XiaoMi-AI文件搜索系统
World File Search System位数

Ankara中0-2岁儿童的生长曲线和百分位数的头圆周:与Gamlss和分位数回归方法进行比较
测量HC是一种快速,无创的方法,用于确定婴儿的头部太大(兆脑)还是太小(小头畸形)。6与标准生长曲线相比,常规的HC测量对于跟踪婴儿的健康至关重要。该程序被认为是“最简单,最便宜,最快的[工具],用于评估中央系统的发展和确定有神经发育障碍风险的新生儿。” 7头圆周也经常在处于危险的婴儿(例如早产或低胎胎婴儿或患有已知遗传疾病的患者)中测量;大多数临床医生在常规良好的访问中包括串行HC测量,或者是由于生长关节以外的原因(即机会性增长测量值)以外的其他婴儿和儿童的定期护理。8

pqrbayes:贝叶斯惩罚分位数回归
说明使用现代加密技术将R对象加密到原始向量或文件。基于密码的密钥推导与“ argon2”()。对象被序列化,然后使用“ XCHACHA20- poly1305”进行加密(),遵循RFC 8439的rfc 8439,用于认证的加密( and>)加密函数由随附的“单核”'C'库提供()。

保留分位数趋势以模拟未来气候影响
摘要:全球气候模型 (GCM) 是理解气候系统及其在情景驱动排放路径下演变趋势预测的重要工具。其输出结果被广泛应用于气候影响研究,用于模拟气候变化的当前和未来影响。然而,与气候影响研究所需的高分辨率气候数据相比,气候模型输出结果仍然较为粗糙,并且相对于观测数据也存在偏差。在现有的全球尺度上经过偏差调整和降尺度处理的气候数据集中,分布尾部的处理是一个关键挑战;许多此类数据集使用了分位数映射技术,而这些技术已知会抑制或放大尾部的趋势。在本研究中,我们应用分位数增量映射 (QDM) 方法 (Cannon 等,2015) 进行偏差调整。在偏差调整之后,我们应用一种名为“分位数保留局部模拟降尺度”(QPLAD)的新型空间降尺度方法,该方法旨在保留分布尾部的趋势。这两种方法都集成到一个透明且可重复的软件流程中,我们将其应用于耦合模式比较计划第六阶段 (CMIP6) 实验 (O'Neill et al., 2016) 的历史实验和四种未来排放情景(从积极缓解到无缓解)的全球每日 GCM 地表变量输出(最高和最低温度以及总降水量),即 SSP1-2.6、SSP2-4.5、SSP3-7.0 和 SSP5-8.5 (Ri-

埃及的能源支出:基于分位数回归方法的实证证据
本文表达的任何观点均为作者观点,而非 IZA 观点。本系列中发表的研究可能包括政策观点,但 IZA 不代表任何机构政策立场。IZA 研究网络致力于遵守 IZA 研究诚信指导原则。IZA 劳动经济研究所是一个独立的经济研究机构,开展劳动经济学研究,并就劳动力市场问题提供基于证据的政策建议。在德国邮政基金会的支持下,IZA 运营着世界上最大的经济学家网络,其研究旨在为我们这个时代的全球劳动力市场挑战提供答案。我们的主要目标是在学术研究、政策制定者和社会之间架起桥梁。IZA 讨论文件通常代表初步工作,并被分发以鼓励讨论。引用此类文件时应说明其临时性质。修订版可直接从作者处获得。
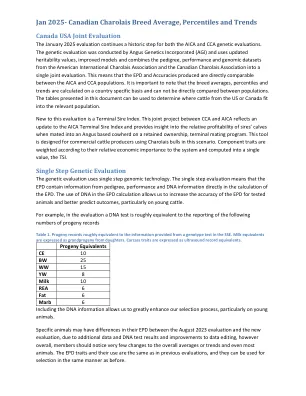
2025年1月 - 加拿大夏洛来品种的平均水平,百分位数和趋势
加拿大美国联合评估2025年1月的评估是AICA和CCA遗传评估的历史步骤。遗传评估是由Angus Genetics Incorporated(AGI)进行的,并使用了更新的遗传性值,改进的模型,并将来自美国国际夏洛伊国际夏罗莱协会和加拿大夏洛来群岛协会的谱系,性能和基因组数据集结合在一起。这意味着所产生的EPD和准确性在AICA和CCA种群之间是可比的。重要的是要注意,品种平均值,百分位数和趋势是根据国家特定的,无法直接比较人口之间的。本文档中提出的表可用于确定美国或加拿大的牛适合相关人群的位置。

表观遗传时钟的不确定性定量通过共形分位数回归
表观遗传年龄预测因子是Horvath的表观遗传钟1,这是一个统计预测模型,在353 CpG位点使用DNAM至1个预测年龄。2种训练表观遗传时钟的标准方法涉及几个关键步骤:(i)从具有不同背景的个体3个个体的生物样本中收集生物样本; (ii)提取DNA并进行DNA甲基化分析; (iii)进行数据预处理4个程序,例如缺少数据插补,离群值删除和数据归一化; (iv)采用特征筛选方法5来识别相关的CPG站点,这些位点可预测年龄或与衰老过程相关; (v)将高维6回归模型与弹性净罚款拟合; (vi)在独立的测试数据集上评估模型性能,以验证其7个准确性和鲁棒性。8尽管有完善的构造表观遗传时钟的管道,但其中大多数仅提供点平均预测1,2,5。9
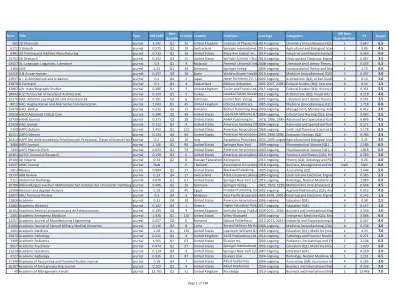
排名 标题 类型 SJR 2018 最佳四分位数 H 指数 国家 ...
1372 Acta Crystallographica Section B: Structural Science, Crystal Engineering andjournal 1.966 Q1 24 美国 John Wiley and Sons 2013 年至今 原子和分子物理学、1 2.326 6.5

分位数回归征:一种深度学习算法,用于缩小极端降水
全球气候模型(GCMS)模拟了全球范围内的低分辨率投影。GCM的本地分辨率通常对于社会级别的决策而言太低。为了增强空间分辨率,通常将降尺度应用于GCM输出。尤其是统计缩减技术,是一种具有成本效益的方法。与基于物理的动力学缩放相比,它们所需的计算时间要少得多。近年来,与传统统计方法相比,统计降尺度的深度学习越来越重要,证明错误率明显较低。但是,基于回归的深度学习技术的缺点是它们过度适合平均样本强度的趋势。极值通常被低估。问题上,极端事件具有最大的社会影响。我们提出了分位数回归征(QRE),这是一种受增强方法启发的创新深度学习al-gorithm。它的主要目标是通过训练分区数据集上的独立模型来避免拟合样品平均值和特殊值之间的权衡。我们的QRE对冗余模型具有鲁棒性,并且不容易受到爆炸性集成权重的影响,从而确保了可靠的训练过程。QRE达到了较低的均方误差(MSE)。尤其是,对于新西兰的高强度沉淀事件,我们的算法误差较低,突出了能够准确代表极端事件的能力。


战争抚恤金计划背景质量报告 3 月 23 日
使用四分位距而不是平均数和标准差,因为这些统计数据受异常值的影响较小,更能反映提出索赔的个人的平均典型经历。异常值是数据集内与数据集其余部分似乎不一致的观测值。• 中位数是数据集从小到大排列时中心的值。• 四分位数是将排序(从最小值到最大值)的数据集分成四个相等部分的三个值(第一/下四分位数、第二四分位数(中位数)、第三/上四分位数)中的任何一个。下四分位数(LQ)是数据集中 25% 的值低于此点的值。上四分位数(UQ)是数据集中 75% 的值低于此点的值。• 四分位距(IQR)是中间 50% 的数据点所在的范围(即下四分位数和上四分位数之间的距离)。四分位数间距越长,数据分布越广。47. 请注意,补充表中还显示了平均值,因为这是