括:全球经济状况;我们依靠第三方制造,组装,包装和测试我们的产品;技术发展和竞争的影响;开发新产品和技术或对我们现有产品和技术的增强;市场接受我们的产品或合作伙伴的产品;设计,制造或软件缺陷;消费者偏好或需求的变化;行业标准和界面的变化;集成到系统中时,我们的产品或技术的性能意外丧失;以及其他因素不时详细介绍了与美国证券交易委员会(SEC)或SEC的NVIDIA文件中详细介绍的,包括但不限于其表格10-K和表格10-Q的季度报告的年度报告。

NVIDIA A100 Tensor Core GPU 架构
图 1. 现代云数据中心工作负载需要 NVIDIA GPU 加速 .......................................................... 8 图 2. NVIDIA A100 中的新技术.................................................................................... 10 图 3. 新 SXM4 模块上的 NVIDIA A100 GPU ........................................................................ 12 图 4. 用于 BERT-LARGE 训练和推理的统一 AI 加速 ............................................................. 13 图 5. 与 NVIDIA Tesla V100 相比,A100 GPU HPC 应用程序加速 ............................................. 14 图 6. 带有 128 个 SM 的 GA100 全 GPU(A100 Tensor Core GPU 有 108 个 SM) ............................................................................................. 20 图 7. GA100 流多处理器 (SM) ............................................................................................. 22 图 8. A100 与 V100 Tensor Core 操作 ............................................................................................. 25 图 9. TensorFloat-32 (TF32) ........................................................................................... 27 图 10. 迭代TCAIRS 求解器收敛到 FP64 精度所需的时间 .............................................. 30 图 11. TCAIRS 求解器相对于基线 FP64 直接求解器的加速 ........................................................ 30 图 12. A100 细粒度结构化稀疏性 ...................................................................................... 32 图 13. 密集 MMA 和稀疏 MMA 操作示例 ............................................................................. 33 图 14. A100 Tensor Core 吞吐量和效率 ............................................................................. 39 图 15. A100 SM 数据移动效率 ............................................................................................. 40 图 16. A100 L2 缓存驻留控制 ............................................................................................. 41 图 17. A100 计算数据压缩 ............................................................................................. 41 图 18. A100 强扩展创新 ............................................................................................. 42 图 19. Pascal 中基于软件的 MPS 与硬件加速的 MPS Volta............. 44 图 20. 当今的 CSP 多用户节点 ...................................................................................... 46 图 21. 示例 CSP MIG 配置 .............................................................................................. 47 图 22. 具有三个 GPU 实例的示例 MIG 计算配置。 ...................................................... 48 图 23. 具有多个独立 GPU 计算工作负载的 MIG 配置 ...................................................... 49 图 24. 示例 MIG 分区过程 ............................................................................................. 50 图 25. 具有三个 GPU 实例和四个计算实例的示例 MIG 配置。 .................... 51 图 26. 带有八个 A100 GPU 的 NVIDIA DGX A100............................................................. 53 图 27. 光流和立体视差的说明 .................................................................................... 55 图 28.顺序 2us 内核的执行细分。................................................................ 59 图 29. 任务图加速对 CPU 启动延迟的影响 .............................................................. 60