XiaoMi-AI文件搜索系统
World File Search SystemSynthes

depuy合成
对学生来说,与全球供应链运营领域的行业领导者合作是有益的。研究公司在来年面临的逆境使学生可以更深入地了解全球事件如何影响运营。与MTU合作进行实时案例研究,为DePuy提供了与公司可能希望吸引未来员工的学生互动的机会。凯瑟琳·罗德里格斯(Kathleen Rodrigues)是一名全球商业实践中的MSC学生,概述了虽然作业带来了独特的挑战,但他们对当代主题的作业方法的好处远远超过了:“英国脱欧和Covid19流行作用的作业方法,包括COVID19大流行及其对Depuy的运营和关系的影响,使我们能够与这些相关的台阶进行实现,从而逐渐了解这些领域的局面,从而逐步了解了一系列的领域。


用于骨科应用的干细胞和细胞骨基质产物
• AmnioFix® (MiMedx) • Bio4™ Viable Bone Matrix (formely known as Ovation®) (Osiris Therapeutics/Stryker) • Bone marrow aspirate • Cellentra™ VCBM (Viable Cell Bone Matrix) (ZimVie) • CeLLogix™ (Omnia Medical) • Clarix® Cord 1K (BioTissue) • FiberCel® (Aziyo Biologics)•脂质®微碎片脂肪组织移植系统•Magnus®骨移植(皇家生物学)•MAP3®(RTI手术)•Osteocel®Plusand Pro and Pro and Pro(nuvasive) Primagem®高级同种异体移植(Zimmer Biomet)•RegeNEXX(再生科学)•Scylla™和Scylla™-F(室脊柱)•TrinityEvolution®和Elite®(Orthofix Inc. (Depuy合成)。
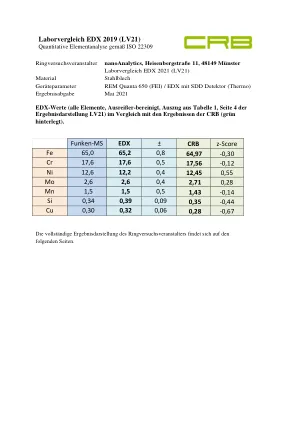
实验室比对 EDX 2019 (LV21) 按照 ISO 22309 进行定量元素分析
Ametek,威斯巴登 Aptiv,伍珀塔尔 BASF Coatings,明斯特 Block Materialprüfungsgesellschaft,柏林 BP,波鸿 Bruker Nano,柏林 联邦刑事警察局,威斯巴登 Carl von Ossietzky 奥尔登堡大学 Carl Zeiss Jena,上科亨 CleanControlling,埃明根-利普廷根 Conti Temic 微电子,因戈尔施塔特 CRB 分析服务,哈德格森 Currenta,勒沃库森 CVUA-RRW,克雷费尔德 D&I-Vallourec 研究中心,法国 Aulnoye-Aymeries DePuy Synthes,奥伯多夫 Dr. Graner & Partner,慕尼黑 EFI 服务,布达佩斯 EnBW Kernkraft,菲利普斯堡 Felix Schoeller,奥斯纳布吕克 苏黎世法医研究所 柏林研究协会 弗劳恩霍夫硅酸盐研究所 ISC,维尔茨堡 研究发展基金会 - FUNDEP,贝洛奥里藏特 汉诺威莱布尼茨大学 GSI,柏林 HARTING,埃斯珀尔坎普 Henkel,杜塞尔多夫 Heraeus Germany,哈瑙 Hirschmann Automotive,兰克韦尔 阿伦大学 普福尔茨海姆大学 IfW,埃森 INDIKATOR,伍珀塔尔 Infineon Technologies,慕尼黑工程协会 Meyer & Horn-Samodelkin 显微镜实验室,罗斯托克 德累斯顿腐蚀防护研究所 麦德林大都会技术学院,麦德林 集成微电子学,Biñan JOMESA 测量系统,Ismaning Kronos,勒沃库森 实验室 Dr.舍夫纳(Schäffner),索林根实验室克奈斯勒(Kneißler),布尔格伦根费尔德(Burglengenfeld)下萨克森州刑事警察局,汉诺威

患者特异性支架引导的骨骼再生概念的临床翻译在四种长骨缺损
背景:创伤,感染或肿瘤切除后的骨缺陷对患者和克利尼亚人带来了挑战。迄今为止,自体骨移植(ABG)是骨再生的金标准。为了解决ABG的限制,例如有限的收获量以及过快的重塑和吸收,开发了脚手架引导的骨再生(SGBR)的新治疗策略。在大型至大大胫骨分段缺陷的良好特征绵羊模型中,三维(3D)印刷的复合支架显示了SGBR策略中临床上相关的生物相容性和骨导能的能力。在这里,我们报告了四个挑战性的临床病例,具有大型复杂的创伤后长骨缺陷,使用患者特异性SGBR作为成功的治疗方法。方法:给予知情同意后,计算机断层扫描(CT)图像用于设计患者特异性的可生物降解医学级的多丙酮酸二苯二甲酸 - 三磷酸二磷酸二磷酸二烷酸酯(MPCL-TCP,80:20 wt%)支架。使用物质模拟物进行分割CT扫描以产生缺陷模型,并使用Autodesk Meshmixer设计了脚手架零件。支架原型为3D打印,以验证稳健的临床处理和骨缺陷。最终的脚手架设计是根据食品药品和药物管理局(FDA)指南制造的。结果:四名患者(年龄:23 - 42岁)患有创伤后下肢大骨缺损(病例1:4 cm股骨远端,案例2:10 cm胫骨轴,案例3:复杂的Malunion股骨,情况4:案例4:不规则形状的远端胫骨)。给予知情同意后,通过植入装有ABG的定制MPCL-TCP脚手架(案例2:用Reamer-Irrigator-Aspirator-Aspirator-Aspirator System(RIA,ria,synthess®)收获的定制MPCL-TCP脚手架治疗患者。在所有情况下,脚手架均匹配实际的解剖缺陷,并且没有观察到围手术期的不良事件。案例1、3和4显示了骨向大蜂窝孔(孔> 2 mm)的骨质内生成的证据,并完全相互连接的支架结构,在最后一次放射线照相随访(植入后8 - 9个月)在骨末端的指示性骨桥末端末端。在植入后23个月的随访中,在情况2中实现了全面的骨再生和全重承重。结论:这项研究表明,指导骨再生原理为脚手架的骨组织工程的床边翻译。SGBR中的脚手架设计应具有组织特异性的形态学特征,该标志可以刺激并指导最初宿主响应的阶段,从而向整个再生。因此,脚手架提供了具有形态学和生物材料特性的物理细分市场,允许细胞迁移,