XiaoMi-AI文件搜索系统
World File Search System符号


向量符号架构简介及...
重要原则 1)每个实体都是同一个高维向量空间的元素 2)在向量中,信息分布在各个维度上 3)计算(算法)通过向量运算实现 4)评估向量(例如实体和计算结果)之间的关系
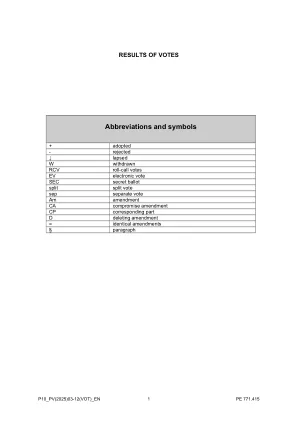
缩写和符号 - 欧洲议会
要求分开投票的ECR:§3第一部分“指出委员会确保欧洲学期的承诺促进竞争力,可持续性和社会公平的政策协调,以及不可持续发展目标和社会权利的欧洲柱面的一体化;第二部分“指出欧洲绿色协议仍然是该委员会的核心交付;” §10第一部分“强调需要创建财政缓冲区以应对财政可持续性挑战,确保足够的投资资源以及处理潜在的未来冲击和危机;”第二部分“强调促进竞争,可持续和包容性增长在支持长期财政稳定和弹性方面的重要性;” §29第一部分的整体文本没有任何话:“强调九个成员国没有符合他们在提交国家计划之前与民间社会,社会伙伴,地区当局和其他相关利益相关者进行政治磋商的义务;”第二部分§32第一部分文本整体上没有单词:“创建其他财政空间”第二部分第二部分

能源工程的符号回归
能源工程中的符号回归探讨了机器学习,以解决臭名昭著的资源波动引起的可再生能源挑战。符号回归,一种机器学习技术,可从没有预定义结构的数据中发现数学模型,从而提供了可解释和准确的模型。本文研究了符号回归在能源工程中的应用,尤其是在预测可再生能源输出(例如风速反对功率输出)方面,这些输出速度高度可变且无法预测。这项研究利用遗传编程来发展符号表达式,以模拟风能系统中的复杂关系。该方法包括收集和预处理数据,训练符号回归算法以及使用各种指标评估模型。结果证明了符号回归在创建预测模型方面的有效性,以优于准确性和可解释性的传统回归方法。通过捕获固有的数据模式,符号回归提供了一种有希望的方法来提高可再生能源系统的可靠性和效率。讨论强调了符号回归比传统方法的优势,包括更好的模型解释性和减少人类偏见,并建议未来的研究方向,以进一步提高该技术在能源工程中的适用性。


量化示例 - 符号 - 及以下 - ...
第一部分。对实验结果的讨论。前面论文中描述的结果表明,膜的电行为可以由图中所示的网络表示。1。电流可以通过为膜容量充电或通过与容量并联的电阻通过电阻来通过膜传递。离子电流分为由钠和钾离子(INA和IK)携带的成分,以及由氯化物和其他离子组成的小“泄漏电流”(I,I)。离子电流的每个组件都由驱动力确定,该驱动力可以方便地测量为电势差和具有电导尺寸的渗透系数。因此,钠电流(INA)等于钠电导率(9NA)乘以膜电位(E)和钠离子(ENA)平衡电位之间的差异。类似的方程式适用于'K和I,并在p上收集。 505。我们的实验表明GNA和9E是时间和膜电位的函数,但是ENA,EK,EL,CM和G可以将其视为恒定。可以通过说明:首先,将膜电位对渗透率的影响汇总会导致钠电导率的瞬时增加,并且降低但保持较慢但保持钾的增加速度的增加;其次,这些变化是分级的,并且可以通过重现膜来逆转。为了确定这些影响是否足以说明复杂现象,例如动作潜力和难治时期,有必要获得有关

Arqit Quantum Inc. - 反向拆分期权符号:ARQQ 新符号:ARQQ1
期权调整的决定和任何调整的性质由 OCC 根据 OCC 章程第 VI 条第 11 和 11A 节做出。期货调整的决定和任何调整的性质由 OCC 根据 OCC 章程第 XII 条第 3、4 或 4A 节(视情况而定)做出。对于期权和期货,每个调整决定都是根据具体情况做出的。调整决定基于当时可用的信息,并且可能会随着更多信息的出现或导致调整的公司事件条款发生重大变化而发生变化。


Ginkgo Bioworks Holdings,Inc .-反向拆分选项符号:DNA新符号:DNA1
根据OCC根据OCC细则,第VI条,第11和11A条进行调整的决心和任何调整的性质。根据OCC章程,第XII条,第3、4或4A条的规定调整期货和任何调整的性质,如适用。对于期权和期货,每个调整决定都是根据情况做出的。调整决策基于当时可用的信息,并且随着其他信息的可用信息,或者是否有实质性更改公司事件的实质性更改,以实现调整。

符号人工智能讲座2:知识图谱
2 DTD:文档类型定义,定义 SGML 系列标记语言(SGML、XML、HTML)文档类型的标记声明。通过合法元素和属性列表定义 XML 文档的合法组成部分。XSD:XML 模式定义:W3C 建议正式描述 XML 文档中的元素并验证文档中每一项内容 [Lagoze]。具体化:将语句视为资源的能力,从而对该语句做出断言(在 FOL [McCarthy'87,79] 中推理,与出处有关)。