XiaoMi-AI文件搜索系统
World File Search System分数


分数统计
粒子组件的量子力学描述仅限于两个(或一个)空间尺寸的粒子的组件,提供了许多与玻色子和费米子不同的可能性。我们称之为这样的粒子。最简单的Anyons通过角相参数θ进行了参数化。θ= 0,π分别对应于玻色子和费米子。在Intermedi-Ate值中,我们说我们具有分数统计数据。在二维中,θ将波函数获取的相描述为两个逆时针旋转的彼此缠绕。它为相对角动量产生允许值的变化。与Abelian U(1)量规组相关的局部电荷和磁通量的复合材料实现了这种行为。更复杂的电荷升华结构可能涉及在允许的电荷和通量范围内的非亚伯和产品组,从而产生非亚伯和相互统计。nonabelian Anyons的互换在内部状态的新兴空间内实现了波函数的单一转换。各种各样的人都用包括Chern -Simons项在内的量子场理论来描述。环上的一维Anyons的交叉点是单向的,因此互换时获得的分数相θ产生了Anyons之间相对动量的分数移动。最近,在ν= 1/3中的准粒子预测的Anyon行为< / div>
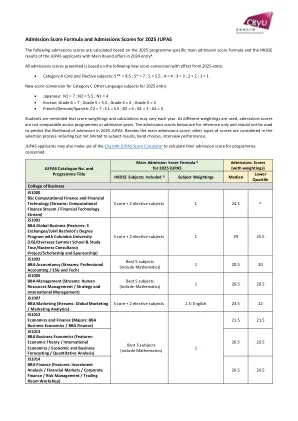
2025 年 JUPAS 入学分数公式及入学分数
# 不包括经特殊途径取录的学生(例如,比赛/活动的其他经验和成就、校长提名、体育才华、残疾人士申请者及民政及青年局多元卓越奖学金)∆ 不包括香港中学文凭考试公民及社会发展科及香港中学文凭考试通识教育科 ^ 对于 2024 年入学联招录取人数较少的课程,不会显示中位数及/或下四分位数分数。 * 课程名称须经大学批准。
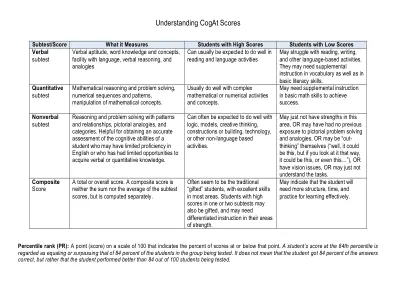
了解Cogat分数
口头推理中相对弱点的相对弱点V-指标包括以下内容:•即使在他们脱颖而出的领域,这些活动也会不必要地挫败学生的表现。难度的常见来源是过度长的方向,并且需要翻译口头提示或需要口头反应的测试。•口头评分较低的学生通常会发现自己在课堂上不知所措,尤其是在第一次遵循指示或试图在不同的言语活动之间转移注意力时。q-定量推理中相对弱点的指标包括:•有些学生更喜欢更多具体的思维方式,并且经常掩盖他们在使用语言概念时未能抽象思考的方法。•对于其他学生来说,困难在于未能开发出作为数字行的内部心理模型。•对于其他学生来说,弱点无非是缺乏思考和谈论定量概念的经验。n-指标包括:•要么学生难以推理图形空间刺激,要么•学生难以解决陌生的问题。

碳过渡分数
1数据披露的局限性:虽然J.P. Morgan Asset Management将其视为认为是可靠的数据输入,但J.P. Morgan Asset Management不能保证其专有系统的准确性,可用性或完整性(包括但不受限制的JPMAM碳过渡分数)或第三方数据。在J.P. Morgan Asset管理的某些投资流程中,数据输入可能包括公司和第三方提供商自我报告的信息,这些信息可能基于标准,这些标准与J.P. Morgan资产管理的标准有很大不同,这些标准通常包括有目的的前瞻性陈述,并且不一定是基于事实的,并且是基于事实或客观的。此外,第三方提供商使用的标准可能会有很大差异,并且在同一提供商的同一提供商中,数据可能会有所不同。对数据的评估也可能需要主观判断。此类数据差距或应用的主观判断可能会导致对数据,发行人的碳过渡风险和机会的不正确,不完整或不一致的评估。

人工智能 - 稳定分数匹配
摘要:我们研究了经典稳定匹配问题的泛化,该问题允许基数偏好(而不是序数)和分数匹配(而不是积分)。在这种基数设置中,稳定分数匹配可以比稳定积分匹配具有更大的社会福利。我们的目标是了解寻找最佳(即福利最大化)稳定分数匹配的计算复杂性。我们考虑精确和近似稳定性概念,并提供具有弱福利保证的简单近似算法。我们的主要结果是,有点令人惊讶的是,实现更好的近似在计算上很困难。据我们所知,这些是基数模型中稳定分数匹配的第一个计算复杂性结果。在获得这些结果的过程中,我们提供了许多可能具有独立意义的结构观察。

特刊 - 分形和分数
分数演算在机器学习和生物医学工程中的应用是一个新颖且快速增长的研究领域。分数演算(FC)与机器学习(ML)和生物医学工程(BME)的交集是一个新兴领域,有望彻底改变我们在数据分析,信号处理,生物医学系统建模和控制方面解决问题的方式。该特刊旨在将FC应用于ML和BME领域的领域中的尖端研究和发展,包括但不限于以下内容:FC的理论进步及其对ML和BME的含义;开发对机器学习和重新学习的范围的分数算法的开发;包括Neural Intervers in Neural Intervers in Neural Interials fr Fr Fring; FRIF;和图像分析;使用分数阶微分方程对生物系统进行建模;生物医学设备和机器人技术中的分数控制系统;分数演算在生理建模和生物信息信息学中的应用;在FC与ML和BME集成中的挑战和未来方向。

学习记忆的蒸发分数
文本S1。涡流数据集的数据预处理程序数据的原始采样频率为半小时。数据过滤过程可以概括如下:首先,要在夜间测量中降低噪声,用明智的热通量> 5 w/m 2和短波输入辐射> 50 W/m 2对原始数据进行过滤,以选择白天的数据。然后,将原始数据平均为每日比例值(将降水计算为每日总和)。其次,我们只保留一小部分优质数据> 0.8。使用已建立的方法对输入特征的时间序列中的差距进行了插值(Reichstein等,2005; Vuichard和Papale,2015)。我们还按站点进行视觉检查,以确保可以接受信噪比。请注意,校正了来自涡流协方差的所有半小时LE数据,以使用Bowen比率方法实现能量平衡(Twine等,2000)。由于数据限制,仅使用最浅的土壤水分测量值与干燥期间的蒸发分数预测动态进行比较。文本S2。模型解释 - 综合梯度(IG)开发了集成梯度来解释受过训练的模型,从而可以获得对每日EF预测的每个样本的输入特征的时间特征的重要性(Jiang等,2022; Sundararajan等人,2017年)。IG方法可以拆除基于LSTM的机器学习模型,并追溯输入的特定贡献,并在预测前的每个时间为每个功能分配重要性得分。较大的正Ig评分可能表明该特征大大提高了蒸发分数预测(例如,在最近端的时间内的降水可能对当前蒸发分数的预测比早期的降水更大。)较大的负IG分数表明该特征降低了EF预测。IG得分接近零表示对EF预测的影响很小。以这种方式,我们的模型不仅可以显示一般特征的重要性,而且还可以在预测之前的每个时间步骤显示不同的特征重要性。更具体地说,这意味着对于不同种类的PFT的EF预测,将考虑输入特征的时间长度,其中暗示在特定的极端事件或环境条件下,例如具有不同严重性水平的干旱,植物的植物响应具有不同的生根深度。输入特征X的IG评分(例如,在第i th时间步骤中降水的特定贡献)被表达为:

分数:评估决策的鲁棒性 -
摘要 - 自主驾驶系统(ADS)测试对于ADS开发至关重要,目前的主要重点是安全性。然而,对非安全性能的评估,尤其是广告做出最佳决策并为自动驾驶汽车(AV)提供最佳途径的能力,对于确保智力和降低AV风险的智力也至关重要。当前,几乎没有工作来评估ADSS路径规划决策(PPD)的鲁棒性,即,在环境中无关紧要的变化后,广告是否可以维持最佳的PPD。关键挑战包括缺乏评估PPD最优性的清晰牙齿,以及寻找导致非最佳PPD的场景的困难。为了填补这一空白,在本文中,我们专注于评估ADSS PPD的鲁棒性,并提出了第一种方法,分区者,用于生成非最佳决策方案(NODSS),其中ADS不计划AVS的最佳路径。测试器包括三个主要组成部分:非侵入性突变,一致性检查和反馈。为了克服甲骨文挑战,设计了非侵入性突变以实施保守的修改,从而确保了在突变场景中保存原始的最佳路径。随后,通过比较原始场景和突变的场景中的驱动路径来应用一致性检查以确定非最佳PPD的存在。为了应对大型环境空间的挑战,我们设计了整合AV运动的空间和时间维度的反馈指标。这些指标对于有效地转向发射的产生至关重要。因此,分子可以通过生成新方案,然后在新方案中识别点头来生成点头。我们评估了开源和生产级广告Baidu Apollo上的分员。实验结果验证了分子在检测ADS的非最佳PPD中的有效性。它总共生成63.9个点头,而表现最佳的基线仅检测35.4个点头。