XiaoMi-AI文件搜索系统
World File Search SystemVQ

导航 AI 进行评估:VQ 指导(国际...
如果您是 Pearson 的评估助理(标准核查员/外部考官),Pearson 已发布一个培训模块,可在 AssociateU 上获取。与其他形式的不当行为一样,如果标准核查员/外部考官怀疑或发现样本中存在 AI 滥用,建议他们首先与指定的团队负责人讨论他们的担忧。然后必须通过 Pearson 支持门户将其上报给 Pearson,选择标记、审核和抽样作为问题类型,选择不当行为作为类别类型。相关不当行为团队将检查任何上报的担忧并与中心采取适当行动。标准核查员/外部考官应继续进行核查并在可能的情况下采取行动。如果发现抄袭(包括滥用人工智能),这意味着无法验证学习者自己的作品是否被准确评估,这将导致第一份报告的结果为“认证待定”,并且需要第二份样本。

VQ 深度探索 - 解密 CRDMO 的 DNA
四种主要疗法主导着制药生态系统的研发工作——肿瘤学(癌症)、神经病学(中枢神经系统相关疾病)、内分泌和代谢(糖尿病、肥胖症等)和免疫学(免疫系统)。该领域进行的总临床试验中约有 80% 与试图解决这些疗法中未满足需求的药物有关。肿瘤学相关的研发在过去 10 年中呈现强劲增长,并且越来越注重创新作用机制。神经病学在治疗神经退行性疾病、神经肌肉疾病和精神疾病的试验中呈现显著增长(过去 5 年内超过 500 项)。神经病学试验中最大的份额仍然是阿尔茨海默氏症和帕金森氏症。代谢/内分泌学包括糖尿病、肥胖症和 NASH,过去 5 年中围绕减肥药物的试验活动数量增加了近一倍(主要集中在 GIP/GLP 胰高血糖素受体激动剂)。

电子 QML 的 VQ 补充信息表-...
按照 MIL-PRF-38534 的所有规定,使用 DLA Land and Maritime-VQ 合格材料和制造施工技术制造、组装和测试的 K 级、H 级、G 级、E 级或 D 级产品,可视为符合此处列出的相应产品保证等级。此列表中包含的信息反映了特定测试样品的一般材料和制造技术。为了保护制造商的专有工艺和材料,仅列出通用工艺和材料。用户必须联系制造商以获取有关特定材料(例如环氧树脂、吸气剂、焊料类型)或工艺细节的任何详细信息。未列出的工艺和材料可能被视为合格,因为与用于认证的工艺和材料相似(例如,不同的电线、封装或芯片尺寸)。有关认证限制的基准,请参阅 MIL-PRF-38534 的附录 E,l 级,主要变更段落。

VQ 深度探索:为能源转型铺平道路
电气化的瓶颈是电网,因为可再生能源发电需要传输到消费中心。国际能源署 (IEA) 预计,到 2030 年,电网年度支出将从 2023 年的 3000 亿美元翻一番,达到 6000 亿美元。无论是彭博新能源财经 (BNEF)、国际能源署 (IEA) 还是绿色金融网络 (NGFS),在所有情况下,电网投资都有望显著加速,尽管预期增长率差异很大。所有预测都表明,电网支出不仅将保持高于当前水平,而且随着我们步入下一个十年 2030-2040 年,支出还将增加,这意味着我们现在看到的强劲需求上升趋势预计将持续下去。

top:461;left:341"> U锲社劝擘Gz糖g
M§âjUÉƧâgÀÄ PÀ°¸ÀĪÀ zsÉÆÃgÀuÉ M¨ÉÆâ§âgÉÆAzÉÆAzÀÄ VqÀ ¨É¼É¸ÀĪÀ ¥ÉæÃgÀuÉ «ÄvÀ¸ÀAvÀw »vÀ£ÀÄrAiÀÄ £ÀÄrAiÉÆÃt §¤ß, ¸ÉêÉAiÀÄ ªÀiÁqÉÆÃt §¤ß, //gÁ//


MIL-PRF 的认证和资格程序...
前言 本文件旨在描述管理和维护混合/MCM(多芯片模块)微电路的 MIL-PRF-38534 QML 计划所需的程序。本文件适用于 DLA Land and Maritime 管理的 QML-38534,作为 MIL-PRF-38534 的合格活动。QML 计划提供了一种将军事和商业计划有效地结合成一个灵活系统的方法,并涵盖了广泛的性能等级。强烈建议制造商和用户使用标准微电路图纸 (SMD),以降低成本并缩短交货时间。我鼓励您为改进此或我们管理的 220 多个 QML/QPL(合格零件清单)提供意见。有关本文件任何部分的问题或澄清,请联系:美国邮政私人承运商(例如 UPS、FED EX 等)DLA Land and Maritime -VQ DLA Land and Maritime -VQ Robert M. Heber Robert M. Heber PO Box 3990 3990 East Broad Street Columbus, OH 43218-3990 Columbus, OH 43213 电话:(614) 692-0538 传真:(614) 692-6942 或 (614) 693-1658 电子邮件:robert.heber@dla.mil

基于脑电音频信号处理的闭眼和睁眼情况下的深度学习模式识别技术
摘要:最近,使用脑电图 (EEG) 进行音频信号处理中的模式识别引起了广泛关注。眼部情况(睁眼或闭眼)的变化反映在 EEG 数据的不同模式中,这些数据是从一系列情况和动作中收集的。因此,从这些信号中提取其他信息的准确性在很大程度上取决于在采集 EEG 信号期间对眼部情况的预测。在本文中,我们使用深度学习矢量量化 (DLVQ) 和前馈人工神经网络 (F-FANN) 技术来识别眼部情况。由于 DLVQ 能够学习代码约束的码本,因此在分类问题上优于传统 VQ。在使用 k 均值 VQ 方法初始化后,DLVQ 在 EEG 音频信息检索任务上测试时表现出非常出色的性能,而 F-FANN 将眼部状态的 EEG 音频信号分类为睁眼或闭眼。与 F-FANN 相比,DLVQ 模型具有更高的分类准确度、更高的 F 分数、精确度和召回率,以及更出色的分类能力。
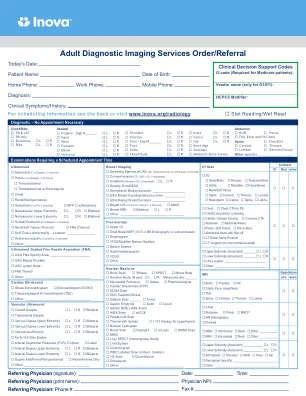
成人诊断成像服务订单/推荐
核医学骨骼扫描:SpectImpost:乳房:乳房:themant:ther:LR黑色素瘤部位:_________________________________药理学药理药理学心疗中心病(pyp)(pyp)固体液体胃反流(牛奶扫描)HIDA扫描w/cck甲状旁腺扫描甲状腺甲状腺甲状腺甲状腺甲状腺甲状腺甲状腺甲状腺甲状腺甲状腺疗法核囊图:肾脏囊力术:肾脏扫描:肾脏扫描:in Liver/Spleen Cisternogram WBC Labeled Scan (Indium, Ceretec) VQ Scan Quantitative Octreoscan Other: _____________________________________

MIL-PRF-38535规格DE
根据MIL-PRF-38535制造,组装和测试的微电路应带有“ QML”认证标记或“ Q”缩写。制造,组装和测试的产品应符合MIL-PRF-38535的所有规定;并应在本文所示的DLA土地和海上VQ认证线路上制造。此QML中包含的信息反映了特定测试样本的实际制造线,材料和制造构建技术。任何代表为符合标准的产品均应使用本文列出的材料和制造构造技术在线/流量上制造,以满足用户的要求。用户应负责确定QML清单是否足以证明预期应用程序的能力。