XiaoMi-AI文件搜索系统
World File Search System树井

使用人工智能进行井字游戏
III. 参考文献 [1] Elaine Rich、Kevin Knight、Shivashankar B Nair(第三版)《人工智能》,McGrew Hill。 [2] Ashutosh Kumar Sahu、Parthasarathi Palita、Anupam Mohanty,“计算机之间的井字游戏:一种计算智能方法”,siksha O' Anusandhan 大学,2018 年 5 月 20 日。 [3] K. Yeung、B. Jacques、R. Du,“实时在网上与机器人玩井字游戏”,国际工程教育会议,2022 年 8 月 18 日 [4] Sneha Garg、Dalpat Songara、Saurabh Maheshwari,“使用理论计算机科学的井字游戏模型的制胜策略”,2017 年国际计算机、通信和电子会议(comptelix),Manipal 大学斋浦尔,2017 年 2 月 1 日 [5] Douglas E. Comer、David L. Stevens,(第二版,第 III 卷),“使用 TCP/IP 工作的互联网”,Prentice-Hall印度私人有限公司。

孤儿井计划向国会提交的年度报告
BIL 两党基础设施法 BLM 土地管理局 BSEE 安全与环境执法局 CEJST 气候与经济正义筛查工具 CO2 二氧化碳部门 美国内政部 EJScreen EPA 环境正义筛查和绘图工具 EMIS 环境管理信息系统 EPA 美国环境保护署 FTE 全职员工 FWS 美国鱼类和野生动物服务局 FY 财政年度 g/hr 每小时克 GDP 国内生产总值 IDIQ 不定期交付 不定期数量 IIJA 基础设施投资和就业法案 IOGCC 州际石油和天然气契约委员会 LDNR 路易斯安那州自然资源部 LSU 路易斯安那州立大学 NAS 美国国家科学院 NPS 国家公园管理局 OWPO 孤井计划办公室 RBDMS 基于风险的数据管理解决方案 RFI 信息请求 SO 部长令模板 孤井数据报告模板 USFS 农业部 美国森林服务局 USGS 美国地质调查局

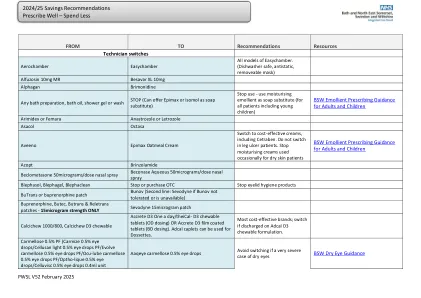
2024/25储蓄建议处方井
BSW配方。这种力量的唯一迹象是成年人最初的7天剂量滴定,用于恐慌症,创伤后应激障碍和社交焦虑症以及对强迫性障碍的儿童的最初剂量滴定。Symbicort,Duoresp,Budesonide/formoterol 100/6、200/6或400/12

低碳氢井到坦克途径研究
这项研究整理了来自一系列已发表文献来源的数据,直接来自氢供应链的公司。ZEMO成员的专业转向组有助于同行审查假设,建模输入和输出。创建了一种温室气体排放和能源使用模型,该模型包括三十多个组合,用于各种生产,分布和分配途径。低,中央和高值均已确定。中央值用于得出各种低碳氢供应链的最终WTT温室气体发射和能量消耗量。特定WTT值的时间表与预期的技术商业化和部署一致,导致2020年,2030年和“从2035年开始”。

钻井,井建筑和干预服务插头&...
减少排放技术Parker Wellbore具有技术服务工程,运营能力通过项目管理,以部署减少排放的技术。•升级的钻机 - 帕克井眼提供工程解决方案,以避免热诱捕气体,包括双燃料发动机升级或天然气兼容的燃料系统。•我们可以通过使用创新的燃油解决方案(例如使用天然气兼容的动力系统而不是柴油)来自定义产品来减少排放。•高线功率 - 对于寻求新方法来减少温室气体排放的客户,帕克·韦尔伯尔(Parker Wellbore)提供具有高线电力的钻机解决方案。•我们在阿拉斯加钻机上的自定义开关设备技术使我们能够运行高线电力。通过利用清洁的高线功率,我们大大减少了对柴油机驱动器的依赖,从而限制了化石燃料的使用,同时最大程度地减少了温室气体。

签名未验证
增产措施将在下部(5.25 英寸 x 7 英寸)完井后进行,将由 14 - 18 个增产套管组成。压裂套管/阶段之间的下部完井环空隔离将由水泥组成。下部完井将使用工作管柱进行支撑剂压裂,以打开套管、泵送压裂、倒出下部完井内的任何支撑剂,然后关闭套管,然后再上移到下一阶段。在最后一个增产阶段之后,工作管柱将从井中拉出。将安装 5.25 英寸 x 4.25 英寸完井管柱,并配备可剪切扶正器,以定位(但不密封)下部完井衬管悬挂封隔器抛光井筒插座 (PBR)。此外,深置塞将与生产封隔器一起运行,以提供“A”环空隔离。完井设计包括永久井下压力表 (PDHG) 和井下安全阀 (DHSV)。将安装防喷器 (BOP) 和采油树以及井口阀门。

基于树的模型需要数据预处理吗?
数据预处理是机器学习管道的重要组成部分(García等,2015; Alasadi和Bhaya,2017;çetinandYıldız,2022),因为它极大地影响了数据质量(Famili等,1997),并发现可以优化机器学习模型的关系,并将其发现。尽管是一个耗时的过程(Anaconda,2022),但这是基本的,尤其是对于大型数据集,降低维度可以在随后的过程中节省时间(García等,2016)。数据预处理不仅包括质量检查,还包括关键元素,例如转换,填充丢失的数据,离群值检测以及模型的变量选择。尽管普遍认为,基于树的模型不需要预处理,因为它们可以在没有任何更改的情况下处理它,但实验表明我们可以通过适当的预处理获得更好的结果(Caruana等,2008; Grinsztajn等,20222)。这种理解可能对自动化机器学习(AUTOML)管道有益,使我们能够优化和实施一个自动化的机器学习过程,该过程可以适当地预处理数据集以获得所选模型以产生更好的结果。本文提出了一个广泛的实验,涉及38个数据预处理策略,用于二进制和多类分类以及回归任务。我们使用五个基于树的模型:决策树,随机森林,XGBOOST,LIGHTGBM和CATBOOST。我们扩展了Forester 1软件,包括更多干扰自动模型学习的预处理。有关该工具的更多信息可在附录A中获得。

UCB,蒙特卡洛树搜索,alphazero
可以证明,UCB的遗憾在渐近上是最佳的,请参见Lai和Robbins(1985),渐近的适应性分配规则;或2018年Bandit算法书籍的第8章在线可在线提供,网址为https://banditalgs.com/。

树 - 养育育种 - 居民 - temperate-Forests- ...
地方发展中心(CEDEL)和文化和土著研究中心(CIRIR),Villarrica Campus,Pontifical catulica cat的Villarrica校园农业与森林科学学院生态系统与环境系野生动植物实验室,宗教大学cat cat g olima de Chile,Avda。vicu〜na Mackenna 4860,Macul,Macul,大都会地区,智利C角国际全球变化研究与生物文化保护和生物文化保护中心(CHIC),De Magallanes大学和应用生态与可持续性中心(CAPES)智利D国家奥杜邦学会,奥杜邦美洲,伯纳多或希金斯501,维拉里卡,阿劳卡尼亚地区,智利