XiaoMi-AI文件搜索系统
World File Search Systemsql

oracle®机器学习SQL
美国政府最终用户:Oracle计划(包括任何操作系统,集成软件,任何已嵌入,安装或在交付的硬件上激活的程序,以及此类程序的修改)和Oracle计算机文档或美国政府最终用户提供或访问的其他Oracle数据是“商业计算机软件”,“商业计算机软件”,“商业计算机软件文档”,“商业计算机软件”,“商业计算机软件”,“有限的权利数据”或“有限的权利”适用于适用于适用的适用性,或者适用于适用性的适用性,并适用于适用于适用性。因此,使用,复制,重复,释放,显示,披露,修改,衍生作品的准备和/或适应i)Oracle程序(包括任何操作系统,集成软件,嵌入,安装或激活的任何程序,在此类程序中嵌入或激活的任何程序,对此类程序的限制和其他限制),III和/或III IS IS III和/或/或/或/或/或/或/或/或/或/或/或/或/或/或/或/ii ii III),IS或/或/或/或/或/或/或/或/或/或/或/或III III IS IIS)在适用的合同中。管理美国政府使用Oracle Cloud Services的条款由适用的此类服务的合同定义。没有其他权利授予美国政府。

使用无监督的机器学习方法预防SQL注射攻击
gpadmapriyame@gmail.com,rajiv5757@yahoo.co.in摘要:现在,一天的在线Web应用程序或在线数据库应用程序越来越多地暴露于各种攻击中。这样的一种窃取数据的攻击称为SQL注入攻击,其中攻击者修改用户启动的SQL查询,并添加恶意代码以访问和操纵Web应用程序或数据库中的信息。防止此类攻击的一种方法是定期更新和测试Web应用程序防火墙(WAF)。由于技术的巨大增长,打算攻击应用程序的攻击者找到了许多进入系统的新方法。在本文中,我们将机器学习的概念与WAF结合起来,从而最大程度地提高了现有系统的有效性。本文采用的方法是无监督的机器学习技术,该技术使用K-均值聚类算法。建议的系统的流量可以给出:最终用户在Web应用程序中进行查询,并提取查询值并将其发送到SQL注入检测器,该检测器提供两层安全性。在第一层安全性中,使用无上下文语法(CFG)创建模式,以用于低级攻击。使用无监督的学习算法对高级攻击的第二层安全性进行了训练。关键字:机器学习,无监督学习,SQL注入,WAF,CFG 1。简介Web应用程序防火墙(WAF)从一系列应用程序层攻击(例如跨站点脚本(XSS),SQL注入和Cookie Disuning等)中,将Web应用程序或在线数据库应用程序中的应用。HTTP应用程序使用Web应用程序防火墙(WAF)作为应用程序防火墙。在HTTP对话中,它应用了一系列规则。通常,这些规则允许跨站点等常见攻击

蓝色大象检查熊猫:SQL
抽象数据预处理,将数据转换为适合训练模型的合适格式的步骤,很少发生在数据库系统中,而是在外部Python库中,因此需要首先从数据库系统中提取。但是,对数据库系统进行了调整以进行有效的数据访问,并提供汇总功能,以计算数据(偏见)中某个值的不足或过分代表所需的分布频率。我们认为,具有SQL的数据库系统能够执行机器学习管道,并发现技术偏见(通过数据预处理引起的)有效地。因此,我们提供了一组SQL查询,以涵盖数据预处理和数据检查:在预处理过程中,我们用标识符注释元组以计算列的分布频率。要检查分布更改,我们将预处理的数据集与元组标识符上的原始数据集一起加入,并使用聚合功能来计算每个敏感列的出现数量。这使我们能够检测到过滤元组的操作,从而删除了列的技术偏见,即使已经删除了列。为了自动生成此类查询,我们的实施将Mlinspect项目扩展到以Python编写的现有数据预处理管道到SQL查询,同时使用视图或公共表格表达式(CTES)维护详细的检查结果。评估证明,超出主机数据库系统的现代现代化,即umbra,加速了预处理和检查的运行时。即使是基于磁盘的数据库系统,甚至在实现视图时也显示出与UMBRA的相似性能。

临床试验中用于综合临床和翻译数据管理的开源SQL数据库架构
摘要在肿瘤学中解锁个性化医学的力量,以融合临床试验数据与翻译数据的整合(即生物测试衍生的分子信息)。这种组合分析使研究人员可以为患者独特的生物构成量身定制治疗。但是,英国临床试验单元中的当前做法带来了挑战。虽然以标准化格式保存临床数据,但翻译数据是复杂的,多样的,需要专门存储。这种格式的差异为旨在有效策划,整合和分析这些数据集的研究人员带来了重大障碍。本文提出了一种新颖的解决方案:专门为学术试验单元需求而设计的开源SQL数据库架构。受到英国癌症研究的启发,由南安普敦临床试验单元的确认试验(超过150,000个临床数据点)开放数据共享和举例说明,该模式在原始数据与昂贵的安全数据环境/可信赖的研究环境之间提供了具有成本效益且实用的“中间立场”。通过充当临床和翻译数据的中心枢纽,该模式促进了无缝数据共享和分析。研究人员获得了对试验的整体观点,从而探索了临床观察与治疗反应的分子基础之间的联系。提供了用于设置数据库的详细说明。开源性质和直接设计可确保易于实施和负担能力,而强大的安全性措施可以保护敏感数据。我们进一步展示了研究人员如何利用像R这样的流行统计软件来直接查询数据库。这种方法促进了学术发现社区内的合作,最终加速了进度的个性化癌症疗法。

SQL的Oracle®机器学习 - 用户指南
美国政府最终用户:Oracle计划(包括任何操作系统,集成软件,任何已嵌入,安装或在交付的硬件上激活的程序,以及此类程序的修改)和Oracle计算机文档或美国政府最终用户提供或访问的其他Oracle数据是“商业计算机软件”,“商业计算机软件”,“商业计算机软件文档”,“商业计算机软件”,“商业计算机软件”,“有限的权利数据”或“有限的权限”适用于适用于适用的适用性和适用于适用性的适用性。因此,使用,复制,重复,释放,显示,披露,修改,衍生作品的准备和/或适应i)Oracle程序(包括任何操作系统,集成软件,嵌入,安装或激活的任何程序,在此类程序中嵌入或激活的任何程序,对此类程序的限制和其他限制),III和/或III IS IS III和/或/或/或/或/或/或/或/或/或/或/或/或/或/或/或/ii ii III),IS或/或/或/或/或/或/或/或/或/或/或/或III III IS IIS)在适用的合同中。管理美国政府使用Oracle Cloud Services的条款由适用的此类服务的合同定义。没有其他权利授予美国政府。

genedit:复合操作员和持续改进,以解决企业中的文本到sql
在大型语言模型驱动的文本到SQL的最新进步正在民主化数据访问。尽管有这些进步,但由于需要掌握特定于商业知识,处理复杂的查询并满足持续改进的期望,因此企业部署仍然具有挑战性。为了解决这些问题,我们设计和实施了Genedit:通过用户反馈改进的文本到SQL生成系统。genedit建立并维护特定于公司的知识集,采用分解SQL生成的操作员的管道,并使用反馈来更新其知识集来改善未来的SQL代。我们描述了Genedit的两个核心模块制成的结构:(i)分解的SQL生成; (ii)知识基于用户反馈设置编辑。 对于一代人来说,Genedit利用复合操作员来改善知识检索,并创建一个计划作为指导生成的经过思考的步骤。 genedit首先在初始检索阶段重新研究了相关的示例,在该阶段将原始SQL查询分解为子林,条款或子查询。 然后还检索说明和架构元素。 使用检索到的上下文信息,GenEdit然后以自然语言的逐步计划,涉及如何产生查询。 最后,Genedit使用该计划来生成SQL,最小化模型推理的需求,从而增强了复杂的SQL生成。 必要时,Genedit基于句法和语义错误将查询再生。 每个发电机都使用上述编辑来更新发电提示。我们描述了Genedit的两个核心模块制成的结构:(i)分解的SQL生成; (ii)知识基于用户反馈设置编辑。对于一代人来说,Genedit利用复合操作员来改善知识检索,并创建一个计划作为指导生成的经过思考的步骤。genedit首先在初始检索阶段重新研究了相关的示例,在该阶段将原始SQL查询分解为子林,条款或子查询。然后还检索说明和架构元素。使用检索到的上下文信息,GenEdit然后以自然语言的逐步计划,涉及如何产生查询。最后,Genedit使用该计划来生成SQL,最小化模型推理的需求,从而增强了复杂的SQL生成。必要时,Genedit基于句法和语义错误将查询再生。每个发电机都使用上述编辑来更新发电提示。知识集编辑是通过交互式副标题来推荐的,使用户可以根据需要迭代其反馈并重新生成SQL查询。提交了反馈后,它在通过回归测试并获得批准后将其合并,从而改善了子孙后代。

哈里亚纳邦空间应用中心(HARSAC)
03基本资格:来自政府认可的任何大学/专业机构的计算机/地理空间技术学位,具有GIS软件开发和应用程序的经验。至少5年以上的经验。理想的:•使用节点JS和.NET的Web和REST API开发•熟悉ASP.NET框架,并表示JS节点框架,SQL Server和Design/Architectural模式•如果在位置中体验,则优先考虑在位置,跟踪移动APIS和dashboards。•bugs分辨率的良好技能,DB规划和设计架构•了解API文档过程流量和数据的知识,收集的速度优化 - 从 /到服务器的数据•ASP.NET,SQL Server,SQL Server,HTML,HTML,HTML,CSS,CSS,JavaScript,JavaScript和C#,NODE JS,NODE JS,NODED JS,node JS,Postgres,Postgres sql sql sql sql。为各种.NET应用程序准备并维护代码,并解决系统中的任何缺陷。•全堆栈开发人员•团队处理•任何相关认证2农业业务分析师(01)薪酬:卢比。每月64,800/ - 每月合并

针对文本到SQL的基于大型语言模型的大型生成AI的调查:基准,应用程序,用例和挑战
摘要 - Text到SQL系统通过将自然语言查询转换为结构化查询语言(SQL),从而促进与数据库的平稳互动,从而弥合非技术用户与复杂数据库管理系统之间的差距。本调查提供了对AI驱动的文本到SQL系统演变的全面概述,突出了其基础组件,大语言模型(LLM)体系结构的进步以及蜘蛛,WikisQL和COSQL等数据集的关键作用。我们研究了医疗保健,教育和金融等领域中文本到SQL的应用,并强调了它们改善数据可访问性的变革潜力。此外,我们还分析了持续的挑战,包括域的概括,查询优化,对多转交谈的支持以及针对NOSQL数据库量身定制的数据集和动态现实世界情景的有限可用数据集。为了应对这些挑战,我们概述了未来的研究方向,例如扩展文本到SQL功能以支持NOSQL数据库,设计用于动态多转变交互的数据集,并为现实世界中的可伸缩性和鲁棒性优化系统。通过调查当前的进步并确定关键差距,本文旨在指导基于LLM的文本到SQL系统中的下一代研究和应用。索引术语 - LLM,文本到SQL,自然语言处理,人工智能,AI Gen,基准测试,数据集,模式链接,SQL生成。

SNP 的 Azure 数据、AI 和 ML 服务
我们的 4 周评估计划提供专家工程资源,以促进从本地 MS SQL(包括 SSIS、SSAS、SSRS 和 SQL 数据仓库)到 Azure(IaaS、PaaS - Azure SQL、弹性池、托管实例、Azure Synapse 和 Azure 分析服务)的数据迁移。我们期待通过此计划解决客户的迁移和产品功能特定障碍。
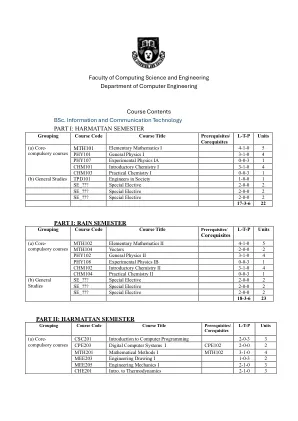
ICT-课程.pdf
数据库系统概述:模型、模式、实例。数据库系统与文件系统。数据抽象级别、数据库语言、系统架构。DBMS 分类。数据建模:实体关系 (ER) 模型、实体和实体类型、关系和关系类型、约束、弱实体类型 ER、图表。示意对象模型。数据库设计过程:需求分析、概念数据库设计、数据库模式设计。使用实体关系和语义对象模型进行数据库设计、数据库应用程序设计。关系数据模型中的术语、完整性约束、关系上的原始操作、关系代数 (RA)、关系代数运算、关系完整性、关系上的附加操作。关系实现的基础。结构化查询语言 (SQL):SQL 中的 DML 功能、SQL 中的 DDL、SQL 中的更新、SQL 中的视图、嵌入式 SQL、按示例查询 (QBE)。并发、恢复和安全问题。阿姆斯特朗的推理规则和最小覆盖、范式。数据库系统的当前趋势:客户端-服务器数据库系统、开放数据库连接 (ODBC) 标准、知识库系统、数据仓库和数据挖掘概念、Web 数据库。