XiaoMi-AI文件搜索系统
World File Search SystemVis
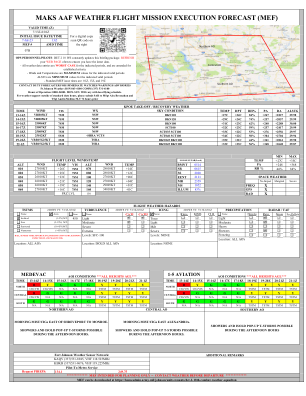
MAKS AAF 天气飞行任务执行预报 (MEF)
时间 13-14Z 14-15Z 15-16Z 16-17Z 17-18Z 18-19Z 19-20Z 20-21Z 21-1Z 时间 13-14Z 14-15Z 15-16Z 16-17Z 17-18Z 18-19Z 19-20Z 20-21Z 21-1Z R Y G G G Y Y Y Y R Y G G G Y Y Y Y CIG/VIS CIG/VIS N/A N/A N/A TSTM TSTM TSTM TSTM CIG/VIS CIG/VIS N/A N/A N/A TSTM TSTM TSTM TSTM R G G G G Y Y Y Y R G G G G Y Y Y Y CIG/VIS N/A N/A N/A N/A TSTM TSTM TSTM TSTM CIG/VIS N/A N/A N/A N/A TSTM TSTM TSTM TSTM G G G G G Y Y Y Y G G G G G Y Y Y Y N/A N/A N/A N/A N/A TSTM TSTM TSTM TSTM N/A N/A N/A N/A N/A TSTM TSTM TSTM TSTM

MAKS AAF 天气飞行任务执行预报 (MEF)
时间 19-20Z 20-21Z 21-22Z 22-23Z 23-24Z 24-1Z 1-2Z 2-3Z 3-7Z 时间 19-20Z 20-21Z 21-22Z 22-23Z 23-24Z 24-1Z 1-2Z 2-3Z 3-7Z YYYYYYRRRYYYYYYRRR TSTM TSTM TSTM TSTM TSTM TSTM TS/CIG/VISTS/CIG/VISTS/CIG/VIS TSTM TSTM TSTM TSTM TSTM TS/CIG/VISTS/CIG/VISTS/CIG/VIS YYYYYYYYRYYYYYYYR TSTM TSTM TSTM TSTM TSTM TSTM TSTM TSTM TS/CIG/VIS TSTM TSTM TSTM TSTM TSTM TSTM TSTM TS/CIG/VIS YYYGGGGGYYYYGGGGGY TSTM TSTM TSTM N/AN/AN/AN/AN/A CIG TSTM TSTM TSTM N/AN/AN/AN/AN/A CIG

VFC通讯 - 2023年秋季版
直到特定疫苗可使用,提供商可以使用制造商的包裹插入物,书面常见问题解答或任何其他文件(或生产其自己的信息材料),以告知患者该疫苗的益处和风险。一旦有可用的vis,应使用它;但是,由于缺乏VIS,提供商不应延迟使用疫苗。疫苗信息声明|常见问题| VIS | CDC以下是提供者可以共享的替代资源:•ModernA 12y+(SpikeVax):“接收者和护理人员的信息” PPI-0017_SPIKEVAX-2023-2023-2024-formula-patient-patient-patient-patient-pormula-patient-pormula-pormula-pormulation-sformation-12y-us-us-- use--英语。疫苗,mRNA)|安全信息。

MAKS AAF 天气飞行任务执行预报 (MEF)
时间 20-21Z 21-22Z 22-23Z 23-24Z 24-1Z 1-2Z 2-3Z 3-4Z 4-8Z 时间 20-21Z 21-22Z 22-23Z 23-24Z 24-1Z 1-2Z 2-3Z 3-4Z 4-8Z G G G G G G G G R G G G G G G G G G R N/A N/A N/A N/A N/A N/A N/A N/A N/A TS/CIG/VIS N/A N/A N/A N/A N/A N/A N/A N/A TS/CIG/VIS G G G G G G G G R G G G G G G G G G R N/A N/A N/A N/A N/A N/A N/A N/A N/A TS/CIG/VIS N/A N/A N/A N/A N/A N/A N/A N/A TS/CIG/VIS G G G G G G G G R G G G G G G G G R N/A N/A N/A N/A N/A N/A N/A N/A N/A TS/CIG/VIS N/A N/A N/A N/A N/A N/A N/A N/A N/A TS/CIG/VIS

MAKS AAF 天气飞行任务执行预报 (MEF)
时间 1-2Z 2-3Z 3-4Z 4-5Z 5-6Z 6-7Z 7-8Z 8-9Z 9-13Z 时间 1-2Z 2-3Z 3-4Z 4-5Z 5-6Z 6-7Z 7-8Z 8-9Z 9-13Z G G G G G G G G G G G G G G G G G G G N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A G G G G G G G Y Y G G G G G G G Y Y N/A N/A N/A N/A N/A N/A N/A N/A VIS VIS N/A N/A N/A N/A N/A N/A N/A N/A VIS VIS G G G G G G Y Y Y G G G G G G Y Y Y N/A N/A N/A N/A N/A N/A 可见光 可见光 N/A N/A N/A N/A N/A N/A 可见光 可见光

通用乙肝护理提供者招募传单
• 在 72 小时内将文件记录在 MCIR 中(通常通过电子出生证明)。 • 记录 VFC 所需的疫苗信息:接种疫苗和 VIS 的日期、VIS 日期、制造商、批次以及接种疫苗者的姓名和职称。

MAKS AAF 天气飞行任务执行预报 (MEF)
时间 1-2Z 2-3Z 3-4Z 4-5Z 5-6Z 6-7Z 7-8Z 8-9Z 9-13Z 时间 1-2Z 2-3Z 3-4Z 4-5Z 5-6Z 6-7Z 7-8Z 8-9Z 9-13Z GGGGGGGGGGGGGGGGGGN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AGGGGGGGGYGGGGGGGGYN/AN/AN/AN/AN/AN/AN/AN/AN/A CIG/VIS N/AN/AN/AN/AN/AN/AN/AN/AN/A CIG/VIS GGGGGGGGGGGGGGGGGGGGN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/A

推荐程序 - 用于黄热病疫苗...
• Clinic staff must carefully review travelers' itineraries and administer Yellow Fever vaccine only to those travelers visiting World Health Organization (WHO) designated Yellow Fever infected areas or other areas with a risk of Yellow Fever as posted at: http://www.cdc.gov/travel/default.aspx • Clinic staff should have procedures in place to screen vaccine recipients for contraindications to vaccines prior to vaccine 行政。•诊所工作人员应为接种疫苗接种者提供疫苗信息报表(VIS)黄热疫苗,请参阅以下网址:http://wwwww.cdc.gov/vaccines/hcp/hcp/hcp/hcp/hcp/vis/vis/vis/vis/vis-statements/yf.html或在疫苗之前,请访问疫苗或供应疫苗的情况,并提供疫苗或法定疫苗或法定疫苗或法定疫苗或法定疫苗或法定的疫苗或法定疫苗,或者供应疫苗或疫苗或疫苗的供应或疫苗或法定疫苗或法定疫苗或法定疫苗或经过疫苗或疫苗的供应或供您提供疫苗或疫苗的效果或疫苗或法定性或法定性。•诊所工作人员应指示疫苗接收者或其父母/法律代表带回家,并指示他们在疫苗接种后如何报告不良事件。

MAKS AAF 天气飞行任务执行预报 (MEF)
时间 1-2Z 2-3Z 3-4Z 4-5Z 5-6Z 6-7Z 7-8Z 8-9Z 9-13Z 时间 1-2Z 2-3Z 3-4Z 4-5Z 5-6Z 6-7Z 7-8Z 8-9Z 9-13Z GGGGGGGGGGGGGGGGGGN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AN/AGGGGGGGGYGGGGGGGGYN/AN/AN/AN/AN/AN/AN/AN/AN/A CIG/VIS N/AN/AN/AN/AN/AN/AN/AN/AN/A CIG/VIS YYGGGGGGGYYGGGGGGG TSTM TSTM N/AN/AN/AN/AN/AN/AN/A TSTM TSTM N/AN/AN/AN/AN/AN/AN/A
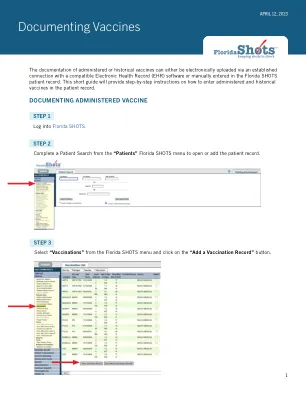
记录疫苗
•疫苗类型:涉及患者接受的疫苗类型。疫苗类型信息超链接超链接打开佛罗里达疫苗类型,疫苗名称,品牌名称和制造商代码,以确保选择正确的疫苗类型。•给定的日期:输入日期,或者如果今天给出疫苗,请输入“ T”,当前日期将自动填充。•注射地点:记录给予免疫的身体的特定位置。•注射路线:记录用于管理免疫的方法。•提供者org id:管理疫苗接种默认为您实践的实践名称。•提供者ID:选择管理免疫的工作人员的提供者ID。•IMM服务网站:如果您的组织有多个服务站点,则可以指出哪个网站进行了疫苗接种。如果正在记录的疫苗接种是最近的疫苗,并且所选的服务网站与“患者信息”页面上的服务站点有所不同,则将询问用户是否要更新患者的服务网站。•资金计划:如果您的组织或其任何网站参与VFC订购工作之一,则您将看到“资金计划”菜单。如果您是从列出的资金计划中管理疫苗的,请从下拉菜单中选择该精力。如果您使用的是私人购买的疫苗,请将标记为“选择”的盒子保留,然后继续记录疫苗。指定患者接受VFC疫苗的资格,因为它适用于这种疫苗接种。如果选择了制造商,则需要批号。•VFC资格:只有在佛罗里达射击为您的组织记录VFC PIN和开始日期的情况下,该字段才能看到此字段,并且从“资金计划”菜单中选择了VFC订购工作。•VIS接收者:选择接受此患者的VIS语句的人。母亲,父亲,监护人和患者的名字已经在患者记录中时可用。如果选择了“其他”,则将输入接收表格的人的名称,以及该人与患者的关系。如果这种关系是母亲,父亲或监护人,并且输入的名称与已记录的名称不同,则将为用户提供将当前信息替换为新信息的选项。此信息将包含在DH687表格,诊所记录卡上,以及该人是否也同意接受治疗。•有关日期:输入为此疫苗接种提供的疫苗信息声明日期。某些组合疫苗可能需要多个关于出版日期。如果存在单个VIS语句的组合疫苗,您将看到一个标有“其他VIS选项”的按钮,该按钮可以使用单独的语句或组合语句。要查看当前的VIS信息,请单击上面“ VIS接收者”字段的超链接CDC疫苗信息声明(VIS)。•VIS接收者给予的治疗同意:记录VIS信息后,启用并要求此字段。如果接受VIS的人同意接受治疗,则将默认值留在“是”。只有在选择制造商后才能输入到期日期。如果给予同意的人与收到陈述的人不同,则应使用有关同意治疗文件的本地政策。此信息将包含在DH687表格,诊所记录卡以及VIS收件人的名称中。•制造商,数量和到期日期:当疫苗接种VFC符合VFC,并且给定的日期在最后30天内时,这些是必需的;否则,这些字段是可选的。