XiaoMi-AI文件搜索系统
World File Search System伽马分布

极度降水的统计建模
累积的水)以毫米(mm)为单位。 因此,有非常广泛的文献提出了用于在不同时间尺度(小时,每小时,每日,每月)下降水分布的模型。 例如,用于建模正降水的最流行的分布可能是伽马分布[79],由于其灵活的形状,它通常也提供适合每月降水量的足够适合,但是伽马分布无法在高时间尺度上捕获大降雨特征,即累积的水)以毫米(mm)为单位。因此,有非常广泛的文献提出了用于在不同时间尺度(小时,每小时,每日,每月)下降水分布的模型。例如,用于建模正降水的最流行的分布可能是伽马分布[79],由于其灵活的形状,它通常也提供适合每月降水量的足够适合,但是伽马分布无法在高时间尺度上捕获大降雨特征,即每天和每日。建模降水及其聚集体提出了与其他天气变量(例如温度)相比的独特挑战。精确地捕获随着时间或空间的降水的聚集行为对于许多应用至关重要,包括洪水或干旱风险评估。这需要对适当的依赖模型进行典范或隐式规范,以在时空中结合边缘分布,在时间和空间中,不仅极端,而且中度和低降水值都会有助于极端聚集体。特定于降水的另一个方面是其间歇性,这意味着当考虑完整的观察序列时,可以观察到许多零值。这需要将概率分布视为阳性降水的连续成分的混合物,而在没有沉淀的情况下以零为零成分。虽然整个分布对于降水很重要,但它的极端尤其引起了人们的关注,因为它们通过雨水引起的洪水对人们的影响[38],农业[99]和基础设施[85]。对局部极端的研究是极值分析[50,55]的重要早期应用,也是许多方法论发展的催化剂。的确,如果模型未正确指定,则将参数模型用于整个分布可能会导致尾部分位数估计值的显着偏差。因此,使用源自极值理论的模型来估计降水的尾矿[24,8,33]已成为普遍做法。本章回顾了用于研究极端降水的某些关键方面的统计方法,但没有任何声称是详尽的。第1.2节简要概述了典型的数据特征。第1.3节提出了单变量的概率分布,用于在极值和估计其参数的方法中建模可变性。然后,第1.4节演示了这些分布在代表不同持续时间和频率下的预提取强度或返回值时的应用。第1.5节说明了如何在空间上汇总信息以获得更有效的回报率估计值。上述部分中的方法假设极端降水事件是独立的,并且分布相同。但是,有多种原因认为事实并非如此。例如,季节性和空间模式以及气候变化可能引起非组织性。第1.6节回顾了各种检测和建模非组织降水极端的方法。最后一节是一个讨论,介绍了随机发生器的概念,并阐述了为模拟目的建模极端降雨的重要性。
Xiashengella琥珀酸根源。 11月,sp。 NOV。,一种从家族中的厌氧消化罐中分离出的琥珀酸菌属
菌株AI-910 t。在Mega X软件包中使用Clustalw进行了多个序列比对(Kumar等人2018)。对齐后,从所有序列的左侧和右侧分别修剪了20 bp的碱基,以始终如一地进行系统发育分析。通过1418 bp碱基基于木村的邻居结合树(NJ)树(Kimura 1980; Saitou and Nei 1987)生成1418 bp碱基,一般时间可逆,伽马分布和不可变形地点(GTR + G + G + I)模型(GTR + G + I)模型(GTR + G + I)(MlikeLihehad)(Mlikelihehaens(MlikeLi)(Ml)1981; subtree-pruning- regrafting(SPR)型号,具有10个初始树的最大范围(MP)树(Fitch 1971)的软件包中的spre-tree(SPR)。在每种情况下,基于1000个复制计算引导值。
补充材料 - repisalud
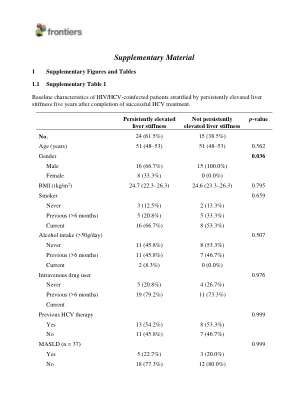
统计:数据是通过具有伽马分布(LOG-LINK)的广义线性模型(GLM)计算的。多变量模型按年龄,性别,HCV治疗(基于IFN的治疗或DAAS),在治疗后一年进行LSM调整,并且在两次之间经过的时间,以前是通过逐步方法(前进)选择的(请参阅结果部分)。Q值代表使用错误发现率(FDR; Benjamini和Hochberg程序)进行多次测试校正的p值。统计上的显着差异以粗体显示。缩写:AMR,算术平均比例; AAMR,调整后的AMR; 95%CI,95%的置信区间; P,意义水平; q,校正的意义水平; BTLA,B和T淋巴细胞衰减剂; CD,分化簇; GITR,糖皮质激素诱导的TNFR相关; HVEM,疱疹病毒入学调解人; IDO,吲哚胺2,3-二氧酶; lag-3,淋巴细胞激活基因-3; PD-1,程序性细胞死亡蛋白1; PD-L1,编程的死亡配体1; PD-L2,编程死亡配体2; TIM-3,T细胞免疫球蛋白和含有3的粘蛋白膜。

DePauw University目录2020-2021
本课程向学生介绍了标准统计程序背后的理论。该课程假定学生对单变量的微积分的工作知识。学生有望得出并采用理论结果以及执行标准统计程序。所涵盖的主题将包括瞬间的功能,伽马分布,卡方分布,T分布和F分布,采样分布以及中心极限定理,点估计,置信区间和假设测试。先决条件:数学136或数学151。数学251。微积分III科学与数学组1课程介绍了几个变量的演算。主题包括向量和固体分析几何形状,多维分化和集成以及应用的选择。先决条件:数学152。数学270。线性代数1组课程矢量空间,线性变换,矩阵,决定因素,特征值以及特征向量和应用。先决条件:数学152或教师的许可。数学321。几何学组1课程中的主题

使用混合分布的 MCET 实现精确并行分割模型 (PPSM)
摘要目的——图像分割是图像处理应用中最重要的任务之一。它是许多面向应用的宝贵工具,例如医疗保健系统、模式识别、交通管制、监视系统等。然而,准确的分割是一项关键任务,因为找到适合不同类型图像处理应用的正确模型是一个长期存在的问题。本文开发了一种新颖的分割模型,旨在成为使用任何类型图像处理应用的统一模型。所提出的精确并行分割模型 (PPSM) 结合了三种基准分布阈值技术来估计最佳阈值,从而实现分割区域的最佳提取:高斯分布、对数正态分布和伽马分布。此外,提出了一种并行增强算法来提高所开发的分割算法的性能并最大限度地降低其计算成本。为了评估所提出的 PPSM 的有效性,使用了不同的图像分割基准数据集,例如 Planet Hunters 2 (PH2)、国际皮肤成像合作组织 (ISIC)、微软剑桥研究院 (MSRC)、伯克利分割基准数据集 (BSDS) 和 COntext 中的通用对象 (COCO)。获得的结果表明,与其他分割模型相比,使用不同类型和领域的基准数据集,所提出的模型能够显著缩短处理时间,实现高精度。设计/方法/方法——所提出的 PPSM 结合了三种基准分布阈值技术来估计最佳阈值,从而实现分割区域的最佳提取:高斯分布、对数正态分布和伽马分布。结果——根据所获得的结果,可以观察到,所提出的基于 PPSM——最小交叉熵阈值 (PPSM - MCET) 的分割模型是一种具有高性能的稳健、准确、高度一致的方法。原创性/价值——使用 MCET 构建了一种利用高斯、伽马和对数正态分布组合的新型混合分割模型。此外,为了以最小的计算成本提供准确、高性能的阈值,所提出的 PPSM 使用并行处理方法来最大限度地减少 MCET 计算中的计算工作量。所提出的模型可用作许多面向应用的宝贵工具,例如医疗保健系统、模式识别、交通管制、监控系统等。关键词最小交叉熵阈值、混合分布、精确分割、并行计算论文类型研究论文

2001 年 12 月 6 日 - Nonstop Systems
版本:2001 年 12 月 8 日 附录 A - 基本概率和统计理论 A1 - 概率集 A1-1 集合运算和代数 A1-2 集合枚举 A1-3 概率的公理和基本规则 A2 - 随机变量 A2-1 概率密度函数和累积分布函数 A2-2 瞬时和累积故障率 A2-3 描述统计 A2-3.1 位置测量:平均值、中位数、众数 A2-3.2 变异性测量:范围、方差、标准差 A3 - 概率分布 A3-1 浴盆曲线 A3-2 二项分布、几何分布和泊松分布 A3-2.1 简单备件计算 A3-3 负指数分布 A3-3.1 占空比的影响A3-4 威布尔分布 A3-5 正态分布 A3-6 对数正态分布 A3-7 伽马分布 A3-8 贝塔分布 A3-9 卡方分布 A4 置信水平和区间 A4-1 常规 A4-2 贝叶斯 A4-3 学生 t 分布的临界值 A4-4 双侧卡方置信限乘数 A4-5 单侧卡方置信下限乘数 A5 问题和练习

草药DNA降解 - 掉落到非 - ...
使用代表10个被子植物家族的56个基因组敏捷的植物标本室DNA术语,发现重叠的读取对发生在大约80%的读取对中。合并了这种重叠对后,所得的片段及其长度分布被认为反映了实际的DNA碎片。类似于古代DNA中的发生,我们发现在标本室材料中碎片末端的嘌呤过分占代表性。碎片长度的分布适合伽马而不是指数分布,而与标本年龄显然相关。观察到的伽马分布将表明高阶降低动力学,这意味着在降解过程中起作用多种过程。可能,与非重复的植物基因组相比,此处使用的基因组掠夺数据,其中重复序列或隔室具有过多的代表性,具有偏见的基因组片段长度分布和半衰期,但没有可用的数据可用于检验该假设。总体而言,我们的结果表明,我们无法确认是否存在植物档案DNA半寿命以及其速率是多少。

考虑电池间差异的锂离子电池性能退化建模
摘要 电池组既表现出固有的电池间差异,也表现出温度和其他应力因素的时空差异,从而影响电池退化路径的演变。为了解释这些变化和退化或电池扩散的差异,我们提出了一种利用 3 参数非齐次伽马过程对锂离子电池退化进行建模的方法。该方法可预测任何电池架构的容量衰减或故障时间,并使用加速因子调整电池拟合退化数据的分布。在电池组级别,使用并联和串联配置的伽马分布变量组合对电池进行建模。将不同热条件下的容量衰减或故障时间的实际值与预测值进行比较,显示相对误差在 1 – 12% 范围内。我们还提出了一种通过分析样本量对估计不同电池组退化的影响来估计建模扩散和退化路径演变所需的最少电池数量的方法。这种采样策略对于降低设计电池组、电池管理系统和电池热管理系统所需的运行模拟的计算成本特别有用。

使用天气数据模拟通过基于样式的生成对抗网络
在2023年,Pothovoltaic(PV)发电的全球安装能力打破了另一个记录。国际能源机构最近发布了2023年的年度报告显示,去年,全球PV发电的新安装能力约为375 GW,增长了30%以上(Szalóczy等人,2024年)。中国是世界上最大的光伏市场和产品供应商(Fu等,2024)。但是,分布式PV发电的固有间歇性和波动引入了相当大的不确定性,因此需要对PV场景进行建模,以减轻这种不确定性并支持PV行业的增长。在影响PV输出的各种因素中,天气条件在引起光伏生成的爆发和不确定性方面起着重要作用。然而,当前的绝大多数PV场景生成文献都会直接产生PV场景,这可以忽略天气对PV的重要影响(Cai等,2023)。为了说明与天气相关的不确定性并对PV发电模型施加更严格的物理约束,PV方案是通过模拟天气场景模拟的,在模型中既有特定的院子和通用性。因此,开发全年天气情况的随机模拟模型对于为PV发电建模提供准确的天气信息至关重要(Rohani等,2014)。当前的天气生成模型主要依赖于涉及概率计算的数学方法。li et la。提出了一个两阶段的方案。Sparks等。最常见的方法是将天气数据的分布直接拟合概率分布,例如β分布后的阳光强度(Rathore等,2023)和Weibull分布后的风速(Hussain等,2023)。在第一个阶段,天气序列是通过单位多变量天气发生器模拟的,在第二阶段,经验副方法用于重现可变量的相互间隔和相间依赖性以及时间结构(Li等,2019)。理查森(Richardson)基于动态的两参数伽马分布模型和两个参数β分布模型提出了WGEN(Richardson,2018)。WGEN目前是广泛使用的天气生成器模型之一,许多其他天气生成器模型是根据WGEN的改进和扩展而开发的,例如美国农业农业部农业研究服务部开发的小木屋。通过将部分时间序列转换为推断的线性函数模型,提出了一种新颖的方法,将天气变量视为具有时间行为的高斯变量(Sparks

恢复
与工业界的合作 与 Mathworks Inc. 合作开发一个用于统一系统分析框架的 MATLAB 工具箱,该框架具有计算效率,可以单独处理不同类型的复杂性。 出版物列表(国内/国际期刊) 1. N. Gupta 和 V. Mittal,“使用多特征组合和具有 K-最近邻的极端随机聚类森林 (KERCF) 的极化 SAR 图像分类”,Journal SGI Reflections,第 2 卷,第 2 期,第 53 页,2011 年 12 月。 2. A. Soor 和 V. Mittal,“一种使用高斯核的 EM 算法进行稳健高效聚类的改进方法”,Int. J. of Database Theory and Application,第 7 卷,第 1 期,第 167 页。 3,第 191-200 页,2014 3. V. Mittal、D. Singh 和 LM Saini,“基于 EM 的不同极化数据融合对土地覆盖分类影响的批判性分析”,空间研究进展,爱思唯尔,第 56 卷,第 6 期,第 1094-1105 页,2015 年。(SCI) 4. R. Sain、V. Mittal 和 V. Gupta,“基于变分贝叶斯推理的利用伽马分布先验的图像修复”,国际信号处理、图像处理和模式识别杂志,第 8 卷,第 6 期,第 1111-1125 页,2015 年。 12,第 207-216 页,2015 年 5. V. Mittal、D. Singh 和 LM Saini,“极化合成孔径雷达数据分类技术的批判性分析”,智能信息学进展国际杂志,第 2 卷,第 10-20 页,2016 年(SCOPUS) 6. P. Kumar 和 V. Mittal,“使用贝塞尔曲线和优化进行数字视频缝合和稳定”,电子和计算机工程研究国际杂志(IJRECE),第 6 卷,第 3 期,第 209-214 页,2018 年 7. P. Kumar 和 V. Mittal,“使用基于块的分割进行边缘检测”,电子和计算机工程研究国际杂志(IJRECE),第 2 卷,第 3 期,第 209-214 页,2018 年6,第 3 期,2018 年,第 222-226 页 8. V. Mittal 和 M. Mittal,“基于 Haar 小波的数值方法用于计算系统对任意激励的响应”,《高级动态与控制系统研究杂志》,2018 年第 9 期,第 2433-2439 页(SCOPUS) 9. M. Mittal 和 V. Mittal,“使用 Haar 变换算法分析难以分析的复杂 MIMO 动态系统”,《高级动态与控制系统研究杂志》,2018 年第 9 期,第 2452-2460 页(SCOPUS) 10. A. Kumar 和 V. Mittal,“使用神经网络控制器进行连续印地语语音识别的混合特征提取技术”,《高级