XiaoMi-AI文件搜索系统
World File Search SystemSampling

PFAS 采样结果摘要
美国海军开始在海军设施附近指定区域的水井中对饮用水进行取样。表 1 总结了迄今为止的饮用水取样结果。业主在收到初步结果后会收到通知,告知他们水中的 PFOS 和/或 PFOA 浓度是高于还是低于 70 ppt。如果业主饮用水中的 PFOS 和/或 PFOA 浓度超过 70 ppt,也会在初步结果电话通知业主后 24 小时内安排瓶装水配送。所有数据核实并最终确定后,最终实验室结果将邮寄给每位业主。出于隐私保证,下表仅提供计数。
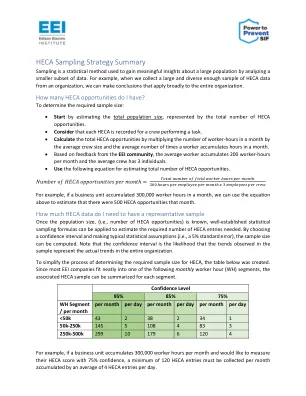
HECA 采样策略摘要
1. 如果某个业务部门累计工时超过 500,000 小时,则应将其细分为更小的业务部门或地理区域。2. HECA 适用于在现场工作的工作人员(例如仓库、电网运营、客户服务等)。如果组织无法估计现场工人的工时数,则组织可以使用总数,这将产生保守的样本估计值。3. 如果安全专业人员、第三方观察员或现场主管经过培训和校准以收集一致的数据,则可以收集 HECA。为避免利益冲突,工作人员负责人不应评估他们直接监督的工作人员。4. EEI 安全测量团队成员承诺到 2024 年底,以至少 75% 的置信度为 1 个业务部门收集 HECA 数据。

环境DNA采样协议
并将DNA样品存储在-20 C的1.5 ml管中。3。定量聚合酶链反应(QPCR)在开始QPCR之前,请选择要测试的样品。这将确定QPCR分析(S)(引物探针集)和反应所需的串行稀释液。分析是针对特定目标物种设计的(表1),应选择以测试样品收集部位存在的任何可能的感兴趣的物种。有关设计引物和探针的信息,请访问https://www.idtdna.com/pages/education/decoded/article/article/designing-pcr-primers-and-probes。每个使用的测定需要单独的主混合物。串行稀释液包含标准量的目标物种DNA,并提供了一种估计测试样品中DNA量的方法。在qPCR运行中,应在每个测定中使用五倍的连续稀释。每个测定也应具有一个阴性对照(没有添加DNA样品的主混合)。


约束抽样强化学习
在线强化学习 (RL) 算法通常难以部署在复杂的面向人类的应用程序中,因为它们可能学习缓慢并且早期性能较差。为了解决这个问题,我们引入了一种实用的算法,用于结合人类洞察力来加速学习。我们的算法,约束抽样强化学习 (CSRL),将先前的领域知识作为 RL 策略的约束/限制。它采用多种潜在的策略约束来保持对单个约束错误指定的鲁棒性,同时利用有用的约束来快速学习。给定一个基础 RL 学习算法(例如 UCRL、DQN、Rainbow),我们提出了一种具有消除方案的上限置信度,该方案利用约束与其观察到的性能之间的关系来自适应地在它们之间切换。我们使用 DQN 型算法和 UCRL 作为基础算法来实例化我们的算法,并在四种环境中评估我们的算法,包括三个基于真实数据的模拟器:推荐、教育活动排序和 HIV 治疗排序。在所有情况下,CSRL 都能比基线更快地学习到好的策略。

产品信息采样套件.cdr
2022 年 10 月 31 日——Hotzone Solutions (HZS) 是一家由一群前军人和民用化学、生物、放射和核专家创立的国际公司。(CBRN)...


模块 4,第 3 章:抽样计划
◦☒ 可以与测量单位相同(例如,教师、学生、家长、管理人员)。◦☒ 可以是更大的单位(例如,教室、年级、学校、学区)。◦☒ 对测量发生的最高级别进行抽样(例如,如果要测量每所学校的学生、教师和校长,则抽样学校)。

铅和铜 - 采样计划
社区供水部门必须确定一组铅和铜采样点,其中至少包含进行标准监测所需的采样点数量(请参阅说明以了解所需采样点数量)。强烈建议采样池包含比所需更多的采样点,以防在采样时常规采样点不可用。采样池必须使用以下标准针对高风险采样点。

对受访者驱动的采样的加强学习
6011 DBH受访者驱动的采样(RDS)是一种基于网络的抽样策略,用于研究隐藏人群,无需提供采样框架。在RDS研究的每个时期中,当前的研究参与者浪潮都被激励以通过其社交联系来招募下一波浪潮。RDS的成功和效率可以严重取决于激励措施的属性和基础(潜在的)网络结构。我们提出了一种基于增强学习的自适应RDS设计,以优化某种研究实用程序,例如效率,治疗传播,覆盖范围等。我们的设计基于与RDS过程的分支过程近似,但是,即使没有完全识别网络,我们提出的研究后推论程序也适用于一般网络模型。仿真实验表明,所提出的设计在静态和两步RDS程序方面具有巨大的提高。