
机构名称:
¥ 3.0
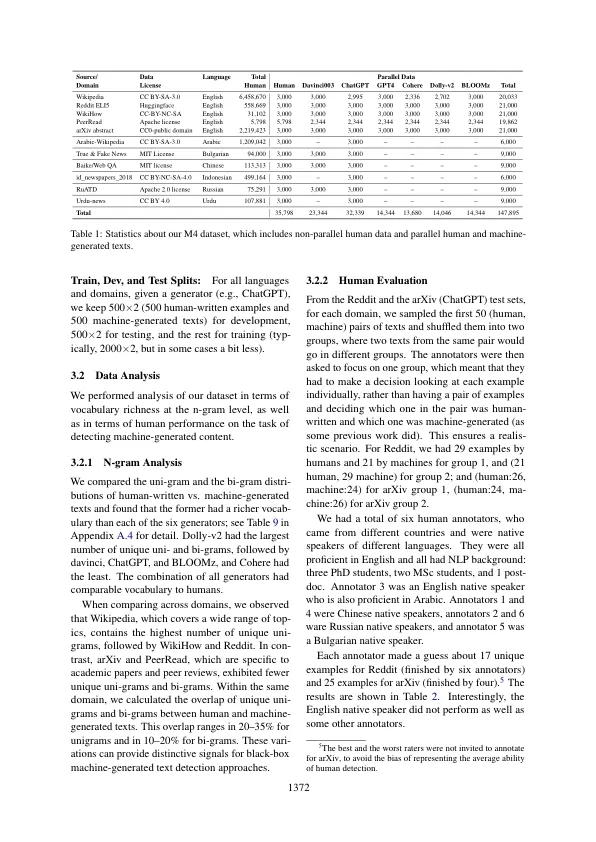
大型语言模型 (LLM) 已展示出对各种用户查询生成流畅响应的卓越能力。然而,这也引发了人们对此类文本在新闻、教育和学术界可能被滥用的担忧。在本研究中,我们致力于创建能够检测机器生成文本并查明潜在滥用的自动化系统。我们首先介绍一个大规模基准 M4,它是一个用于机器生成文本检测的多生成器、多领域和多语言语料库。通过对该数据集的广泛实证研究,我们表明检测器很难很好地概括来自看不见的领域或 LLM 的实例。在这种情况下,检测器往往会将机器生成的文本错误地归类为人类编写的。这些结果表明问题远未解决,还有很大的改进空间。我们相信,我们的数据集将使未来的研究能够更稳健地解决这一紧迫的社会问题。该数据集可在https://github.com/mbzuai-nlp/M4获得。
M4:多生成器、多领域、多语言黑色...
主要关键词




相关文件推荐





























