XiaoMi-AI文件搜索系统
World File Search System段晓峰

量子密度峰聚类算法
聚类分析起源于分类学,是人类掌握的一门古老技能。过去,人们依据经验和专业知识对商品进行分类。随着现代社会的发展,人们对分类的要求越来越高[1,2],仅依据经验和专业知识的分类已逐渐被淘汰,现在计算机技术被用于聚类分析,使用算法解决庞大而复杂的聚类任务[3,4]。因此,聚类算法已被提出并应用于各种场合[5,6]。此外,我们生活的海量数据世界也使得聚类过程不可或缺。许多研究领域都面临着海量数据的问题[7,8]。如果没有聚类或数据降维等预处理,很难进行后续分析[9–11]。例如在机器学习领域,几乎所有重要算法的原始入口都是大量的大规模数据,如果不进行聚类或降维,这些数据很难得到利用[12–14]。在量子通信领域,量子通信设备仅供应给少数几家大公司,量子通信中的很多方可能都是经典的,聚类算法可以帮助通信方更便捷地处理传输的信息[15–17]。在数据降维方面,我们熟悉的主成分分析算法(PCA)[18]、多维缩放(MDS)、线性判别(LDA)、局部线性嵌入(LLE)等[19–22]。但降维算法不可避免地会降低数据的属性值,如果操作不当,数据就会失去准确性,结果就会出现偏差,而使用聚类算法可以避免此类问题。目前,聚类算法可以按以下方式划分。基于分区的聚类算法包括 K 均值 [23]、K 中值 [24] 和核 K 均值算法 [25]。基于层次的聚类算法包括 BIRCH、CURE 和 CHAMELEON 算法 [26]。基于密度的聚类算法包括 DBSCAN、均值漂移 (MS) [27] 和密度峰值聚类算法 (DPC) [28]。每种算法都具有不同的分类能力。

网络安全服务峰矩阵评估2024
对北美数字技术的越来越依赖促进了对强大网络安全服务的需求的显着增加。云计算,IoT设备和远程工作的迅速采用已扩大了网络犯罪分子的攻击表面,使组织更容易受到复杂威胁的影响,例如数据泄露和勒索软件。这对包括复杂的网络威胁,熟练的专业人员短缺以及严格的监管要求,为企业带来了紧迫的挑战。

产品产品 - 清洁峰峰会新加坡
•NTU稀缺团队的一部分计划和毒性研究核心团队•使用HydromeTallurgy开发了一种有机过程,使用橙皮•开发过程目前正在进行中,扩展了橙皮超越橙皮并探索其他食物浪费选择•PILOT LINE位于SWM的物理地点;正在进行的商业评估

嵌段共聚物定向自组装基础
对于需要高分辨率图案化的实验室成员,嵌段共聚物定向自组装可以作为更传统的光刻技术的低成本、高通量补充。嵌段共聚物由两种或多种化学性质不同的聚合物端对端结合而成。当将嵌段共聚物溶液旋涂到基材上时,可以加热薄膜以诱导自组装。在此过程中,组成聚合物根据其 Flory-Huggins 相互作用参数 (χ) 相互排斥,以达到其最小自由能位置。随着嵌段分离,同类聚合物会被同类聚合物吸引,从而形成周期性域。自组装域的形状取决于嵌段共聚物中的嵌段数以及这些嵌段的相对比例。[1] 本报告将重点介绍具有两种组成聚合物的二嵌段共聚物。在可实现的各种域形状中,对于光刻最实用的是分别使用 50:50 和 70:30 嵌段共聚物形成的薄片和圆柱体。
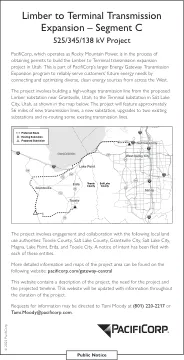
灵活至终端输电扩建 - C 段
该项目涉及从犹他州格兰茨维尔附近的拟建林伯变电站到犹他州盐湖城的终端变电站修建一条高压输电线,如下图所示。该项目将包括约 56 英里的新输电线、一个新变电站、对两个现有变电站的升级以及重新布置一些现有输电线。

基于前景原型的脑肿瘤的单发段
摘要:通过几乎没有学习的可能性增强脑肿瘤分割的潜力是巨大的。虽然几个深度学习网络(DNN)显示出令人鼓舞的分割结果,但它们都采用了大量的培训数据,以产生适当的结果。此外,对于大多数这些模型而言,一个突出的问题是在看不见的课程中表现良好。为了克服这些挑战,我们提出了一个单次学习模型,以基于单个原型相似性评分来分割脑磁共振图像(MRI)上的脑肿瘤。使用最近开发的几乎没有弹药的学习技术,通过支持和查询图像进行训练和测试,我们试图通过专注于包含前景类别的切片来获取明确的肿瘤区域。与使用整个图像集的其他最近的DNN不同。该模型的训练是以迭代方式进行的,在每个迭代中,随机切片中包含前景类别的随机抽样数据的剪辑被选为查询集,以及与支持集的同一样本的不同随机切片。为了将查询图像与类原型区分开,我们使用了基于非参数阈值的基于公制的学习方法。我们采用了具有60次训练图像和350次测试图像的多模式脑肿瘤图像分割(Brats)2021数据集。使用平均骰子得分和平均得分评估模型的有效性。实验结果提供的骰子得分为83.42,比文献中的其他作品还要大。此外,所提出的单发分割模型在计算时间,内存使用情况和数据数方面优于常规方法。

2022-25 年全龄段策略
大曼彻斯特地区有 10 个健康观察组织(附录 2),这项为期 3 年、适用于所有年龄段的战略描述了我们 10 个独立组织的共同目标,我们共同合作分享信息、专业知识和学习,以改变健康和社会护理服务,如全科医生护理、医院护理、牙科护理、药房护理和英格兰各地人们家中提供的护理。

提高了在发芽阶段预测苹果水果特征的准确性!
■词汇表1)基因组选择(GS):一种基于有关DNA差异的信息来预测和选择个人遗传能力的方法。关于DNA和果实特征差异的数据,使用大量品种和菌株作为训练数据对两者之间的关系进行建模,并且基于“基因组预测(GP)模型”预测个体的遗传能力。可以预测未来在发芽阶段可以实现的水果的特征。注2)全基因组关联研究(GWAS):一种使用数学公式来建模DNA与果实特征的差异与大量品种和菌株中的果实特征之间的关系,并在统计学上检测到果实特征和相关DNA的差异。一旦揭示了与果实性状相关的DNA差异,可以通过寻找DNA差异的附近来识别控制果实性状的候选基因。注意3)下一代序列:可以一次解码大量DNA序列的设备。注4)单核苷酸多态性(SNP):DNA是一种称为脱氧核糖核酸的物质,由四种类型的碱基组成:腺嘌呤(a),胸腺胺(T),鸟嘌呤(G)和细胞儿童(C)。品种之间的碱基差异称为单核苷酸多态性。注5)Infinium系统:Illumina Co.,Ltd.提供的单个核苷酸多态性检测系统。注6)GRAS-DI(由随机扩增子测序 - 主测序引导的基因分型)系统:一种由丰田汽车公司开发的单核苷酸多态性检测系统。 ■研究项目这项研究是在以下项目的支持下进行的:

Healdsburg的浮动光伏太阳能电段Healdsburg的浮动光伏太阳能电段
Healdsburg的废水处理设施是一种最先进的三级治疗系统,将原始污水处理成清洁和消毒的再生水。th是水存储在大型热塑性衬里的池塘中,并通过管道传达给农业使用者,从而减少了对珍贵地下水的需求。在炎热的夏季,遏制池会花藻类,需要阴影以减少藻类的生长并确保最高质量的再生水。