XiaoMi-AI文件搜索系统
World File Search System图像


提示文本到图像扩散模型的迅速反转
提供给文本对图像差异模型的提示的质量决定了生成的内容对用户意图的忠诚程度,通常需要“及时工程”。要通过及时的工程来利用目标图像的视觉概念,当前方法在很大程度上通过优化然后将它们映射到伪tokens来依赖嵌入反演。然而,使用这种高维矢量表示是具有挑战性的,因为它们缺乏语义和可解释性,并且只允许使用它们时模拟矢量操作。相反,这项工作着重于反转扩散模型,以直接获得可靠的语言提示。这样做的挑战在于,由此产生的优化问题从根本上是离散的,提示的空间呈较大。这使得使用标准优化技术,例如随机梯度下降,困难。为此,我们利用延迟的投影方案来访问代表模型中词汇空间的提示。此外,我们利用了扩散过程的时间段与图像中不同级别的细节相差的发现。后来的,嘈杂的,前传扩散过程的时间段对应于语义信息,因此,此范围内的迅速反转提供了代表图像语义的令牌。我们表明,我们的方法可以确定目标图像的语义可解释和有意义的提示,该提示可用于合成具有相似内容的多样化图像。我们说明了优化提示在进化图像生成和概念删除中的应用。

卫星图像处理中的人工智能&...
卫星图像处理是管理我们星球资源的强大工具之一。最近,它在应对全球挑战(例如资源管理,可持续性,气候变化,灾难管理和响应,作物监测等)等全球挑战方面非常重要。图像处理中AI技术的演变已成为处理卫星图像的动力。通过提供高级工具进行分析。FDP旨在深入了解AI在卫星图像处理及其应用中的范围和影响。


热和听觉不愉快刺激对健康个体中运动图像的影响
。CC-BY 4.0国际许可证可永久提供。是作者/资助者,他已授予Medrxiv的许可证,以显示预印本(未通过同行评审证明)预印版本的版权所有者此版本发布于2025年3月10日。 https://doi.org/10.1101/2025.03.06.25323546 doi:medrxiv preprint

提高MRI图像的清晰度和降噪...
Mandeep Kaur 1,Rahul Thour博士2 1研究学者部计算机科学与应用,Desh Bhagat University,Mandi Gobindgarh 2助理教授计算机科学和应用,德什·巴加特大学,曼迪·戈宾德加(Mandi Gobindgarh)摘要:脑部疾病是严重的疾病,不得不忽略,因为大脑失败会对整体健康构成重大威胁。早期检测和干预对于管理各种与大脑相关的疾病至关重要。检测脑肿瘤和其他神经系统问题的主要诊断方法之一是MRI成像。MRI是一种首选技术,由于其效率,实时成像功能和缺乏辐射。然而,诸如Speckle噪声,高斯噪声和其他工件之类的挑战继续损害MRI图像的质量。因此,提高图像质量对于准确的脑部疾病诊断至关重要。为了克服这些挑战,采用了各种成像技术来进行预处理,降低降噪和图像增强。从嘈杂的MRI数据中获得高质量图像的关键方法是图像恢复和增强。鉴于MRI的高频特性,脑部扫描中通常存在噪声。预处理通过应用过滤器消除噪声来改善图像质量中起着至关重要的作用。诸如Mean,Mentian,Wiener和其他过滤器之类的技术通常用于解决诸如Speckle,Salt和Pepper和Gaussian噪声之类的问题。关键字:大脑MRI成像,斑点噪声,高斯噪声,预处理,图像增强。这项研究提供了各种MRI图像预处理和增强技术的全面概述,概述了它们的目标和有效性。

研究人员教神经网络将云和雪添加到图像
这项研究为从气候监测到广泛的地区到环境项目和农业任务提供了更准确的细分机会。例如,该解决方案促进了对森林区域的有效分析,其特征和变化,即使在云云比例很高的北部地区,同时考虑了气候条件对图像的影响。
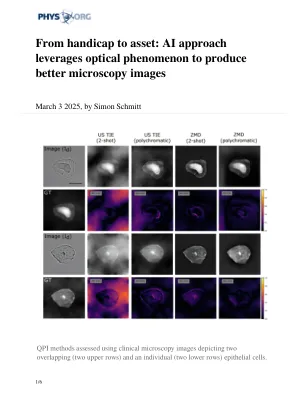
从障碍到资产:AI方法利用光学现象产生更好的显微镜图像
通过采用生成AI模型,只需一次一次接触即可获得使QPI对生物医学应用吸引的必要图像质量。该团队于2月下旬举行的AI促进协会(AAAI 2025)于今年在费城组织的AI协会的第39届AI年会。相应的会议论文可在Arxiv预印式服务器上找到。

AI可以指导获取诊断质量肺超声图像
Cristiana Baloescu,M.D.,M.P.H.,来自康涅狄格州纽黑文的耶鲁大学医学院,同事们研究了AI在多中心诊断研究中通过THCPS指导THCP的诊断质量LUS图像的能力。年龄在21岁或以上的参与者从四个临床站点招募了两次超声检查:一名使用肺指导AI的THCP操作员和一个没有AI的训练有素的LUS专家。参与之前,THCP进行了标准化的AI培训以获取LUS。

无图像失真的透明可拉伸基材显示了下一代显示的潜力
使用迷你领导的设备和SIBS基板上的印刷图像的原始和剪切的SIBS膜之间垂直失真和变形差异的可视化。a)未拉伸设备的照片,d)印刷图像; b)设备和e)原始SIBS基板上的印刷图像伸展50%。c)设备和f)在剪切的SIBS基板上打印的图像伸展50%。(a – c)中的白色比例尺和(d – f)中的黑色比例尺每个代表1 cm。信用:高级材料(2024)。doi: