XiaoMi-AI文件搜索系统
World File Search System列域


EZ-editor™ 人类转录因子DNA 结合域CRISPR 敲除文库 ...
文库。除此之外,源井还提供CRISPR-KO、CRISPRa、CRISPRi 三大定制文库从高通量sgRNA 文

癌症场研讨会-Chiba县
秘书处:生命科学行业促进办公室,工业促进部,千叶县工商业部,电话:043-223-2725电子邮件:sangyo-b@mz.pref.chiba.chiba.lg.jp.jp.jp

多尺度特征交互的伪标签无监督域自适应行人重识别
刘仲民,杨富君,胡文瑾 .多尺度特征交互的伪标签无监督域自适应行人重识别 [J].光电工程, 2025 , 52 (1): 240238 Liu Z M, Yang F J, Hu W J. Multi-scale feature interaction pseudo-label unsupervised domain adaptation for person re- identification[J].Opto-Electron Eng , 2025, 52 (1): 240238

薄列列聚合物网络的山脊能量
抽象将平滑等距沉浸式列表聚合物网络的薄板的弹性自由能最小化是主流理论所声称的策略。在本文中,我们拓宽了可允许的自发变形类别:我们考虑脊层浸入式浸入,这可能会导致浸入浸入的表面尖锐的山脊。我们提出了一个模型,以计算沿此类山脊分布的额外能量。这种能量来自弯曲;在什么情况下,它显示出与薄板的厚度四相缩放,落在拉伸和弯曲能量之间。,我们通过研究磁盘的自发变形,将径向刺猬的自发变形置于测试中。我们预测了外部试剂(例如热量和照明)在材料中诱导的材料诱导的顺序程度而发展的褶皱数量。
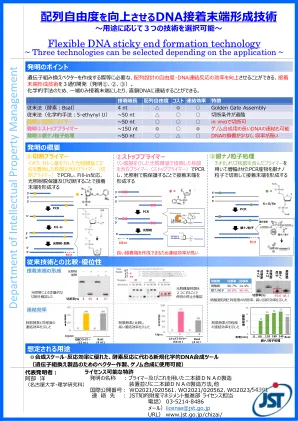
DNA粘合剂终端形成技术,可提高序列自由度的程度
已经开发了三种类型的粘附终端形成技术(发明1,2,3)可以改善序列设计的自由度和DNA连接反应的效率,这对于创建遗传修饰的矢量等是必需的。由于使用了化学技术,只有一端才能成为粘附端或可以与线性DNA链接到线性DNA。

人工智能在外科手术中的应用及前景
1) MD Zeiler 和 R. Fergus:可视化和理解卷积网络,欧洲计算机视觉会议 (2014)。 2) https://jp.mathworks.com/help/deeplearning/ug/understand- network-predictions-using-occlusion.html 3) Noriyoshi Miyoshi、Ryo Kawasaki、Hidetoshi Eguchi 和 Yuichiro Toki:大阪大学 AI 医院和胃肠外科的现状和前景,Surgery, 83, 11 (2021) 1153。

在-HALO列下方
通常,样品可能包含来自样品矩阵的化合物,可以通过固定相保留。盐,脂质,增塑剂和聚合物是在分析过程中可能与固定相接触的一些可能物质。这些物质可能会对色谱柱,检测器产生有害影响,并在分析过程中引起瞬时峰。如果这些物质不被流动阶段洗脱,它们可以积聚在列上。随着时间的流逝,分析物可以与这些杂质相互作用并影响分离机制,从而导致保留时间移动和峰值尾巴。此外,这些积累的杂质会造成阻塞,从而导致柱面压力升高,损坏泵,并可能导致柱床中的空隙形成。强烈建议使用防护柱来避免此类问题。防护列是简短的列,包装包装与喷油器和分析列之间安装的分析列相似。在给定期间后,它们被丢弃,并安装了新鲜的防护柱,以最大化分析柱的寿命。

