XiaoMi-AI文件搜索系统
World File Search SystemVisio

教授加里玛·加伊
Aperia 不断发展,成为各行各业 ETL、BI 和托管解决方案的卓越提供商。Aperia 平台随行业发展而扩展,可按时处理大量数据。软件即服务 (SaaS) 平台支持数百万最终用户每天创建数十亿笔交易,且速度和可靠性均符合业务要求。 确保所有工件均符合公司 SDLC 政策和指南。 使用需求管理工具 Requisite Pro 准备 BRD 并将其转换为功能规范。 使用 MS Visio 创建 UML 图,例如用例图、活动图和序列图。 使用建模工具设计数据流图 (DFD)、实体关系图 (ERD) 和网页模型。 使用 MS Project 制定和维护项目计划。确保所有交付成果都能在截止日期前交付。 促进与个人、客户组和技术部门的 JAD 会议。 使用 MS Visio 执行面向对象分析 (OOA) 设计并开发工作流程图。 创建风险分析文档和风险管理计划。 进行功能演练并监督客户用户手册的开发。 为员工提供产品和应用程序培训。 维护变更请求文档并实施测试变更的程序。确保变更符合最终结果。 为用户验收测试 (UAT) 提供技术和程序支持。 北德克萨斯大学,德克萨斯州,美国 2009 年 1 月 - 2010 年 12 月 职位:研究分析师 1155 Union Circle Denton, TX 76203,美国

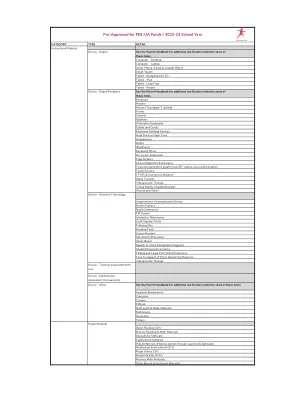
已获得 FES-UA 资金预批准/2022-23 学年
Abeka Academy(仅限课程) Adapted Mind ALEKS 迈阿密大主教区虚拟天主教学校(仅限课程) Brave Writer Dreambox Learning Homeschool in the Woods Institute for Excellence in Writing(仅限课程) i-Ready(仅限课程) IXL Math/语言艺术 Mango Languages Middlebury Interactive Languages Mr. D Math 全国儿童发展协会 PCI Reading Materials Premier Make-Up Artistry Course ReadingKingdom.com Semple Math Smart Tutor 教育计划 So Happy to Learn Starfall Teachtown The Learnables Typing Instruction for Kids Verticy Learning(仅限课程) Visio Makeup Academy 专业服务
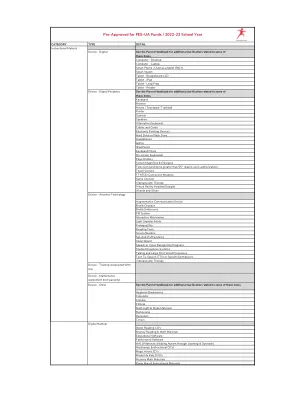
已获得 FES-UA 资金预批准/2022-23 学年
Abeka Academy(仅限课程) Adapted Mind ALEKS 迈阿密大主教区虚拟天主教学校(仅限课程) Brave Writer Dreambox Learning Homeschool in the Woods Institute for Excellence in Writing(仅限课程) i-Ready(仅限课程) IXL Math/语言艺术 Mango Languages Middlebury Interactive Languages Mr. D Math 全国儿童发展协会 PCI Reading Materials Premier Make-Up Artistry Course ReadingKingdom.com Semple Math Smart Tutor 教育计划 So Happy to Learn Starfall Teachtown The Learnables Typing Instruction for Kids Verticy Learning(仅限课程) Visio Makeup Academy 专业服务

OpenLNS 调试工具用户指南
OpenLNS 调试工具 (OpenLNS CT) 是一个软件包,用于设计、安装和维护多供应商、开放、可互操作的 L ON W ORKS ® 控制网络。OpenLNS CT 基于 Echelon 的 OpenLNS 网络操作系统,将对开放 L ON W ORKS 控制网络的支持与用户友好的 Microsoft Visio 界面相结合。结果是,该软件工具足够强大,可以与您的所有设备配合使用,同时又足够经济,可以作为操作和维护工具使用。OpenLNS CT、OpenLNS Server 和 OpenLNS SDK 是 OpenLNS 的三个主要组件。OpenLNS CT 符合 OpenLNS 插件标准,并且与 LNS 插件标准兼容,因此它与 Echelon 和许多其他供应商提供的各种插件兼容。

空间/真空环境下酚醛球轴承保持架测试
这是一种非接触式光学测量系统,可通过针对每种保持器设计的特定程序将平均尺寸拟合到数百次光学测量中。本文中使用的所有测量(包括 2012 年的先前数据和当前测试)均使用相同类型的湿度柜和相同的 Visio 测量系统完成。在当前测试中进行的每次测量中,每个保持器都独立从湿度室中取出。之前的 2012 年数据被用作参考比较,测试时并未完整记录用于此测试的确切程序。图 2 和图 3 显示了湿度柜和测量孔和 OD 视觉系统以供参考。两个系统都紧挨着放在一个公共工作台上,以限制超出参考湿度条件的时间。

系统分析与设计
Apple 和 Macintosh 是 Apple Computer 的注册商标。1Password 是 Agile Web Solutions 的注册商标。Bento 是 FileMaker 的注册商标。Dragon NaturallySpeaking 是 Nuance 的注册商标。Dreamweaver、Adobe Flash 和 FormFlow 是 Adobe Systems Incorporated 的注册商标。DEVONagent 和 DEVONthink Professional Office 是 DEVONtechnologies 的注册商标。Firefox 是 Mozilla Foundation 的商标。Freeway Pro 是 Softpress Systems 的注册商标。HyperCase 是 Raymond J. Barnes、Richard L. Baskerville、Julie E. Kendall 和 Kenneth E. Kendall 的注册商标。Microsoft Windows、Microsoft Access、Microsoft Word、Microsoft PowerPoint、Microsoft Project、Microsoft Excel 和 Microsoft Visio 是 Microsoft Corporation 的注册商标。OmniFocus 是 The Omni Group 的注册商标。OmniGraffle 和 OmniPlan 是 The Omni Group 的注册商标。 OmniPage 是 Nuance 的商标。Palm 是 Palm, Inc. 的注册商标。ProModel 和 Service Model 是 ProModel Corporation 的注册商标。Things 是 Cultured Code 的注册商标。VMware Fusion 是 VMware 的注册商标。Visible Analyst 是 Visible Systems Corporation 的注册商标。WinFax Pro 和 Norton Internet Security 是 Symantec 的注册商标。Yojimbo 是 Bare Bones Software 的注册商标。本文提及的其他产品和公司名称可能是

课程(2025年1月)
务实的半导体2023年7月 - 2023年9月IC设计实习生,英国剑桥•在务实的新兴应用程序(EA)在剑桥科学公园工作了13周。•使用Cadence Virtuoso和Pragmatic的Helvellyn PDK用于灵活电子产品的模拟和数字设计。•工作包括一个精确而紧凑的SAR ADC,其中包含R-2R或电阻弦DAC,以及其随附的数字SAR逻辑,模拟比较器和级别转换器以及其他各种布局。Qualcomm Technologies 2022年6月 - 2022年9月临时工程实习生,英国•进一步的IC设计(例如,通过IEEEXPLORE研究了最先进的学术论文,使用Cadence Virtuoso使用Cadence Virtuoso,使用Cadence Virtuoso。•进行了各种电路模拟(例如DC,瞬态,安全操作区域和ANSYS图腾),用于高通公司的下一代语音和音乐单元,并在设计审查演示文稿中介绍了最终结果。•根据高通公司的标准为所有设计和测试创建了清晰详细的文档。•完成了对高通公司现有温度传感器前端的个人错误贡献的分析,以及这些分析将如何受到随后的信号处理电路和ADC的影响。•分别用于团队合作和图表设计的Atlassian Confluence/Jira和Microsoft Visio。高通技术2021年6月 - 2021年9月临时工程实习生•IC设计(例如使用电力管理单位团队中的Cadence Virtuoso的低频RC振荡器)。•单元格布局(例如•执行的电路可行性测试参考了IEEXPLORE和现有高通IP的学术论文。紧凑的蛇形电阻器)的开发和优化。ARC Instruments 2020年7月 - 2020年9月本科实习生•使用ARCOne®Memristor表征平台开发了基于UDP的RRAM实验的Python程序(带有QT5 GUI)。•使用Dresden中的VPC测试了UDP通信,并记录了结果位错误率。•将我的工作介绍给电子领域中心(以前在南安普敦大学)。

学生顶点实习的教师顾问:
Maya Dumesh Attachmate ('98) 文件定位引擎 Mike Oranski At&T Wireless ('98) Java LDAP 代理服务器 Jeff Fairman Pub Services, UW ('98) Web 内部逻辑 (WIL) Quang Nguyen A&S Computing, UW ('98) 基于 Web 的在线课堂日程安排日历 Ensieh Ensanfar Smith Industries ('98) 建筑管理软件 (Con Man) Bhuvana Sundaresan Sequel Technology ('98) 记录和开发 Sequel Internet Resource Manager (TM) Sherry Strickland Eddie Bauer ('98) 产品数据管理 (PDM) 集成设计试点 Brian Brewder 美国 Web (Winter'99) 面向 Microsoft Beta 组的三层基于 Web 的数据库应用程序 Brian Yangas 美国 Web (Winter'99) DB2000 服务器应用程序 Tony Mael Microsoft (Winter'99) 软件开发和软件测试方法 Jason Holzer Du Voice (Winter'99) 语音邮件设置生成器 (VMset) Liz Anderson Attachmate (Spring’99) Quevue 2 客户端/服务器应用程序 William Haase Stormpetrel Prod 拨号网络扩展 (DUNE),(Spring’99) 拨号 ISP 软件 Rob McKeever ATL Ultrasound (Summer’99) 超声波图像的彩色能量分析 (CPA) Forrest Hurley Attachmate (Summer’99) 开发人员支持示例数据库项目 Ron Grant Microsoft (Summer’99) 自动化 MSDN 库手动 UI 验证和确认 John Keck Real Networks (Summer’99) 互联网广告插入服务器和同步多媒体集成语言 (SMIL) 应用程序 Karen Kotz Asymetrix (Fall’99) 管理学生培训 Ma 的开发和生产