XiaoMi-AI文件搜索系统
World File Search Systemsquares

论矩形中不等边正方形的排列
数学能力是指认知信息通信的一个分支,它研究与数学相关的任何人工和自然认知能力的组合,包括从低级算术运算到高级符号推理的广泛领域。认知信息通信 (CogInfoCom) 的概念在论文 [1] 中引入。它的一些进一步的一般属性在论文 [2] 和 [3] 以及书籍 [4] 中进行了描述。[5-12] 中研究了 CogInfoCom 和数学能力的教育方面,而 [13-20] 中介绍了其他与 CogInfoCom 相关的认知能力应用。
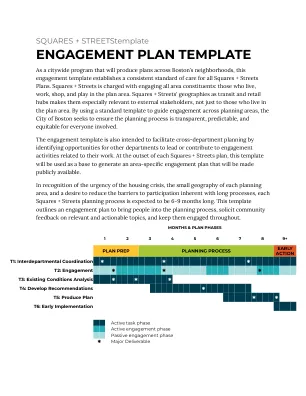
正方形 +街道参与计划模板
对于每个广场 +街道规划过程,将建立计划区域的关键语言。至少将遵循BPDA语言访问计划的标准。所有广泛的公共参与(公共开放式房屋等)),将为关键语言提供翻译服务(该地区5%的选民或1,000个人所说的语言,以较少者为准)。此外,在早期参与期间,项目团队将与关键领域利益相关者讨论通过人口普查数据所证明的语言以外的语言很重要。这些可能包括,例如,企业的顾客可能不住在该地区,而是由于其文化价值而使用该地区的特定便利设施。所有主要文件(计划草案,最终计划)和参与文书(调查,董事会,演示等)将以每个计划区域确定的关键语言提供。对于较小规模的参与度(例如,焦点小组会议或利益相关者的访谈),将根据具体情况评估翻译服务的需求。

最小二乘的通用数学模型...
关键词:三维表面匹配,三维相似变换,带状平差,激光测高 摘要:机载激光扫描仪、摄影测量方法或其他三维测量技术获取的点云中的系统误差需要通过平差程序进行估计和消除。所提出的方法使用数学平差模型估计参考表面和配准表面之间的变换参数。三维表面匹配是二维最小二乘图像匹配的扩展。估计模型是典型的高斯-马尔可夫模型,目标是最小化相邻表面之间的欧几里得距离的平方和。除了通用数学模型外,我们还提出了适用于特殊配准应用的共轭点规则的概念,并将其与三种典型的共轭点规则进行了比较。最后,我们解释了该方法如何用于真实三维点集的配准,并展示了基于机载激光扫描仪数据的配准结果。实验的最终结果表明,该方法具有良好的三维表面匹配性能,最小法线距离规则为机载激光测高数据的条带平差提供了最佳结果。

对固定和随机效果的平均正方形的期望
想象您有责任进行特殊的Striga筛查托儿所。试图从育种计划中确定育种计划中最具抵抗力的高粱杂种,该育种者提交了20种选定的杂种,以评估托儿所。杂种在Intriga感染和非爆发田中评估。这也被称为拆分图设计,因为有不同的实验单元。

使用惩罚最小二乘>的符号回归中的形状约束
摘要。我们研究了形状约束(SC)的添加及其在符号识别步骤(SR)的参数识别步骤中的考虑。sc是一种将有关未知模型函数形状的先验知识引入SR的手段。与以前在SR中探索过SC的工作不同,我们建议在使用基于梯度的NU-MERIMILICE优化的参数识别期间最大程度地减少SC违规行为。我们测试了三种算法变体,以评估其在识别合成生成数据集的三个符号表达式时的性能。本文研究了两种基准方案:一个具有不同噪声水平的基准,另一个具有不同的培训数据。结果表明,当数据稀缺时,将SC纳入表达搜索特别有益。与仅在选择过程中使用SC相比,我们在参数识别期间最小化违规行为的方法在我们的某些测试用例中显示出具有统计学意义的好处,在任何情况下都没有明显更糟。

量子正交拉丁方:局部经典等价性和 2-酉矩阵块秩
随着量子信息论领域的发展,拉丁方在经典编码理论中得到应用,考虑拉丁方的量子类似物也是很自然的。量子拉丁方的概念由 B. Musto 和 J. Vicary 于 2015 年提出[12]。此后,这些对象被证明与绝对最大纠缠 (AME) 态有关系,[14] 后者在量子信息中有各种应用。[9] [16] 我们将详细讨论 Rather 等人最近取得的成果 [15],关于大小为 6 × 6 的量子正交拉丁方的存在,这个对象不存在经典等价物。[18] 一个重要的悬而未决的问题是,是否存在任何阶的量子正交拉丁方,它们在某种意义上不等同于已知的经典拉丁方。[21] 然后,我们将通过考虑计算和代数技术,开始研究大小为 3 × 3 的量子正交拉丁方的这个问题。

典型相关分析和偏最小二乘法识别大脑行为关联:教程和比较研究
摘要典型相关分析 (CCA) 和偏最小二乘 (PLS) 是用于捕捉两种数据模态(例如大脑和行为)之间关联的强大多元方法。然而,当样本量类似于或小于数据中的变量数量时,标准 CCA 和 PLS 模型可能会过度拟合,即发现无法很好地推广到新数据的虚假关联。已经提出了 CCA 和 PLS 的降维和正则化扩展来解决此问题,但大多数使用这些方法的研究都有一些局限性。这项工作对最常见的 CCA/PLS 模型及其正则化变体进行了理论和实践介绍。我们研究了当样本量类似于或小于变量数量时标准 CCA 和 PLS 的局限性。我们讨论了降维和正则化技术如何解决这个问题,并解释了它们的主要优点和缺点。我们重点介绍了 CCA/PLS 分析框架的关键方面,包括优化模型的超参数和测试已识别的关联是否具有统计意义。我们将所描述的 CCA/PLS 模型应用于来自人类连接组计划和阿尔茨海默病神经成像计划的模拟数据和真实数据(n 均为 .500)。我们使用这些数据的低维和高维版本(即样本大小与变量之间的比率分别在 w 1 – 10 和 w 0.1 – 0.01 范围内)来展示数据维数对模型的影响。最后,我们总结了本教程的关键课程。

在约束最小二乘过滤计算上开发高性能量子图像算法
摘要:计算机技术的最新开发可能导致量子图像算法成为热点。量子信息和计算给出了我们的量子图像算法的一些优势,这些算法处理了原始经典图像算法无法解决的有限问题。图像处理为量子图像的应用而哭泣。量子图像上的大多数作品都是理论上的,有时甚至是未抛光的,尽管量子计算机中的现实世界实验已经开始并正在繁殖。但是,正如计算机技术的开发有助于推动技术革命一样,从量子力学,量子信息和极其强大的计算机上提出了一种新的量子图像算法。引入了量子图像表示模型来构建图像模型,然后将其用于图像处理。为了重建或估计点扩散函数,采用了先验知识,并根据相反的处理获得非分类估计。使用最佳的平滑度度量来解决噪声的模糊功能。在约束条件上,确定最小标准函数并估计原始图像函数。对于某些运动模糊和某些噪声污染(例如高斯声音),所提出的算法能够产生更好的恢复结果。另外,应该注意的是,当存在噪声强度非常低的噪声攻击时,基于约束最小二乘过滤的模型仍然可以带来良好的恢复结果,并且具有很强的鲁棒性。随后,讨论实现量子电路和图像过滤的复杂性的仿真分析,并证明当噪声密度较小时,该算法对模糊恢复具有良好的影响。

双重加权的普通最小二乘技术的最新进展用于动态治疗方案
摘要。动态治疗方案(DTR)是一种提供精确药物的方法,该方法使用患者特征来指导治疗方法以实现最佳健康结果。已经提出了许多用于DTR估计的方法,包括动态加权的普通最小二乘(DWOLS),这是一种基于回归的方法,在易于实现的分析框架内具有双重鲁棒性来模拟模型错误指定。最初,DWOL方法是在连续结果和二元治疗决策的假设下开发的。是在临床研究的激励下,随后的理论进步扩大了DWOLS框架,以解决各种结果类型的二元,连续和多酸性处理,包括二进制,连续和生存类型。但是,某些方案仍未开发。本文总结了DWOLS方法的扩展和应用的最后十年,对原始DWOLS方法及其扩展进行了全面而详细的审查,并突出了其多样化的实际应用。我们还探讨了已经解决了与DWOL实施相关的挑战的研究,例如模型验证,可变选择和处理测量错误。使用模拟数据,我们提出了数值插图以及在R环境中的分步实现,以促进对基于DWOL的DTR估计方法的更深入的了解。

葡萄牙公司的人工智能和认知计算:偏最小二乘法的结果 - 结构方程建模
摘要:人工智能 (AI) 和认知计算 (CC) 是不同的,这就是为什么每种技术都有其优点和缺点,这取决于企业想要优化的任务/操作。如今,只需将 CC 与 AI 的广泛主题联系起来,就很容易混淆两者。这样,想要实施 AI 的公司就知道,在大多数情况下,他们想要的是 CC 提供的功能。在这些情况下,知道如何区分它们很重要,这样就可以确定在哪种情况下一种比另一种更合适,从而更多地利用每种技术提供的优势。该项目专注于突出这两种技术的能力,更具体地说是在智能系统实施和公司对它们的兴趣有利的商业环境中。它还确定了这些技术的哪些方面对公司最有吸引力。根据这些信息,评估这些方面是否与决策相关。数据分析是通过采用偏最小二乘结构方程模型 (PLS-SEM) 和描述性统计技术进行的。