XiaoMi-AI文件搜索系统
World File Search Systemgpu

GPU 加速药物研发与 Summit 超级计算机对接:移植、优化和应用于 COVID-19 研究
蛋白质-配体对接是一种计算机模拟工具,用于在药物发现活动中筛选潜在药物化合物与给定蛋白质受体结合的能力。实验性药物筛选成本高昂且耗时,因此需要以高通量的方式进行大规模对接计算以缩小实验搜索空间。现有的计算对接工具中很少有考虑到高性能计算而设计的。因此,通过优化最大限度地利用领先级计算设施提供的高性能计算资源,可以使这些设施用于药物发现。在这里,我们介绍了 AutoDock-GPU 程序在 Summit 超级计算机上的移植、优化和验证,以及它在针对导致当前 COVID-19 大流行的 SARS-CoV-2 病毒蛋白的初步化合物筛选工作中的应用。1

Qualcomm®应用程序处理器选择器指南
•Spectra 480图像信号处理器旨在提供高级相机体验,可以通过高性能捕获200兆像素的照片,8k视频录制和4K HDR视频捕获•Adreno 650视觉处理子系统的高质量捕获,可用于使用较大的Imbersive Experiess(GPU)(GPU)(GPU)(GPU)(GPU)(GPU) 698 DSP with HVX, Hexagon Tensor Accelerator and Hexagon Scalar Accelerator to support sophisticated, on- device AI processing, and delivers mobile- optimized computer vision (CV) experiences for a wide array of use cases • Kryo 585 CPU: Manufactured in 7 nm process node, optimized across four high- performance Kryo Gold cores and four low- power Kryo Silver cores • Qualcomm® Secure处理单元提供了卓越的安全性,旨在帮助保护您的面部数据,虹膜扫描和其他生物识别数据。它支持信任的硬件根,Qualcomm Tee,Secure Boot和Camera Security•随着产品寿命计划的预期,预计到2035年9月的长期支持

质子辐照下 NVIDIA Xavier SoC 系列的单粒子效应来源
摘要 — 在本文中,我们使用质子束描述了 NVIDIA Xavier 系列片上系统 (SoC) 中的两个嵌入式 GPU 设备。我们比较了分别针对商业和汽车应用的 NVIDIA Xavier NX 和工业设备。我们使用不同的功率模式评估了两个模块及其子组件(CPU 和 GPU)的单粒子效应 (SEE) 率,并首次尝试使用其基于 ARM 的系统中包含的在线测试工具来识别它们的确切来源。我们的结论是,SoC 的 CPU 复合体中最敏感的部分是各种缓存结构的标签阵列,而在 GPU 中没有观察到任何错误,可能是因为在辐射活动期间,与应用程序的 CPU 部分相比,它的执行速度更快。

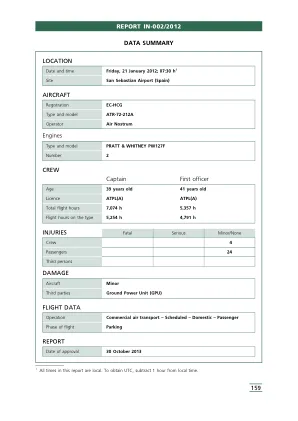
报告 IN-002/2012 159 位置飞行数据...
右发动机启动后,机长示意协调员断开 GPU。然后,他启动了左发动机的启动程序,该发动机没有螺旋桨制动器。一旦该发动机稳定下来,他们就松开了右发动机上的螺旋桨制动器。然后机长示意协调员移除轮挡。她又将这个命令传达给操作员,操作员移除轮挡,将它们放在拖车上。当他进入卡车移动 GPU 时,他听到了尖叫声,并注意到飞机正在向前移动,其右螺旋桨即将撞击 GPU,因此他迅速离开。

55使用英特尔的新内置AI加速引擎
与前一代CPU相比,NUPIC对变压器结构的变化最小,在具有Intel AMX的CPU上的推理吞吐量的两个数量级提高了两个数量级的改善,与GPU相比,相比之下(表1)。对于Bert-Large来说,我们在Intel Xeon上的平台的表现优于Nvidia A100 GPU,最高可达17倍。GPU需要更高的批量大小才能达到最佳平行性能。但是,批处理导致更复杂的推理实现,并在实时应用程序中引入了不良延迟。相比之下,Nupic不需要批处理以进行高性能,从而使应用程序灵活,可扩展且易于管理。尽管批处理不利,但我们列出了批次8的NVIDIA A100的性能。批次1的nupic仍然比批处理的NVIDIA GPU实现超过2倍。
![arxiv:2502.11110V1 [CS.CR] 2025年2月16日](/simg/c\c8ed3f17197796789e20c76f9924d994671e5f1e.webp)
arxiv:2502.11110V1 [CS.CR] 2025年2月16日
同态加密(HE)是隐私机器学习(PPML)中的核心建筑块,但他也被广泛称为其效率瓶颈。因此,已经提出了许多GPU加速的加密方案来提高HE的性能。但是,这些方法通常需要针对特定算法量身定制的复合修改,并与特定的GPU和操作系统紧密耦合。询问如何通常提供更实用的GPU加速算法的信息很有趣。鉴于大语言模型(LLMS)的强大代码通用功能,我们旨在探索它们的潜力,即使用CPU友好型代码自动生成实用的GPU友好算法代码。在本文中,我们关注数字理论转移(NTT) - HE的核心机制。我们首先开发并优化了对GPU友好的NTT(GNTT)家族,该家族利用了Pytorch的快速计算和预录,并实现了大约62倍的加速,这是一个大约62倍的加速,这是一个明显的增长。然后,我们使用各种LLM,包括DeepSeek-R1,Ope-Nai O1和O3-Mini探索GPU友好的代码生成。在整个过程中,我们发现了许多涉及的发现。例如,有些令人惊讶的是,我们的经验表明,DeepSeek-R1的表现明显优于OpenAi O3-Mini和O1,但仍然无法击败我们优化的协议。这些发现为ppml的PPML提供了宝贵的见解,并增强了LLMS的代码生成能力。代码可在以下网址提供:https://github.com/lmpc-lab/ gengpucrypto。

HESAI Group(Hsai US)
GB300/GB300A服务器规格设置为更改。 我们认为即将到来的GB300/300A服务器将以3Q25E的质量生产为特色。 关键更改包括:1)LPDDR CAMMS和GPU插座:GB300将采用LPDDR CAMM和GPU插座来降低GPU失败成本和供应链风险。 2)X86 CPU替代方案:服务器将合并X86 CPU替代方案,该替代方案仍需要PCI-E接口。 3)增加机架功率消耗:每个机架的总功耗将增加到130-140kW,而B300服务器的功率为1.4kW(B200为1.2kW)。 4)可选的电容器机架和BBU:GB300/GB300A服务器可以选择采用电源电容器机架和电池备用单元(BBU)。 5)灵活的组件供应商:GB300/GB300A服务器将在组件供应商选择方面具有更大的灵活性。GB300/GB300A服务器规格设置为更改。我们认为即将到来的GB300/300A服务器将以3Q25E的质量生产为特色。关键更改包括:1)LPDDR CAMMS和GPU插座:GB300将采用LPDDR CAMM和GPU插座来降低GPU失败成本和供应链风险。2)X86 CPU替代方案:服务器将合并X86 CPU替代方案,该替代方案仍需要PCI-E接口。3)增加机架功率消耗:每个机架的总功耗将增加到130-140kW,而B300服务器的功率为1.4kW(B200为1.2kW)。4)可选的电容器机架和BBU:GB300/GB300A服务器可以选择采用电源电容器机架和电池备用单元(BBU)。5)灵活的组件供应商:GB300/GB300A服务器将在组件供应商选择方面具有更大的灵活性。

NVIDIA Blackwell GeForce RTX 50系列开启AI计算机图形新世界
本新闻稿中的某些声明包括但不限于有关以下内容的声明:NVIDIA 产品、服务和技术的优势、影响、性能和可用性,包括 GeForce RTX 50 系列台式机和笔记本电脑 GPU、NVIDIA Blackwell 架构、第五代 Tensor Core、第四代 RT Core、GeForce RTX 5090 Founders Edition GPU、NVIDIA DLSS 4、NVIDIA Reflex、DLSS 多帧生成、DLSS 超分辨率和光线重建模型、NVIDIA Reflex 2、RTX 神经着色器、RTX Neural Faces、RTX Mega Geometry、ACE 技术、NVIDIA NIM 微服务、Project R2X、RTX 40 系列 GPU、NVIDIA RTX Remix 改装平台和 D5 Render、NVIDIA Broadcast、Studio Voice、Virtual Key Light、GeForce Blackwell、NVIDIA Max-Q 技术、GeForce RTX 5090、GeForce RTX 5080、GeForce RTX 5070 Ti、GeForce RTX 5070、GeForce RTX 5090 笔记本 GPU、GeForce RTX 5080 笔记本 GPU、GeForce RTX 5070 Ti 笔记本 GPU、GeForce RTX 5070 笔记本 GPU;以及采用 NVIDIA 产品和技术的第三方均为前瞻性陈述,受风险和不确定性的影响,这些风险和不确定性可能导致结果与预期存在重大差异。可能导致实际结果出现重大差异的重要因素包括:全球经济状况;我们对第三方制造、组装、包装和测试产品的依赖;技术发展和竞争的影响;新产品和技术的开发或现有产品和技术的增强;市场对我们产品或合作伙伴产品的接受度;设计、制造或软件缺陷;消费者偏好或需求的变化;行业标准和接口的变化;我们的产品或技术集成到系统中时性能意外下降;

用于大脑模拟的低延迟通信设计
摘要 — 大脑模拟是人工智能领域的最新进展之一,它有助于更好地理解信息在大脑中的表示和处理方式。人脑极其复杂,因此只有在高性能计算平台上才能进行大脑模拟。目前,具有大量互连图形处理单元 (GPU) 的超级计算机用于支持大脑模拟。因此,超级计算机中的高吞吐量低延迟 GPU 间通信对于满足大脑模拟这一高度时间敏感的应用的性能要求起着至关重要的作用。在本文中,我们首先概述了当前使用多 GPU 架构进行大脑模拟的并行化技术。然后,我们分析了大脑模拟通信面临的挑战,并总结了应对这些挑战的通信设计指南。此外,我们提出了一种分区算法和一种两级路由方法,以实现多 GPU 架构中用于大脑模拟的高效低延迟通信。我们报告了在一台拥有 2,000 个 GPU 的超级计算机上模拟具有 100 亿个神经元的大脑模型的实验结果,以表明我们的方法可以显著提高通信性能。我们还讨论了尚待解决的问题,并确定了大脑模拟低延迟通信设计的一些研究方向。