XiaoMi-AI文件搜索系统
World File Search SystemOb


gutjnl-2019-319726.full.pdf
抽象目标已提出肠道菌群作为代谢性疾病的有趣治疗靶点。inulin作为益生元已被证明可减少肥胖症和相关疾病。当前研究的目的是研究干预前的肠道菌群特征是否决定了对肌蛋白的生理反应。设计来自四个肥胖供体的粪便在饮食干预之前被取样,并在饮食干预之前采样,并接种抗生素预处理的小鼠(Hum-ob小鼠;人类化的肥胖小鼠)。hum-ob小鼠用高脂饮食喂食,并用菊粉治疗。代谢和微生物群在hum-ob小鼠中的毒素治疗变化与在补充二氨基蛋白的肥胖个体中获得的hum-ob小鼠的变化进行了比较。结果我们表明,与来自不同肥胖个体的粪便菌群定居的Hum-ob小鼠在高脂饮食中对补充肌蛋白的补充有所不同。在几个细菌属中,巴氏菌,双毛虫,丁酸酯,维多瓦利斯,Xiva梭状芽胞杆菌,Akkermansi A,Raoultella和Blautia与观察到的代谢结果(肥胖和肝片的降低)相关。此外,在肥胖的个体中,anaerostipes,akkermansia和丁酸酯的干预前水平驱动了响应于肌蛋白的体重指数的减少。结论这些发现支持在益生元进行营养干预之前表征肠道微生物群,对于在肥胖和代谢性疾病的背景下增加积极结果很重要。

摘要PDF海报
摘要:前连合(AC)是一束轴突,它们在嗅觉区域(例如嗅球(OB),前嗅觉核(AON)和梨状皮层(PC)等嗅觉区域之间交流,在嗅觉区域之间进行交流。以前,我们报道说,AC的发展是一个高度调节的过程,涉及渐进式和回归的增长策略,在E17胚胎开发结束时达到对侧。同时,对侧结构中的树博化延迟到产后3-5天。在这里,我们使用与EGFP或MCHERRY转导的腺相关病毒(AAVS)向量,我们在OB,AON和PC中注入了嗅觉区域,以研究穿过AC的对侧神经支配场。我们发现,来自OB的对侧轴突仅穿过AC的前肢,以投射到颗粒细胞层(GCL)中。相比之下,轴突源自前PC项目,进入对侧OB,AON和PC。这些轴突不仅将其释放到GCL中,还可以伸入二尖瓣和外部丛状层,以及前PC层1B。,我们通过AC的后肢专门观察到后PC项目,专门于对侧PC,从1B层进行了根本性的塑造。内一核核仅通过AC的后肢向后PC进行。共同展示了嗅觉结构中对侧树博化的详细图,这对于理解脑半球之间嗅觉信息的处理至关重要。
磷酸化蛋白质组学分析揭示了人类骨髓衍生的基质干细胞的成骨细胞谱系的定义遗传程序
骨髓 - 衍生的间充质干细胞(MSC)在其小众中存在的信号刺激后分化为成骨细胞。由于与MSC的成骨细胞(OB)分化相关的全局信号传导级联反应没有很好地定义,因此我们使用定量质谱法来描述人类MSC蛋白质组和磷酸化型的变化。6252蛋白和15,059个磷光位点的时间曲线表明至少两个不同的信号传导波:刺激后30至60分钟内的一个峰值在30至60分钟内峰值,在24小时后进行了第二次升高。除了在早期MSC分化过程中提供蛋白质组和磷酸蛋白质组动力学的全面视图外,我们的分析还确定了丝氨酸/苏氨酸蛋白激酶D1(PRKD1)在OBS中的关键作用。在OB分化开始时,PRKD1通过触发组蛋白脱乙酰基酶HDAC7的磷酸化和核排除来启动促稳态转录因子Runx2的激活。

教师奖日
2011年,贝尔福特博士被任命为贝勒部门的主席,以及德克萨斯州儿童教育部的首席OB/ Gyn。 他的主要目标之一是进一步贝勒在非洲的医疗保健领域,以解决孕产妇和新生儿死亡率以及产科瘘管。 他为我们在马拉维的教师所做的巨大工作以及这些医生和助产士所做的结果感到自豪。 在25区域的设施中,孕产妇死亡率降低了70%,新生儿死亡率已降低到几乎为零。 Baylor负责制定一项专业培训计划,该计划的培训量增加了三倍,使Malawi的OB/Gyns数量增加了两倍。 此外,研究生医学教育认证委员会已经认可了我们对居民认可的培训的马拉维计划,这是迄今为止唯一获得认证的美国计划。2011年,贝尔福特博士被任命为贝勒部门的主席,以及德克萨斯州儿童教育部的首席OB/ Gyn。他的主要目标之一是进一步贝勒在非洲的医疗保健领域,以解决孕产妇和新生儿死亡率以及产科瘘管。他为我们在马拉维的教师所做的巨大工作以及这些医生和助产士所做的结果感到自豪。在25区域的设施中,孕产妇死亡率降低了70%,新生儿死亡率已降低到几乎为零。Baylor负责制定一项专业培训计划,该计划的培训量增加了三倍,使Malawi的OB/Gyns数量增加了两倍。此外,研究生医学教育认证委员会已经认可了我们对居民认可的培训的马拉维计划,这是迄今为止唯一获得认证的美国计划。


开放银行和数据保证:英国租户的案件
摘要在英国实施的开放银行(OB)的承诺是,消费者不再是被动数据生产者,但也可以从其个人数据中使用和衍生价值。ob主要应用于财务决策,付款和借款,大多数现有文献都集中在其在财务服务中的采用上。在本文中,我们研究了其在租户引用中采用的效果,该部门却被忽略了,并将特定的分配问题提出到必需品。我们借鉴了一项研究项目的定性研究,该研究项目研究了住房中的算法风险,包括与房东的深度访谈,让代理商,租户,参考公司,参考公司和其他私人租赁部门(PRS)中的其他利益相关者。同时考虑到消费者和专业人士的观点,我们认为,租户参考的OB采用是一种计算的实践,这是由于更简化的申请流程,具有令人放心的界面设计和机构验证。这样的技术和社会要素与租赁市场的特定权力关系重叠,在某些情况下,在某些情况下将其作为“选择加入”选项,而更像是默认设置,而当租户认为他们对他们想要共享的数据没有太多控制权。

二价金属离子在酶促DNA连接中的作用
图1-1:依赖性DNA连接酶结构域结构。对齐结构域的对齐。与DNA结合结构域(DBD,RED)一起突出显示了构成核心催化域的腺苷域和寡核苷酸结合(ob折,黄色)结构域。列出了每种蛋白质列出的活跃位点的位置。chvlig没有大的DBD,而是在OB折内包含一个小的20个氨基酸“闩锁”(闩锁,蓝色),可以帮助DNA结合。也为Lig3独有的锌指域(Znf,橙色)。n-和c末端蛋白质相互作用基序和细胞定位信号未显示。

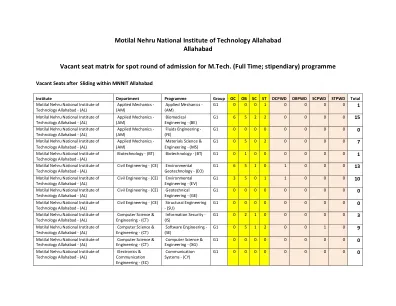
M.Tech 现场录取空缺座位表 (...
学院 部门 项目组 OC OB SC ST OCPWD OBPWD SCPWD STPWD 总计 莫蒂拉尔尼赫鲁国立科技学院 阿拉哈巴德 - (AL)