XiaoMi-AI文件搜索系统
World File Search SystemVF

20240528-ONCO-Boin 信息图表 VF
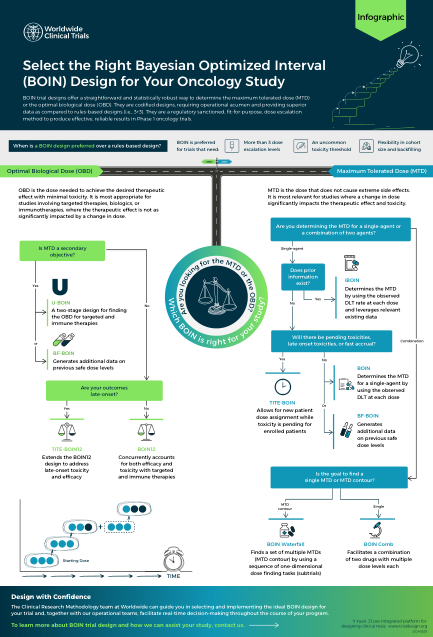
BOIN 试验设计提供了一种简单且统计稳健的方法来确定最大耐受剂量 (MTD) 或最佳生物剂量 (OBD)。它们是编纂的设计,需要操作敏锐度,并提供比基于规则的设计(即 3+3)更优质的数据。它们是一种经监管部门批准的、适合用途的剂量递增方法,可在 1 期肿瘤学试验中产生有效、可靠的结果。

MEGADRIVE-LCI - VF 服务
保护和监控功能确保不超过驱动器的机械和热工作极限。它们在可编程高速控制器的微处理器上运行的应用程序中实现,其信号由诊断系统评估。最重要的保护功能(过流和超速)也由硬接线设备复制,作为软件保护功能的备份。跳闸和警报被传输到相关设备以关闭驱动器,或在必要时完全跳闸。故障以简明语言显示在控制柜门上的控制面板上,并清晰指示第一个故障。提供多种保护和监控功能。以下是标准 MEGADRIVE-LCI 所包含的最低限度。

SCOA_Pacific_Announcement - 6.26.24 vF
住友集团的投资包括位于马萨诸塞州和加利福尼亚州的六个项目,包括 27 兆瓦太阳能光伏发电和 25 兆瓦时电池储能,将满足大约 4,000 个美国家庭的等效电力需求,并支持向更可持续的能源系统过渡。这两个马萨诸塞州项目被指定为低收入社区太阳能项目,是根据马萨诸塞州太阳能可再生能源目标 (SMART) 计划开发的。这些项目为当地用户,特别是那些无法在现场安装太阳能的用户,提供了享受可再生能源和折扣电价的好处。社区太阳能用户包括住宅以及商业和工业 (C&I) 客户。社区太阳能市场预计将持续增长,并从目前的 6 吉瓦规模扩大到 2028 年的估计 14 吉瓦,年增长率为 8%。
MEGADRIVE-LCI - VF 服务
保护和监控功能可确保不超过驱动器的机械和热运行极限。它们在可编程高速控制器的微处理器上运行的应用程序中实现,其信号由诊断系统评估。最重要的保护功能(过流和超速)也由硬接线设备复制,作为软件保护功能的备份。跳闸和警报被传输到相关设备以关闭驱动器,或在必要时完全跳闸。故障以简明语言显示在控制柜门上的控制面板上,并显示在任何远程控制面板上,并清晰指示第一个故障。提供多种保护和监控功能。以下是标准 MEGADRIVE-LCI 所包含的最低限度。

VF PR IMDEX - 海军集团
Belharra® 是海军集团为海军提供的一款紧凑型护卫舰,可独立或加入特遣部队执行大量任务,用于远洋任务或在拥挤和有争议的作战环境中进行浅水作业。Belharra® 受益于海军集团数百年的经验,确保无与伦比的隐身性和出色的探测能力。它具有强大的平台、弹性系统和可恢复性功能,使其能够在损坏后保持作战能力。这艘新护卫舰在防空、反水面、反潜和不对称战争领域具有高水平能力,并具有深度打击能力。

MCPSA 完整战略计划 _vF
● MCPSA 在倡导公共特许学校领域发挥了关键作用,支持在 2012 年取消特许学校的地理“上限”,成功倡导 2021 年全州公平资助,目前密苏里州 100% 的特许学校 LEA 都是该协会的成员

Chanel 影响案例研究 Gig Economy vf
本文件中包含的未来预测、管理目标、估计、前景或回报。在不影响欺诈责任的情况下,Channel Capital Advisors LLP 的任何成员均不接受也不会接受与本报告有关的任何责任、义务或义务(无论是合同、侵权或其他)。本文中包含的信息是严格保密的,未经 Channel Capital Advisors LLP 的明确书面许可,不得以任何方式全部或部分披露、复制、分发或发布。收件人承诺不将任何机密信息用于任何非法目的。其中包含的信息仅供预期收件人使用,禁止向未经授权的人员共享此信息。如果您不是预期收件人,则禁止披露、复制、分发或依赖此信息采取任何行动,并且可能是非法的。如果您不是预期收件人,请将电子邮件退回给发件人,并

VF 系列服务手册 - 2002 - Haas Automation Inc.
�� �������������������� ���� ���� ���� ���������������������� ��� ���������������������������� ����� ���������������������������������������������������� ��� ������������������������������������ ������� ������������������������������������ ��� ������������������������������ ���� ������������������������������ ��� ... �������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������� ������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������ ������������� ��� �������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������� ������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������ ��� �������������������� �������� ������������

抗抑制剂凝血复合物:Feiba NF/Feiba VF
Feiba 是一种抗抑制剂凝血复合物,适用于控制和预防带有抑制剂的血友病 A 和 B,以及用于围手术期管理和常规预防,以防止/减少出血发作频率。通过一项多中心随机前瞻性试验证明了疗效,该试验招募了 44 名带有抑制剂的血友病 A 患者、3 名带有抑制剂的血友病 B 患者和 2 名获得性因子 VIII 抑制剂患者。该试验旨在评估 Feiba 在治疗关节、粘膜、肌肉皮肤和紧急出血发作(如中枢神经系统出血和手术出血)方面的疗效。受试者以 50 单位/千克的剂量接受治疗,间隔 12 小时。93% 的发作出血得到控制,78% 的发作在 36 小时内通过一次或多次输注实现止血。最常见的不良反应(>5% 受试者)是贫血、腹泻、关节血肿、乙肝表面抗体阳性、恶心和呕吐。严重的药物不良反应是超敏反应和血栓栓塞事件,包括中风、肺栓塞和深静脉血栓形成。