XiaoMi-AI文件搜索系统
World File Search SystemMOFA

卡塔尔及其合作伙伴致力于加沙停火:外交部
卡塔尔外交部发言人马吉德·本·穆罕默德·安萨里博士昨天表示,卡塔尔一直在“通过各种方式和手段”继续努力,以达成加沙地带停火协议。安萨里博士在外交部组织的每周新闻发布会上强调,所有调解人(卡塔尔、美国和埃及)都在为结束加沙战争做出巨大努力。关于正在进行的多哈间接谈判,安萨里博士强调,无论是在多哈还是在开罗,谈判都是在技术层面上进行的。关于叙利亚问题,安萨里博士表示,卡塔尔欢迎美国政府决定暂停对叙利亚的一些制裁,并希望这些制裁能够彻底、永久地解除。他说:“我们欢迎美国暂停对叙利亚的部分制裁,这是部分举措”,希望永久解除制裁,促进经济周期。关于卡塔尔在此背景下的作用,他表示,地区普遍致力于解除对叙利亚的制裁,卡塔尔的努力是这一地区努力的一部分。安萨里博士指出,有关卡塔尔天然气运往叙利亚的报道是媒体的猜测,强调该国现阶段的重点是向叙利亚人民提供人道主义援助。他说,卡塔尔致力于从人道主义和技术支持两个方面支持叙利亚人民。他提到了外交部国务部长穆罕默德·本·阿卜杜勒阿齐兹·本·萨利赫·阿尔·胡莱菲博士阁下在叙利亚代表团访问多哈期间所作的声明,以及他昨天确认继续开通空中桥梁并恢复飞往叙利亚国际机场的航班。

召开行业战略审查会议
这是 2023 年 10 月举行的私营部门发展成果衡量高级培训研讨会上开发的几种学习产品之一。感谢企业发展捐助委员会 (DCED)、荷兰外交部 (MoFA) 和瑞士发展与合作署 (SDC) 赞助研讨会和由此产生的出版物。非常感谢 PRISMA 团队向我们提供信息并允许我们在此简报和研讨会期间使用他们的案例。PRISMA 是澳大利亚政府和印度尼西亚政府 (Bappenas) 之间的发展伙伴关系。还要感谢 Alexandra Miehlbradt 和 Nabanita Sen Bekkers 的宝贵意见和反馈。最后,感谢 Isabelle Gore 的编辑和 Anne Metcalfe 的简报平面设计。照片由 Freepik 上的 pressfoto 拍摄。

日本政府与美国加利福尼亚州关于加强应对气候变化及经贸关系的合作备忘录
为跟进本谅解备忘录的实施,日方指定外务省(MOFA)、经济产业省(METI)、国土交通省(MLIT)、环境省(MOE)、日本贸易振兴机构(JETRO)、日本国家旅游局(INTO)和日本驻旧金山总领事馆,加州方面指定加州州长商务经济发展办公室(GO Biz)、加州环境保护局(CalEPA)和加州交通局(CalSTA)。上述机构将酌情协调本谅解备忘录的实施以及日美两国实体之间的其他承诺,并在双方均可接受的时间以面对面、视频或电话会议的方式举行会议。


朝鲜利用社会工程学实现黑客攻击……
美国联邦调查局 (FBI)、美国国务院和国家安全局 (NSA) 以及韩国国家情报局 (NIS)、国家警察厅 (NPA) 和外交部 (MOFA) 联合发布此通报,强调朝鲜民主主义人民共和国 (DPRK,又名朝鲜) 受国家支持的网络行为者使用社会工程学在全球范围内针对研究中心和智库、学术机构和新闻媒体组织雇用的个人进行计算机网络攻击 (CNE)。众所周知,这些朝鲜网络行为者会冒充真正的记者、学者或其他与朝鲜政策圈有可靠联系的个人进行鱼叉式网络钓鱼活动。朝鲜利用社会工程学非法获取目标的私人文件、研究和通信,收集有关地缘政治事件、外交政策战略和影响其利益的外交努力的情报。
CG投票报告
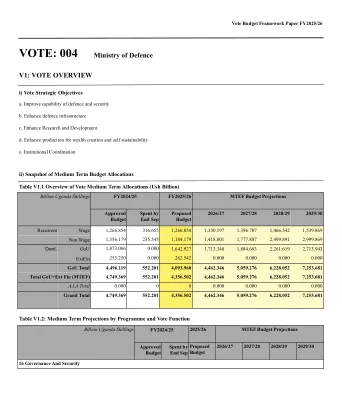
该部将确保; (1)乌干达国防与退伍军人政策中的承诺,2023年。(2)实施UPDF(修订)法案的规定,2024(3)继续实施退伍军人的重新融合和安置计划。(4)继续简化养老金和小费管理系统。(5)操作MODVA性别和权益政策,2024。(6)该部第三战略计划的最终期审。(7)根据NDP IV制定该部的第四个战略计划。(8)升级集成资源管理信息系统(IRMI),包括物流管理信息系统(LMIS)(9)继续实施UPDF机构,2021。(10)继续采取法律,行政和结构措施,以增强国防外交。(11)继续获取土地和现有updf土地的名称。(12)继续与OP,MIA,Maaif,Mofa,Meaca,NFA,UWA,URA,NEMA,NEMA,NIRA,UPF,UPS等合作。(13)财务和审计报告2024/25财年。(14)在Karamoja综合开发计划中实施MODVA承诺。(15)审查车队管理政策(16)进行人力资源管理(17)加强资产的采购和处置(18)进行公共和媒体参与

UIA战略计划2020-2025-最终版本
AfCFTA African Continental Free Trade Area BoU Bank of Uganda CCPIT China Council for the Promotion of International Trade CIEA Composite Index of Economic Activity CRM Customer Relationship Management CWUR Centre for World University Ranking DCI Directorate of Citizenship and Immigration DI Domestic Investment DDI Domestic Direct Investment DIC District Investment Committee DLG District Local Government DLR Directorate of Lands Registry DRC Democratic Republic of Congo EAC East African Community EGS经济增长策略EY ERNEST和FIA FIA金融情报局FDI外国直接投资FY金融年份GDP国内生产总值GERD GROSS GROSS GROSS RESS GROSS REASS OR on RENIGHTION GU GROSS of of UGANDA的gu gdp gdp gdp gdp gdp gdp gdp gdp gdp gdp gdp总额 INOY Investor of the Year KCCA Kampala Capital City Authority KIBP Kampala Industrial Business Park MDAs Ministries, Departments and Agencies M & E Monitoring and Evaluation MoFA Ministry of Foreign Affairs MFPED Ministry of Finance, Planning and Economic Development MoICTNG Ministry of Information Communication Technology and National Guidance MoPS Ministry of Public Service MTEF Medium Term Expenditure Framework MTIC Ministry of Trade, Industry and Cooperatives NDP National Development计划

1 加纳电子农业的成功因素
数字技术的生产潜力已在经济的各个部门得到充分体现,并在电子农业推广(也称为电子推广)中得到体现。电子推广被认为有望解决农业部门面临的通信和推广挑战。加纳政府通过粮食和农业部、世界银行和粮食及农业组织 (FOA) 都建议并支持加纳的电子推广举措。世界信息社会峰会 (WSIS) 2010 行动计划将电子农业列为信息通信技术在提高农业生产力方面的一种应用。围绕信息通信技术和农业的新兴讨论也以研究证据为背景,即广播仍然是加纳农民获取农业信息的最常用方式。因此,本研究重点关注加纳在电子农业方面的经验,以探讨应用这一概念的机遇和挑战。本文使用私营部门计划 Cowtribe 和政府电子推广来研究定义加纳电子推广计划成功因素的原则。采用案例研究方法和关键人物访谈,结果表明,尽管农业部电子推广计划在有效接触农民方面面临挑战,但 Cowtribe 代表了加纳电子农业推广的进步和成功案例,它分别向农民和其他价值链参与者提供有关牲畜管理和农业市场数据服务的重要和及时信息。研究结果有望为在农业推广中使用 ICT 的机遇和挑战提供理论见解。