XiaoMi-AI文件搜索系统
World File Search SystemYes


scn_for_ar_filing_fy_22_233.pdf
177 SANDEEP MITTAL Importer NO 0 0 0 0 0 17500 YES 0 0 0 0 0 0 0 178 SHINTO CORPORATION Importer NO 0 0 0 0 0 17500 YES 0 0 0 0 0 0 0 179 VNS INTERNATIONAL Importer NO 0 0 0 0 0 17500 YES 0 0 0 0 0 0 0

PSERB决议2025-02卫生保健委员会2025工作计划2025年1月10日
C.建议批准关键决策:1。向董事会提出有关更改健康保险计划和保费援助计划的建议,包括但不限于对退休人员提供的福利类型或水平的更改以及健康保险计划的范围;并应为健康保险和保费援助计划推荐年度行政预算。Proposed 2026 HOP Medical and Medicare Rx Plans and Rates: Approve proposed 2026 HOP Medical Plan & Rates 6/12/25 No Annually Yes Yes x Approve proposed 2026 HOP Value Medical Plan & Rates 6/12/25 No Annually Yes Yes x Approve proposed 2026 HOP Pre-65 Medical Plan & Rates 6/12/25 No Annually Yes Yes x Approve proposed 2026 HOP Standard Medicare Part D Rx Plan & Rates 6/12/25否每年是是是X批准拟议的2026 Hop Premium Medicare D RX计划和费率6/12/25否每年是是是是是
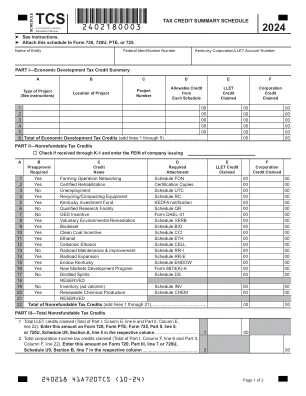
时间表TCS 2024
a b c c d e f要求的信用要求llet信贷公司要求的名称附件要求索赔1是农业运营网络网络时间表fon 00 00 00 00 00 00 00 00 2是否00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 4是,kentifitiviation no Revery Infectivition no Revientifition Fure Investion 00 Y YES Kentucky Investment Y YES KENTUCKY INVENTION RC kentucky Investment 00 QR 00 00 7 No GED Incentive Form DAEL-31 00 00 8 Yes Voluntary Environmental Remediation Schedule VERB 00 00 9 Yes Biodiesel Schedule BIO 00 00 10 Yes Clean Coal Incentive Schedule CCI 00 00 11 Yes Ethanol Schedule ETH 00 00 12 Yes Cellulosic Ethanol Schedule CELL 00 00 13 No Railroad Maintenance & Improvement Schedule RR-I 00 00 14 Yes Railroad Expansion时间表RR-E 00 00 15是endow Kentucky时间表endow 00 00 16是新市场开发计划表格8874(k)-A 00 00 00 17否蒸发烈酒时间表DS 00 00 18保留19 no库存(AD VAROREM)(AD VAROREM) 21).................................................................................................. 00 00

创伤恢复和康复计划
Continent – Bowel: Yes No Bladder: Yes No Details/assistive aids used: ...........................................................................................................................................................................................................................................Medication management: Independent Requires assistance Details/assistive aids used: ...........................................................................................................................................................................................................................................

华盛顿州的人类prion病,2014 - 2023年人类prion疾病增强了监视华盛顿州年度报告
1 npdpsc> 20,000 124,692正否推定零星可能的可能2 npdpsc> 20,000 53,476阳性是阳性是偶发性的3 npdpsc> 20,000> 20,000> 20,000> 160,000> 160,000否否否否假定偶发性的可能4 npdpsc 11,625 88,341 sporite sporitce sporite sporite sporite sporite sporite 5 npdps sporite 5 npdd spordite 5 npddpd spordient dictite 5 npdd sporadic sporadient 5 npddd sporadient sporadic sporadic sporadient 5 No Presumed sporadic Probable 6 NPDPSC >20,000 >160,000 Positive Yes Sporadic Definite 7 NPDPSC 11,561 58,190 Positive Yes Familial Definite 8 NPDPSC 2,821 26,658 Positive Yes Sporadic Definite 9 NPDPSC >20,000 >160,000 Positive Yes Sporadic Definite 10 NPDPSC 14,414 47,858 Positive Yes Sporadic Definite 11 None N/A N/A N/A Yes Sporadic Definite 12 NPDPSC >20,000 115,296 Positive No Presumed sporadic Probable 13 None N/A N/A N/A No Presumed familial Probable 14 NPDPSC 8,202 34,341 Positive Yes Sporadic Definite 15 NPDPSC >20,000 106,795 Positive Yes Sporadic Definite *rt-Quic(实时Quaking引起的转换)于2015年4月在NPDPSC上发售。它是在阳性14-3-3蛋白或T-TAU下进行反射测试的,值为500 pg/ml或更高2015-2019。rt-quic在2019年1月开始对所有样品进行。CJD偶发,家族,医源性和变体CJD案例定义的案例定义请参见:http://wwwww.cdc.gov/prions/prions clions cjd/cjd/cjd/cjd/cjd/cjd/ccriteria.http://

88(r)HB 1181
编号1181,2023年5月25日,通过以下投票:AA YES 133,NAYS 1,1181,2023年5月25日,通过以下投票:AA YES 133,NAYS 1,

(公共包)补充5-项目8
AA Revenue and Capital Budget and Council Tax 2025/26 to Executive B(i) New Savings B(ii) 2024/25 Savings for delivery in 2025/26 B(iii) All Savings C New Growth D Proposed Revenue Budget 2025/26 E MTFP Movements since October 2024 Executive F MTFP Five Year Projections G Medium Term Financial Strategy 2025/26 – 2029/30 H Fees and Charges for approval 2025/26 I Specific Revenue Grants Schedule 2025/26 J(i) Dedicated Schools Grant (DSG) Forecast spend J(ii) Summary DSG Settlement 2025/26 K Parking Account 2025/26 L Cumulative Equalities Impact Assessment M 2025/26 Budget Consultation Feedback N Earmarked Reserves Forecast O Capital Investment Strategy 2025/26 P New Capital Schemes Q(i) Capital Programme摘要2024/25-2029/30 Q(ii)资本计划完整方案2024/25-2029/30 R(I)国库管理策略,包括保诚指标R(ii)最低收入策略的资本收到的最低收入策略策略策略t non-tran-transury Investmer Investment Investment Investment Investment Investment策略的税收策略2025/26 U型委员会

平衡的装袋分类器机器学习模型 -
Features n % Median Mean Standard deviation Chemotherapy cycles 3439 100 General Cancer type Breast cancer 1315 38 Lung cancer 890 26 Colorectal cancer 1159 34 Other cancers 75 2 Stage 1 to 3 1927 4 1512 Involved systems number* 0 0.8 1.1 Gender Female 1811 53 Male 1628 47 Age 55 55.1 11.4 ECOG performance status 1 0.7 0.7 Coronary disease No 3133 91 Yes 306 9慢性阻塞性肺疾病(冷)否3252 95是187 5放疗3372 98在3372 98之前没有接受67 2先前的化疗NO 1922 56是1517 44治疗治疗方法作为住院NO 3240 94是3240 94是3240 94 YES 199 6 CSF YES 199 6 CSF否2543 74 YES 896 26 26 26 26 26 NO 311 NO 311 NO 311 11 11 1117剂量重新降差 neutropenia No 3211 93 Yes 228 7 Febrile neutropenia after chemotherapy No 3306 96 Yes 133 4 Drug number** 1 336 10 2 1644 48 3 1076 31 4 382 11 5 1 0 Regimen risk*** 1 938 27 2 2157 63 3 344 10 Cycle no on current protocol 3 2.8 1.4 Laboratory LDH (IU/ml) 343 370 235 ALT (IU/mL)18 22 20 20肌酐(mg/dl)0.71 0.76 0.22淋巴细胞计数(x1000/mm3)1.7 1.7 1.9 1.3白蛋白(mg/dl)4.2 4.2 4.2 0.4

巨人/马丁斯药房covid-19疫苗知情同意书:
Copy sent to provider: YES □ NO □ Certificate of Immunization given to patient: YES □ NO □ Registry checked to confirm COVID dose number/product: YES □ NO □ Date: ____________ Product: ____________ I have reviewed the Vaccine Screening Questionnaire to assess the patient for potential contraindications and precautions to the vaccines being administered today.我已经确认要求的疫苗为患者指示。RPh Initials: _____ Pharmacist/Intern/Technician Name: _____________________________ Title: _________ Date: ______________ Pharmacist/Intern/Technician Signature: __________________________ NPI: ______________________________ Location of Pharmacy/Administration: ____________________________________ Phone: ____________________