XiaoMi-AI文件搜索系统
World File Search Systemprediction

变压器心脏病预测的优化
针对最新的粒子群优化算法,本文提出了一种改进的跨前模型,以提高心脏病预测的准确性,并基于粒子群优化(PSO)提供了一种新的算法想法。我们首先使用三个主流机器学习分类算法 - 决策树,随机森林和XGBoost,然后输出这三个模型的混淆矩阵。结果表明,随机森林模型在预测心脏病的分类方面具有最佳性能,精度为92.2%。然后,我们将基于PSO算法的变压器模型应用于分类实验的同一数据集。结果表明,该模型的分类精度高达96.5%,比随机森林高4.3%,这验证了PSO在优化变压器模型中的有效性。上述研究表明,PSO在心脏病预测中显着改善了变压器的性能。提高预测心脏病的能力是全球优先事项,对所有人类的益处。准确的预测可以增强公共卫生,优化医疗资源并降低医疗保健成本,从而导致更健康的社会。这一进步为更有效的健康管理铺平了道路,并为更健康,更具韧性的全球社区的基础提供了帮助。

预测院外心脏骤停的生存
1哥德堡大学医学院分子与临床医学系,沃伦伯格大学,蓝弦蓝弦5,楼梯H楼梯H,Sahlgrenska大学医院,瑞典413 45; 2 Sahlgrenska大学医院心脏病学系,BlueStråket5,VästraGötaland县,瑞典哥德堡4545; 3临床医学系,医学院Solna,Karolinska Institutet,Framsgatan,171 64 Solna,瑞典; 4 Sahlgrenska University Hospital,BlueStråket5,413 45 Gothenburg,瑞典萨尔格伦斯卡大学医院45; 5 Sahlgrenska Academy临床科学学院的麻醉和重症监护系,哥德堡大学,BlueStråket5,413 45 Gothenburg,瑞典; 6复苏科学中心,临床科学与教育系,Karolinska Institutets,Södersjukhuset,Jägargatan20,楼梯1,171 77瑞典斯德哥尔摩; 7功能围手术医学和Intite Care,Karolinska大学医院,Tomtebodavägen18,171 76瑞典斯德哥尔摩; 8瑞典登记处的心肺复苏登记处,医学街18G,413 90哥德堡,瑞典

基于网络药理学的预测与验证...
基于GO注释,进行GO富集分析,识别13个靶点的共同特征。与三个本体(CC、BP和MF)的处方靶点显著相关的GO术语数量分别为615、602和458个[21]。主要的BP术语包括对凋亡过程的负调控、对药物的反应、对序列特异性DNA结合转录因子活性的正调控、对糖皮质激素的反应以及对原生动物的防御反应。主要的CC术语包括细胞质、细胞核、细胞溶胶、细胞外区域和核质。主要的MF术语包括蛋白质结合、相同蛋白质结合、酶结合、转录因子结合和ATP结合。这些BP、MF和CC与CRC的治疗密切相关,GO富集分析结果如图4所示。

ADC 在预测 125I 治疗中的临床重要性...
目的:确定最小表观扩散系数 (minADC) 值是否可以对接受 125 I 近距离放射治疗的胶质瘤患者的生存进行分层。方法:本研究经机构审查委员会批准,无需知情同意。本研究纳入了 23 名高级别胶质瘤 (HGG) (n=9) 或多模式治疗后复发 (n=14) 患者(16 名男性,7 名女性;中位年龄 48 岁)。在 125 I 植入前获取 minADC 值。使用 Cox 比例风险回归模型和 Kaplan-Meier 方法及对数秩检验分析总生存期 (OS) 和无进展生存期 (PFS)。结果:对于接受125I治疗的患者,ADC≥1.0*10^ -3 mm 2 ·sec -1(高minADC)患者与ADC<1.0*10^ -3 mm 2 ·sec -1(低minADC)患者的OS风险比为0.220(95%可信区间:0.066,0.735)。高minADC值患者的中位OS为12个月,低minADC值患者的中位OS为6.0个月,差异有统计学意义(p=0.032)。高minADC值患者的中位PFS为12个月,低minADC值患者的中位PFS为4个月,长秩检验显示差异有统计学意义(p=0.013)。多因素分析结果显示,125I植入前minADC是接受125I近距离治疗患者OS和PFS的独立预测因素。结论:125I植入前ADC分析可以对125I治疗的胶质瘤患者的预后进行分层,这可能有助于为胶质瘤患者选择合适的治疗方法。

蛋白质结构预测的量子加速
I。PSP的目的是预测蛋白质折叠过程的乘积。蛋白质(氨基酸的线性序列)折叠以假定其天然的三维构象。热力学假设[2],[3]指出,蛋白质的天然构象是其热力学上最稳定的构象,并且除了一些极少数例外,它不取决于细胞内或试管中的蛋白质折叠[4]。这一事实,结合了蛋白质的三维结构及其功能之间建立的联系,可以通过增强目前主要的试验和异常实验,并使用计算机模拟来检测硅胶中有很大的药物问题,从而在医学中加速药物发现。

财务泡沫的预测和交易进行了回测...
在我们的现代社会中,财务泡沫通常需要引起巨大的后果。在我们的研究中,我们专注于通过从不同理论中汲取的财务泡沫来定义财务泡沫。我们的工作集中在日志周期性幂律奇异性模型上,该模型将泡沫描述为价格比价格更快的价格级数的增长速度,而价格序列始终是在财务崩溃中。在定义模型理论,其校准并描述了如何通过此模型生成指标后,我们用它来复制文学的一些众所周知的结果。我们在2014年和2015年重现了中国股市SSEC中泡沫的分析。能够预测一个泡沫,然后我们专注于使用LPPLS模型实施交易策略。此后,我们提出了一项策略,该战略在LPPLS置信指标检测到正泡沫时进行投资,而LPPLS信任指标检测到即将崩溃的负泡沫时。然后,在不同类别的资产和财务气泡上测试该策略。结果,我们的分析证明了该方法的效率。此外,我们通过添加不同的功能来增强策略,当我们获得强大的积极LPPLS信任指标信号时离开市场。我们最终添加了一个平均的真实范围策略,以进行大小交易,然后根据我们可以接受的最大损失来调整位置。这些研究是对不同AS组进行的,但是,经常使用加密货币,尤其是比特币来描述整个工作中的策略。

通过词语预测自动校准 c-VEP BCI
摘要。代码调制的视觉诱发电位脑机接口 (c-VEP BCI) 允许从闪烁字符的虚拟键盘进行拼写。所有字符同时闪烁,每个字符根据预定义的伪随机二进制序列闪烁,循环移位不同的时间滞后。对于给定的字符,伪随机刺激序列会在受试者的脑电图 (EEG) 中唤起 VEP,可将其用作模板。此模板通常在校准阶段获得,并在拼写阶段应用于目标识别。c-VEP BCI 系统的一个缺点是它需要较长的校准阶段才能达到良好的性能。本文提出了一种无监督方法,通过从连续字符之间的 VEP 响应中提取相对滞后并使用字典预测完整单词,避免了 c-VEP BCI 中的校准阶段。我们在公共数据集上进行了离线实验。我们模拟了从英语词典中选择的四组单词的拼写,这些单词的总字符数不同。每个实验都由刺激周期数参数化。所得结果表明,基于单词预测的 c-VEP BCI 自动校准方法可以高效且有效。

174 个 SARS-CoV-2 表位的预测与验证
最近爆发的 SARS-CoV-2 (2019-nCoV) 病毒凸显了快速有效疫苗开发的必要性。刺激导致保护的适当免疫反应高度依赖于通过 HLA 复合物向循环 T 细胞呈递表位。SARS-CoV-2 是一种大型 RNA 病毒,体外测试所有重叠肽以反卷积免疫反应是不可行的。因此,通常使用 HLA 结合预测工具来缩小要测试的肽的数量。我们测试了 15 种表位-HLA 结合预测工具,并使用体外肽 MHC 稳定性测定法,我们评估了 777 种预测为 11 种 MHC 同种异型良好结合剂的肽。在这项对潜在 SARS-CoV-2 表位的研究中,我们发现当前的预测工具在评估结合稳定性时的性能各不相同,并且它们高度依赖于所讨论的 MHC 同种异型。因此,设计一种仅包含少数表位靶标的 COVID-19 疫苗是一项非常具有挑战性的任务。在这里,我们展示了 174 个具有高预测结合分数的 SARS-CoV-2 表位,这些表位经验证可与 11 种 HLA 同种型稳定结合。我们的研究结果可能有助于设计一种有效的 COVID-19 疫苗。

空间碎片跟踪和预测模型
一、引言 航天技术的飞速发展导致运行中的航天器数量显著增加,而这些航天器现在面临着来自太空垃圾的严重威胁。这些碎片主要来自频繁的发射活动,导致卫星和其他太空资产的风险越来越大。截至 2022 年 3 月,美国太空监视网络 (SSN) 已记录了大约 25,000 件太空碎片、报废航天器和活跃卫星,预计这一数字还将持续上升。与大型碎片的碰撞会彻底摧毁航天器,而即使是高速飞行的小碎片也会造成严重损坏,导致性能下降或完全失灵。因此,有效跟踪和预测空间碎片对于保护运行中的航天器和确保太空探索的可持续性至关重要。空间碎片跟踪不仅需要检测空间碎片的存在,还需要预测其轨迹以减轻碰撞。空间碎片跟踪系统一般可分为地面系统和天基系统,每种系统都有其优点和局限性。地面系统使用地面上的望远镜和雷达,但受到天气条件和地球自转的限制。太空系统使用卫星或航天器上的传感器,可以更可靠地探测太空垃圾,而不会受到大气的干扰。其中,先进的算法和机器学习方法(例如,Tao 等人,2023 年提出了一种时空显着性网络)
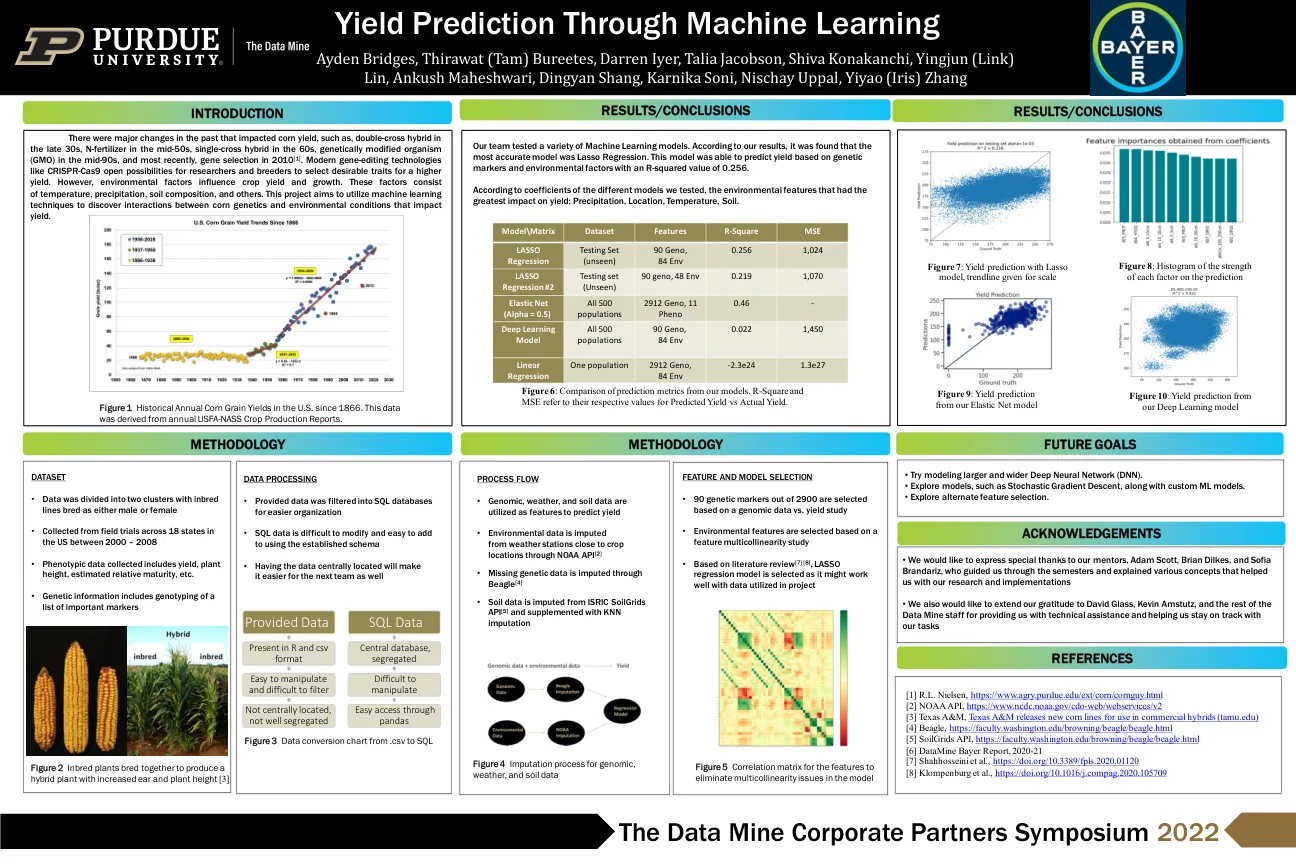
通过机器学习进行产量预测
过去曾发生过影响玉米产量的重大变化,例如 30 年代后期的双杂交种、50 年代中期的氮肥、60 年代的单杂交种、90 年代中期的转基因生物 (GMO),以及最近 2010 年的基因选择 [1]。CRISPR-Cas9 等现代基因编辑技术为研究人员和育种者提供了选择高产理想性状的可能性。然而,环境因素会影响作物的产量和生长。这些因素包括温度、降水、土壤成分等。该项目旨在利用机器学习技术发现影响产量的玉米基因与环境条件之间的相互作用。