XiaoMi-AI文件搜索系统
World File Search SystemLingua

LINGUA FRANCA-IV - 班加罗尔城市大学
Rajaram 博士 Ayesha Firdose 女士 副教授 副教授 英语系 英语系 圣约瑟夫商学院 Vijaya 学院,Jayanagara 班加罗尔-560095 班加罗尔-560011 P. Sartaj Khan 博士 Padmavathy. K 博士 副教授兼系主任 教授兼英语系主任 英语系 Al-Ameen 艺术,信德学院 科学与商业学院 班加罗尔-560024 班加罗尔-560027 R.V. Sheela 博士 Leena Karanth 女士 副教授兼系主任 副教授兼英语系主任 英语系

符号作为弥合人机鸿沟的通用语言,用于可解释和可建议的人工智能系统
尽管许多现代人工智能系统通常能够学习自己的表征,拥有令人惊讶的强大功能,但人们对它们的不可捉摸性以及与人类互动能力随之而来的问题感到非常不满。虽然已经提出了神经符号方法等替代方案,但对于这些方法的具体内容缺乏共识。通常有两个独立的动机:(i) 符号作为人机交互的通用语言;(ii) 符号作为人工智能系统在其内部推理中使用的系统生成的抽象。关于人工智能系统是否需要在其内部推理中使用符号来实现一般智能能力,目前尚无定论。无论答案是什么,人机交互中对(人类可理解的)符号的需求似乎非常引人注目。符号,就像情绪一样,可能不是智能本身的必要条件,但它们对于人工智能系统与人类互动至关重要——因为我们既不能关闭我们的情绪,也不能没有我们的符号。特别是在许多人为设计的领域,人类会对提供明确的(符号)知识和建议感兴趣——并期望机器以同样的方式进行解释。仅此一点就要求人工智能系统维护一个符号界面以便与人类互动。在这篇蓝天论文中,我们论证了这一观点,并讨论了需要追求的研究方向,以实现这种类型的人机互动。

填写工作申请表的说明(...
学历要求:在工作申请中详细列出与所学专业相关的所有信息,特别是如果这些信息对于资格具有决定性作用,否则将被排除在外。除在美国获得的资格外,在非欧洲国家获得的资格必须经过专门负责外国资格等效的主管部门的评估。外语文件必须正式翻译成英语或意大利语。 “研究生院或大学水平的教育”是指获得理学学士学位或同等学历以上的大学学习。

海洋图像分析的新互动机器学习工具
进步的成像技术大大提高了海洋视频和图像数据收集的速度。通常不会分析这些数据集的全部潜力,因为为多种物种提取信息非常耗时。这项研究证明了开源交互式机器学习工具Rootpainter的能力,可以快速准确地分析大型海洋图像数据集。在两个数据集中测试了根蛋白酶提取冷水珊瑚礁关联物种mycale Lingua的存在和表面积的能力:18 346个延时图像和1420个远程操作的车辆视频框架。与rootpainter集成的新纠正注释指标允许对何时停止模型训练并减少对手动模型验证的需求进行客观评估。使用Rootpainter创建了三个高度精确的M. Lingua模型,平均骰子得分为0.94±0.06。转移学习有助于两个模型的产生,将分析效率从6倍提高到16倍,比手动注释的延时图像快6倍。从两个数据集中提取表面积测量值,从而将来研究海绵行为和分布。向前迈进,交互式机器学习工具和模型共享可以大大提高图像分析速度,协作研究以及我们对生物多样性中时空模式的理解。

Kyle GormanKyle Gorman
Reviewer for ICASSP, INTERSPEECH, LREC, SCiL, the National Science Foundation, the Natural Sciences and Engineering Research Council of Canada, Oxford University Press, Biolinguistics , Cognition , Cognitive Science , Computational Linguistics , Glossa , Journal of Child Language , Journal of Linguistics , Journal of Autism & De- velopmental Disorders , Language , Language Variation & Change , Lingua , Nature Communication , Phonology , PLOS ONE , and计算语言学协会的交易。
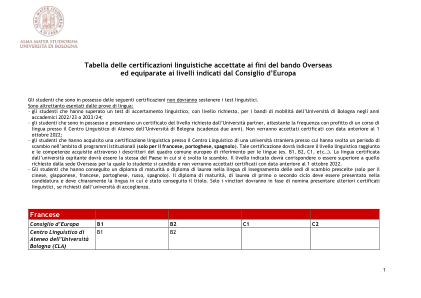
海外通话可接受的语言证明表
机构项目内的交流(仅适用于法语、葡萄牙语、西班牙语)。该认证必须表明通过欧洲共同语言参考框架的描述符所达到的语言水平和获得的技能(例如B1、B2、C1 等...)。主办大学认证的语言必须与交流所在国家的语言相同。所示级别必须符合或高于学生申请的海外机构的要求,且日期为 2022 年 10 月 1 日之前的证书将不被接受- 已获得所选交换地点教学语言的高中文凭或学士学位的学生(仅适用于

使用合作伙伴阅读策略对MAS YP的园艺博览会文本的英语阅读理解成就的影响。 haji datuk
教育过程从未与人类与人类生活和文化环境的沟通分离。在印度尼西亚社会的生活中,互动肯定是单独发生的,或者是在群体中发生的,社会化的过程与与社会系统有关的文化学习过程涉及(Darma&Joebagio,2018年)。英语是世界上最重要的外语,被用作国际语言。根据(Errington,2006)。作为一种全球语言,很明显,英语在国际互动中起着重要作用。国际互动包括国家之间的经济关系,国际业务关系,全球贸易等。词汇是英语教学学习的重要方面之一。另一个方面是,老师必须在寻找,选择和简化使学生掌握词汇的材料方面具有创造力和耐心,换句话说,学习词汇学生的语言技能会遇到麻烦(Sugiarti,2022年)。在这种国际互动中,英语主要充当全球语言。通用语言是一种语言,用于与来自不同国家的不同人群进行交流。

考试面试流程
考试面试轨道 2020 年 5 月 6 日下午 3 点,根据 2020 年 5 月 14 日第 131 号指导决定任命的遴选委员会根据 2020 年 3 月 17 日第 18 号立法法令第 1 条规定的程序,通过视频会议召开会议。 87,c. 5 以及在《官方公报》第 4 号特别系列竞赛和考试中发布的通知中宣布的有关在线竞争性选拔、进行面试以及相关竞赛的英语语言和基础 IT 测试的新的 CREA 规定。 2020 年 4 月 3 日第 27 号。面试过程中,委员会决定初步对每位候选人进行一次英文阅读、翻译和理解测试,测试内容是竞赛主题,具体是2020年出版的两部科学著作的摘要:

