XiaoMi-AI文件搜索系统
World File Search SystemSugiura

使用多模式LLM /作者= Kambara,Motonari的人类行动理解基于机器人计划; Hori,Chiori; Sugiura,Komei; ota,kei; Jha,Devesh K。; Khurana,Sameer; Jain,Siddarth; corcodel,radu;罗梅雷斯,迭戈; Le Roux,Jonathan /CreationDate = 2024年6月11日 /受试者=人工智能,计算机视觉,机器人技术,语音< /div>
摘要在未来的智能家居中,机器人有望处理日常任务,例如烹饪,取代人类的参与。为机器人自主获得此类技能是高度挑战的。因此,现有方法通过通过监督学习来控制真实的机器人和培训模型来解决此问题。但是,长途任务的数据收集可能非常痛苦。为了解决这一挑战,这项工作着重于从人类视频中生成动作序列的任务,展示了烹饪任务。通过现有方法为此任务而生成的动作序列的质量通常不足。这部分是因为现有方法不会有效地处理每个输入模式。为了解决此问题,我们提出了Avblip,这是一种用于生成机器人动作序列的多模式LLM模型。我们的主要贡献是引入多模式编码器,该编码器允许多种视频,音频,语音和文本作为输入。这使下一个动作的生成可以考虑到人类的语音信息和环境产生的音频信息。结果,在所有标准评估指标中,所提出的方法优于基线方法。
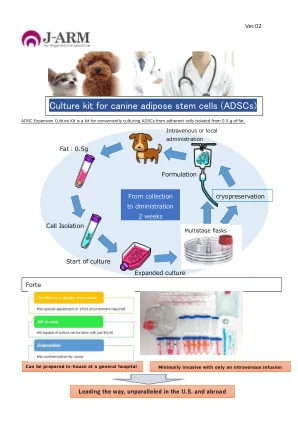
犬脂肪干细胞(ADSC)的培养套件
3)Mitani K 1,Ito Y 1,Takene Y 1,Jeong EM 2,Kang HS 2,Kim IG 3,Inaba T 1,4,Hatoya S 4,Sugiura K 4(1 J-Arm。2 Cell2in,韩国。 3首尔2 Cell2in,韩国。3首尔

ncmag116 dasatinib |建议文件v1.0 | 2024年7月
状态为2或更少,具有足够的肾脏或肝功能12、13。 Ravandi等人(2016年)的一项研究允许在检测到费城染色体异常之前已预先治疗化学疗法的个体(n = 94)13。 在两项Ravandi等人的研究中,达沙替尼每天两次以50mg的剂量在8个周期中的前14天引入50mg,后来修改为每天的每日剂量为100mg 12,13,13。 在Sugiura等人的研究患者中,如果他们年龄在15至64岁之间,新诊断为pH+全部,ECOG性能状态小于3,并且足够的肾脏或肝功能14。 在初始诱导阶段, dasatinib每天以140mg的速度开始,然后每天从感应阶段2 14开始。 在美国进行了两项Ravandi等人的研究,一项研究是在一个地点进行的,一项是一项多中心研究,而Sugiura等人的研究是在日本进行的一项多中心研究,12-14。 纳入研究的细节可以在表1中找到。状态为2或更少,具有足够的肾脏或肝功能12、13。Ravandi等人(2016年)的一项研究允许在检测到费城染色体异常之前已预先治疗化学疗法的个体(n = 94)13。在两项Ravandi等人的研究中,达沙替尼每天两次以50mg的剂量在8个周期中的前14天引入50mg,后来修改为每天的每日剂量为100mg 12,13,13。在Sugiura等人的研究患者中,如果他们年龄在15至64岁之间,新诊断为pH+全部,ECOG性能状态小于3,并且足够的肾脏或肝功能14。在初始诱导阶段, dasatinib每天以140mg的速度开始,然后每天从感应阶段2 14开始。在美国进行了两项Ravandi等人的研究,一项研究是在一个地点进行的,一项是一项多中心研究,而Sugiura等人的研究是在日本进行的一项多中心研究,12-14。纳入研究的细节可以在表1中找到。

2024年9月21日,星期六,日本科比时装市场
凯尔:冈山大学)秘书长:Toshiharu Shikanai(京都大学)总事务秘书:Kentaro Ifuku(Kyoto University)组织委员会组织委员会Koichiro Awai(Shizuoka University) (大阪大学)Yuri Munekage(Kwansei Gakuin大学)Jun Minamigawa(国家基本生物学研究所)Wataru Sakamoto(冈山大学)Miwa Sugiura(Ehime University)Kintake Sonoike(Waseda University)

成人发病
1。efthimiou P,Paik PK,Bielory L.成人发病的诊断和人物。Ann Rheum Dis 2006; 65:564-72。2。Efthimiou P,Kontzias A,Hur P等。成人发病的焦点是:临床表现,诊断,治疗和未满足的靶向疗法时代。semin关节炎流变2021; 51:858-74。3。Yamaguchi M,Ohta A,Tsunematsu T等。 成人分类的预定标准。 J Rheumatol 1992; 19:424-30。 4。 Ichida H,Kawaguchi Y,Sugiura T等。 成人发作的静止病的临床表现与侵蚀性关节炎相关:与铁蛋白和白介素-18的水平较低。 关节炎护理Res(Hoboken)2014; 66:642-6。 5。 Bindoli S,Baggio C,Doria A等。 成人发病的疾病(AOSD):了解病理生理学,遗传学和新兴治疗方案的进展。 药物2024; 84:257-74。Yamaguchi M,Ohta A,Tsunematsu T等。成人分类的预定标准。J Rheumatol 1992; 19:424-30。4。Ichida H,Kawaguchi Y,Sugiura T等。 成人发作的静止病的临床表现与侵蚀性关节炎相关:与铁蛋白和白介素-18的水平较低。 关节炎护理Res(Hoboken)2014; 66:642-6。 5。 Bindoli S,Baggio C,Doria A等。 成人发病的疾病(AOSD):了解病理生理学,遗传学和新兴治疗方案的进展。 药物2024; 84:257-74。Ichida H,Kawaguchi Y,Sugiura T等。成人发作的静止病的临床表现与侵蚀性关节炎相关:与铁蛋白和白介素-18的水平较低。关节炎护理Res(Hoboken)2014; 66:642-6。5。Bindoli S,Baggio C,Doria A等。成人发病的疾病(AOSD):了解病理生理学,遗传学和新兴治疗方案的进展。药物2024; 84:257-74。

脓疱性psariasis是由阿托辛珠单抗和贝伐单抗治疗触发的
2。lim DS,Triscott J. O'Brien的光肉瘤,与多西环素光毒性相关。澳大利亚J Dermatol。2003; 44:67 --- 70。 3。 Nanbu A,Sugiura K,Kono M,Muro Y,Akiyama M. Annular Elas-tolytic巨型细胞肉芽肿成功地用盐酸minocycline治疗。 Acta Derm Venereol。 2015; 95:756 --- 7。 4。 Jeha GM,Luckett KO,Kole L.阳光颗粒对强力霉素的反应。 JAAD案代表2020; 6:1132 --- 4。 5。 Kabuto M,Fujimoto N,TanakaT。通过长期使用盐酸米诺环素盐酸盐成功治疗了广义的环状弹性弹性细胞颗粒。 EUR J Dermatol。 2017; 27:178 --- 9。2003; 44:67 --- 70。3。Nanbu A,Sugiura K,Kono M,Muro Y,Akiyama M. Annular Elas-tolytic巨型细胞肉芽肿成功地用盐酸minocycline治疗。Acta Derm Venereol。2015; 95:756 --- 7。4。Jeha GM,Luckett KO,Kole L.阳光颗粒对强力霉素的反应。 JAAD案代表2020; 6:1132 --- 4。 5。 Kabuto M,Fujimoto N,TanakaT。通过长期使用盐酸米诺环素盐酸盐成功治疗了广义的环状弹性弹性细胞颗粒。 EUR J Dermatol。 2017; 27:178 --- 9。Jeha GM,Luckett KO,Kole L.阳光颗粒对强力霉素的反应。JAAD案代表2020; 6:1132 --- 4。 5。 Kabuto M,Fujimoto N,TanakaT。通过长期使用盐酸米诺环素盐酸盐成功治疗了广义的环状弹性弹性细胞颗粒。 EUR J Dermatol。 2017; 27:178 --- 9。JAAD案代表2020; 6:1132 --- 4。5。Kabuto M,Fujimoto N,TanakaT。通过长期使用盐酸米诺环素盐酸盐成功治疗了广义的环状弹性弹性细胞颗粒。EUR J Dermatol。2017; 27:178 --- 9。2017; 27:178 --- 9。

在数字时代赋予幼儿权力
该报告的开发是由安德烈亚斯·施莱切尔(Andreas Schleicher)和尤里·贝尔法利(Yuri Belfali)指导的,由卡洛斯·冈萨雷斯·桑乔(Carlosgonzález-Sancho)和斯特帕尼·贾梅特(StéphanieJamet)领导。StéphanieJamet写了第1章和第4章,Carlosgonzález-Sancho写了第2章和第8章,克里斯塔·罗金斯(Christa Rawkins)写了第3章,伊丽莎白·舒伊(Elizabeth Shuey)写了第5章,并为该项目做出了各种贡献,克拉拉·巴拉塔(Clara Barata国家笔记由Heewoon Bae和Christa Rawkins编写,并提供了Kentaro Sugiura的意见,他们也为该报告做出了贡献。克里斯塔·罗金斯(Christa Rawkins)协调了案例研究纲要的发展。邓肯·克劳福德(Duncan Crawford)提供了沟通和消息支持。Jennifer Allain编辑了该报告。Cassandra Davis,Stephen Flynn,Kevin Gillespie,Eleonore Morena,Cassandra Morley,Della Shin和Olivia Tighe为生产和交流提供了支持。 图形设计支持由Lushomo提供。 在数字世界政策调查中通过幼儿教育和护理收集数据,以及统计分析和产出由NoraBrüning,Vanessa Denis,Lynn-Malou Lutz和JuditPál进行的。 Lynn-Malou Lutz也为该报告做出了贡献。 作者要感谢OECD同事Gabor Fulop,Francesca Gottschalk,Jordan Hill,Rowena Phair,Giannina Rech,Lisa Robinson和Daniel Salinas的贡献。Cassandra Davis,Stephen Flynn,Kevin Gillespie,Eleonore Morena,Cassandra Morley,Della Shin和Olivia Tighe为生产和交流提供了支持。图形设计支持由Lushomo提供。在数字世界政策调查中通过幼儿教育和护理收集数据,以及统计分析和产出由NoraBrüning,Vanessa Denis,Lynn-Malou Lutz和JuditPál进行的。Lynn-Malou Lutz也为该报告做出了贡献。作者要感谢OECD同事Gabor Fulop,Francesca Gottschalk,Jordan Hill,Rowena Phair,Giannina Rech,Lisa Robinson和Daniel Salinas的贡献。

用于扩增被子植物质体基因 matK DNA 片段的有用引物设计
参考文献 Chase MW,Soltis DE,Olmstead RG,Morgan D.,Les DH,Mishler BD,Duvall M. R. , 价格 R. A. , Hills HG , Qiu Y.-L . , Kron KA , Rettig J. H.,Conti E.,Palmer J. D 円 Manhart J. R. , Sytsma K. J. ,迈克尔斯 H. J. , 克莱斯 W. J. , Karol KG , Clark WD , Hedroen M. , Gaut BS , Jansen R. K. , 金K.-J. , 温皮 CF , 史密斯 J 。 F.,Fumier GR,Strauss SH,Xiang Q.-Y. , Plunkett GM , Soltis PS , Swensen S. , Williams SE , Gadek P. A . , 奎因 C.J. , Eguiarte LE, Golenberg E., Leam GH Jr., Graham SW, Barrett SC, Dayanandan S. 和 Albert VA 1993. 种子植物的系统发育:质体基因 rbc 的核苷酸序列分析 L. Ann.密苏里机器人。警卫。 80: 528-580。道尔 J. J。和 Doyle J. L. 1987.一种用于少量新鲜叶组织的快速 DNA 分离程序。植物化学。公牛 l。 19: 11-15。/平塚 J. , Shimada H. , Whittier R. , lshibashi T. , Sakamoto M. , Mori M. , Kondo C. , Ho 吋 i Y. , Hirai A. , Shinozaki K. 和 Sugiura M. 1989. 水稻(Oryza sativa)叶绿体基因组的完整核苷酸序列:不同 tRNA 基因之间的分子间重组导致谷物进化过程中的 m 吋 2 或质体 DNA 倒位。莫尔。基因 t 将军。 217: 185-194。 Johnson LA 和 Soltis DE 1994. 虎耳草科植物的 matK DNA 序列和系统发育重建。字符串系 统。博特。 19:143-156。 Neuhaus H. 和 Link G. 1987.芥菜的叶绿体 tRNA Lys (UUU) 基因。当前。基因。 11:251-257。 Steele KP 和 Vilgalys R. 1994. 利用质体基因 mat K 的核苷酸序列对花荬科进行系统发育分析。博特。 19:126-142。 Sugita M. , Shinozaki K. 和 Sugiura M. 1985. 烟草叶绿体 tRNA Lys(UUU)基因含有一个2.5千碱基对的内含子:一个开放阅读框和内含子内保守的边界序列。 Proc. Na. l.学院Sci.USA 82: 3557-3561.

在数字时代赋予幼儿权力
该报告的开发是由安德烈亚斯·施莱切尔(Andreas Schleicher)和尤里·贝尔法利(Yuri Belfali)指导的,由卡洛斯·冈萨雷斯·桑乔(Carlosgonzález-Sancho)和斯特帕尼·贾梅特(StéphanieJamet)领导。StéphanieJamet写了第1章和第4章,Carlosgonzález-Sancho写了第2章和第8章,克里斯塔·罗金斯(Christa Rawkins)写了第3章,伊丽莎白·舒伊(Elizabeth Shuey)写了第5章,并为该项目做出了各种贡献,克拉拉·巴拉塔(Clara Barata国家笔记由Heewoon Bae和Christa Rawkins编写,并提供了Kentaro Sugiura的意见,他们也为该报告做出了贡献。克里斯塔·罗金斯(Christa Rawkins)协调了案例研究纲要的发展。邓肯·克劳福德(Duncan Crawford)提供了沟通和消息支持。Jennifer Allain编辑了该报告。Cassandra Davis,Stephen Flynn,Kevin Gillespie,Eleonore Morena,Cassandra Morley,Della Shin和Olivia Tighe为生产和交流提供了支持。 图形设计支持由Lushomo提供。 在数字世界政策调查中通过幼儿教育和护理收集数据,以及统计分析和产出由NoraBrüning,Vanessa Denis,Lynn-Malou Lutz和JuditPál进行的。 Lynn-Malou Lutz也为该报告做出了贡献。 作者要感谢OECD同事Gabor Fulop,Francesca Gottschalk,Jordan Hill,Rowena Phair,Giannina Rech,Lisa Robinson和Daniel Salinas的贡献。Cassandra Davis,Stephen Flynn,Kevin Gillespie,Eleonore Morena,Cassandra Morley,Della Shin和Olivia Tighe为生产和交流提供了支持。图形设计支持由Lushomo提供。在数字世界政策调查中通过幼儿教育和护理收集数据,以及统计分析和产出由NoraBrüning,Vanessa Denis,Lynn-Malou Lutz和JuditPál进行的。Lynn-Malou Lutz也为该报告做出了贡献。作者要感谢OECD同事Gabor Fulop,Francesca Gottschalk,Jordan Hill,Rowena Phair,Giannina Rech,Lisa Robinson和Daniel Salinas的贡献。

开幕式开所式
Vassiliki Boussiotis,哈佛医学院Kenji Chamoto,CCII,CCII,京都大学希尔德·切罗特(Hilde Cheroutre),拉霍亚(La Jolla)免疫学研究所,圣裘德儿童研究医院Cristina Cristina Cristina Cristina Cristina Cristina Cristina Cristina Cristina Cristina,Stanford University,Stanford Univelsi哈格瓦尔,京都大学塔苏科大学,CCII,CCII,京都大学(开幕词)Juliana Idoyaga,加利福尼亚大学圣地亚哥卡尔大学,宾夕法尼亚大学nobuuki kakiuchi大学,托马斯·科普斯,托马斯·基普斯大学,加利福尼亚大学,加利福尼亚大学,加利福尼亚大学,加利福尼亚大学,加利福尼亚州kipps京都大学田纳西亚大学,卡利奥尼亚大学旧金山克劳斯·潘特尔大学,大学医学中心,汉堡 - 埃潘多夫大学,约翰·霍普金斯医学Eliane Piaggio大学面具塔吉马大学,CCII,京都大学Yosuke Togashi,冈山大学Suzane Louise Topalian,Johns Hopkins Medicine Hans Guaderel,Memorial Slon Kettering癌症中心圣地亚哥Zelenay,癌症研究