XiaoMi-AI文件搜索系统
World File Search System纤维束

在共同空间内同时映射大脑个体发育和系统发育:标准化纤维束成像和应用
发育和进化对大脑组织的影响是复杂的,但又是相互关联的,正如皮层区域扩张在这些截然不同的时间尺度上的对应性所证明的那样。然而,仍然不可能同时研究皮层区域连接的个体发育和系统发育,这可能比异速测量与大脑功能更相关。在这里,我们提出了一个新框架,允许将人类(成年人和新生儿)和非人类灵长类动物(猕猴)的结构连接图整合到一个共同空间上。我们使用白质束来锚定共同空间,并利用皮层连接模式对这些束的独特性来探测区域专门化。这使我们能够定量研究进化和发育尺度上连接的差异和相似性,揭示大脑成熟轨迹,包括早产的影响,并在不同的大脑之间转换皮层图谱。我们的研究结果为神经解剖学成像的综合方法开辟了新途径。
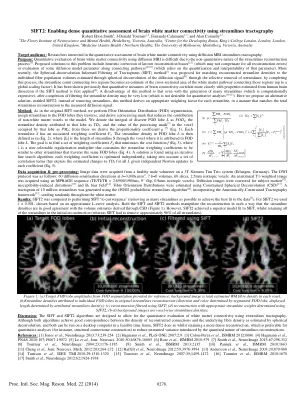
SIFT2:利用流线纤维束成像技术对大脑白质连接进行密集定量评估
目标受众:对使用扩散 MRI 流线纤维束成像定量评估大脑白质连接感兴趣的研究人员。目的:由于流线重建过程的非定量性质 [1],使用扩散 MRI 定量评估大脑白质连接非常困难。针对该问题提出的解决方案包括启发式校正已知的重建偏差 [2,3](可能无法补偿所有重建误差)或评估连接路径上某些扩散模型参数 [4,5,6](依赖于该参数的量化和可解释性)。最近,提出了球面反卷积信息纤维束成像滤波 (SIFT) 方法 [7],通过选择性去除流线,将重建的流线密度与通过扩散信号球面反卷积估计的单个纤维群体积 [8] 进行匹配;完成此过程后,连接两个区域的流线计数变为连接这些区域的白质通路横截面积的估计值(最高可达全局缩放因子)。之前已证明,如果首先应用 SIFT 方法 [9],大脑连接的定量测量与从人脑解剖估计的特性会更加密切相关。这种方法的缺点是,即使生成了许多流线(计算成本高昂),完成过滤后,流线密度可能非常低(这对于定量分析来说是不可取的 [10,11])。在这里,我们提出了一种替代解决方案,称为 SIFT2:此方法不是去除流线,而是为每条流线得出合适的加权因子,以使总流线重建与测量的扩散信号相匹配。方法:与原始 SIFT 方法一样,我们执行纤维方向分布 (FOD) 分割,将流线分配给它们穿过的 FOD 叶,并得出一个处理掩模,以减少非白质体素对模型的贡献。我们将离散 FOD 叶 L 的积分表示为 FOD L ,将归因于该叶的流线密度表示为 TD L ,将处理掩模 [7] 在该叶所占体素中的值表示为 PM L ;从这些中我们得出比例系数 μ [7](等式 1)。每条流线 S 都有一个关联的加权系数 FS 。FOD 叶 L 中的流线密度定义为(等式 2),其中 | SL | 是流线 S 穿过归因于 FOD 叶 L 的体素的长度。目标是找到一组加权系数 FS ,以最小化成本函数 f(等式 3),其中 λ 是用户可选择的正则化乘数,它将流线加权系数约束为与穿过相同 FOD 叶的其他流线相似(等式 4)。使用迭代线搜索算法可以找到解决方案:每个加权系数都经过独立优化,同时考虑一组相关项,这些相关项表示在对每个系数进行独立牛顿更新的情况下所有 L 的 TD L 的估计变化(等式 5)。数据采集和预处理:图像数据是从健康男性志愿者的 3T Siemens Tim Trio 系统(德国埃尔朗根)上采集的。DWI 协议如下:60 个弥散敏化方向,b =3,000s.mm -2,7 b =0 体积,60 个切片,2.5mm 各向同性体素。使用 MPRAGE 序列(TE/TI/TR = 2.6/900/1900ms,9° 翻转,0.9mm 各向同性体素)获取解剖 T1 加权图像。对弥散图像进行了校正以适应受试者运动 [12]、磁化率引起的扭曲 [13] 和 B 1 偏置场 [14]。使用约束球面反卷积 (CSD) [15] 估计纤维取向分布。使用 iFOD2 概率流线算法 [16] 生成了 1000 万条流线的纤维束图,该算法结合了解剖约束纤维束成像框架 [17] ,随机分布在整个白质中。结果:将 SIFT2 与执行 SIFT“收敛”(移除尽可能多的流线以实现与数据的最佳拟合 [7] )进行了比较。对于 SIFT2,我们使用了 λ = 0.001,这是基于近似 L 曲线分析选择的。SIFT 和 SIFT2 方法都以这样一种方式操纵重建,使得流线密度与通过 CSD 得出的体积估计值高度一致(图 1)。然而,SIFT2 实现了比 SIFT 更优秀的模型拟合,同时保留了初始重建中的所有流线(而 SIFT 必须去除大约 96% 的流线)。根据近似 L 曲线分析选择。SIFT 和 SIFT2 方法都以流线密度与通过 CSD 得出的体积估计值高度一致的方式操纵重建(图 1)。然而,SIFT2 实现了比 SIFT 更好的模型拟合,同时保留了初始重建中的所有流线(而 SIFT 必须删除大约 96% 的所有流线)。根据近似 L 曲线分析选择。SIFT 和 SIFT2 方法都以流线密度与通过 CSD 得出的体积估计值高度一致的方式操纵重建(图 1)。然而,SIFT2 实现了比 SIFT 更好的模型拟合,同时保留了初始重建中的所有流线(而 SIFT 必须删除大约 96% 的所有流线)。

深部脑刺激的神经影像学进展
摘要:深部脑刺激是多种脑部疾病的成熟疗法,其潜在适应症正在迅速扩大。神经影像学通过改进解剖结构描绘以及最近脑连接组学的应用,推动了深部脑刺激领域的发展。这些疾病的旧有病变定位理论已经发展为较新的基于网络的“回路病”,通过使用先进的神经影像学技术(如扩散纤维束成像和 fMRI),可以直接评估体内这些脑回路。在这篇综述中,我们结合使用超高场 MR 成像和扩散纤维束成像来强调目前美国批准的深部脑刺激适应症的相关解剖结构:特发性震颤、帕金森病、耐药性癫痫、肌张力障碍和强迫症。我们还回顾了有关使用 fMRI 和扩散纤维束成像来了解深部脑刺激在这些疾病中的作用,以及它们在手术定位和设备编程中的潜在用途的文献。

弥漫性中线神经胶质瘤的多个下述转移接受肿瘤治疗场:病例报告和文献审查
一名28岁的男性患者出现头痛和头晕,伴随着左肢无力,恶心和车祸创伤后呕吐。在初步体格检查中,左肢强度为4级和缺点。没有异常的家庭和病史。随后,他接受了成像检查,头骨计算机断层扫描(CT)和磁共振成像(MRI)都表明右丘脑中有出血的质量(图1)。质量是异质的,具有不同的组成以及不规则的坏死区域,具有增强。病变和周围白质纤维束的术前三维重建表明,将主要的功能性纤维束推到了病变的周围和前部。

使用扩散 MRI 多室模型和纤维束测量技术对老年抑郁症和冷漠症患者进行大脑微结构评估
晚年抑郁症 (LLD) 很常见,会导致残疾,并使患痴呆症的风险加倍。冷漠症可能会造成认知能力下降的额外风险,但对其病理生理学的了解尚不清楚。虽然已经使用扩散张量成像 (DTI) 评估了白质 (WM) 的改变,但该模型不能准确地表示 WM 的微观结构。我们假设更复杂的多室模型将提供 LLD 和冷漠症的新生物标志物。研究纳入了 56 名个体(LLD n = 35,26 名女性,75.2 ± 6.4 岁,冷漠评估量表得分(41.8 ± 8.7)和健康对照者,n = 21,16 名女性,74.7 ± 5.2 岁)。在本文中,我们通过沿纤维束直接插入微观结构指标,采用基于纤维束的方法来研究 LLD 和冷漠症的新型扩散模型生物标志物。我们进行了多元统计分析,并结合主成分分析来降维数据。然后,我们通过展示文献中经典报道的 LDD 修改,同时报告 LLD 中冷漠的生物学基础的新结果,测试了我们框架的实用性。最后,我们旨在研究冷漠与不同纤维束中微观结构之间的关系。我们的研究表明,新的纤维束,如纹状体运动前束,可能与 LLD 和冷漠有关,这为重度抑郁症中的冷漠机制带来了新的启示。我们还发现了 5 个不同束的扩散 MRI 指标的统计变化,这些变化此前曾在严重认知障碍痴呆症中报告过,这表明这些束之间的这些改变都与动机和认知有关,可能解释了冷漠如何成为退行性疾病的前驱阶段。

使用以超高梯度强度获取的扩散 MRI 数据来改善常规质量数据的纤维束成像
在人类连接组计划的带动下,具有超高梯度强度的扫描仪的开发显著提高了体内扩散 MRI 采集的空间、角度和扩散分辨率。可以利用改进的数据质量来更准确地推断微观结构和宏观结构解剖结构。然而,这种高质量的数据只能在全世界少数几台 Connectom MRI 扫描仪上采集,而且由于硬件和扫描时间的限制,在临床环境中仍然无法使用。在本研究中,我们首先更新了基于纤维束成像的手动注释主要白质通路的经典协议,以使其适应当今最先进的扩散 MRI 数据所能产生的更大体积和更大变化的流线。然后,我们使用这些协议手动注释来自 Connectom 扫描仪的数据中的 42 条主要通路。最后,我们表明,当我们使用这些手动注释的通路作为具有解剖邻域先验的全局概率纤维束成像的训练数据时,我们可以在质量低得多、更广泛可用的弥散 MRI 数据中对相同的通路进行高精度、自动重建。这项工作的成果包括来自 Connectom 数据的 WM 通路的全新综合图谱,以及我们的纤维束成像工具箱的更新版本,即受基础解剖学约束的 TRActs (TRACULA),该工具箱使用该图谱中的数据进行训练。图谱和 TRACULA 均作为 FreeSurfer 的一部分公开分发。我们首次全面比较了 TRACULA 与更传统的多感兴趣区域自动纤维束成像方法,并首次演示了在高质量 Connectom 数据上训练 TRACULA 以造福使用更温和的采集协议的研究。

如果我们知道白质通路从哪里开始、在哪里结束以及在哪里不去,那么通过扩散 MRI 纤维束成像得到的脑连接在解剖学上可以非常准确
1. 范德堡大学成像科学研究所,范德堡大学,美国田纳西州纳什维尔 2. 范德堡大学医学中心放射学和放射科学系,美国田纳西州纳什维尔 3. 法国波尔多大学 CEA 法国国家科学研究院神经退行性疾病研究所 - UMR 5293 神经功能图像组 4. 加拿大舍布鲁克大学舍布鲁克连接成像实验室 (SCIL) 5. 范德堡大学电气工程与计算机科学系,美国田纳西州纳什维尔 6. 亨利 M. 杰克逊基金会,美国马里兰州贝塞斯达 7. 美国马里兰州贝塞斯达国家生物医学成像和生物工程研究所 8. 美国田纳西州纳什维尔范德堡大学医学中心生物医学工程系 * Kurt G Schilling 电子邮件: kurt.g.schilling.1@vumc.org


通过可解释的人工智能了解阿尔茨海默病的结构连通性
在以下工作中,我们使用深度 BrainNet 卷积神经网络 (CNN) 的改进版本,该网络在阿尔茨海默病 (AD) 和轻度认知障碍 (MCI) 患者的扩散加权 MRI (DW-MRI) 纤维束成像连接组上进行训练,以更好地了解该疾病的结构连接组学。我们表明,使用相对简单的连接组 BrainNetCNN 对大脑图像进行分类和可解释的 AI 技术,可以强调与 AD 有关的大脑区域及其连接。结果表明,组间结构差异较大的连接区域也是先前 AD 文献中报道的区域。我们的研究结果支持了对结构连接组进行深度学习是一种强大的工具,可以利用来自扩散 MRI 纤维束成像的连接组内的复杂结构。据我们所知,我们的贡献是第一个应用于退行性疾病结构分析的可解释 AI 工作。关键词:结构连接组、扩散加权 MRI、深度学习、显著图、阿尔茨海默病

猕猴顶上小叶 5 区 (PE) 细分的相应解剖结构揭示了与人类相似的连接模式
基于影像特征将动物脑作为跨物种研究的工具,可为揭示人类大脑的综合分析提供更多潜力。先前的研究表明,人类布罗德曼5区(BA5)和恒河猴的PE为同源区域,均参与手臂运动中触觉过程中的深度和方向信息处理。但最近的研究表明,BA5与PE并不同源,根据细胞构架,BA5被细分为三个不同的亚区域,PE可细分为PEl、PEla和PEm,BA5与PE之间各亚区域之间的物种同源关系尚不明确。同时,基于白质纤维束解剖连接对PE的细分需要更多的验证。本研究依据白质纤维束解剖连接对恒河猴的PE进行了细分。基于概率纤维追踪技术定义前侧和背侧两个PE亚区,最后针对BA5和PE亚区绘制具有预定义同源靶区的连通性指纹,揭示结构和功能特征,并给出识别出的同源对应关系。