XiaoMi-AI文件搜索系统
World File Search System脑电




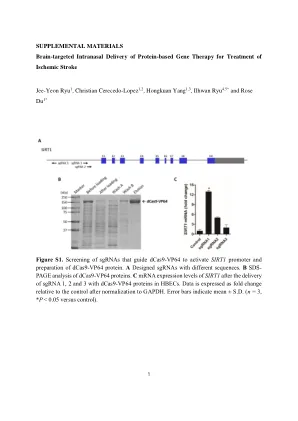
补充材料脑脑内脑内...
图S10。 建立用于研究缺血性中风的永久性脑动脉闭塞(PMCAO)模型。 PMCAO手术程序。 CCA,ICA和ECA暴露了,将硅细丝插入CCA和ICA直到到达MCA(有关详细信息的材料和方法)。 用biorender.com创建的数字。 b TTC染色大脑的代表性照片。 白色区域代表PMCAO的梗塞区域。 PMCAO后1、3和6小时,缺血性大脑中SIRT1的mRNA表达水平。 数据表示为折叠变化,相对于假手术组在归一化为GAPDH之后。 误差条表示平均值±S.D. (n = 3)(每组n = 10只小鼠, * p <0.05,*** p <0.001对假手术)。 缩写:CCA,常见的颈动脉; ICA,颈内动脉; ECA,外部颈动脉; MCA,中大脑中动脉; TTC,2,3,5-三苯基四唑氯化物。图S10。建立用于研究缺血性中风的永久性脑动脉闭塞(PMCAO)模型。PMCAO手术程序。CCA,ICA和ECA暴露了,将硅细丝插入CCA和ICA直到到达MCA(有关详细信息的材料和方法)。用biorender.com创建的数字。b TTC染色大脑的代表性照片。白色区域代表PMCAO的梗塞区域。PMCAO后1、3和6小时,缺血性大脑中SIRT1的mRNA表达水平。数据表示为折叠变化,相对于假手术组在归一化为GAPDH之后。误差条表示平均值±S.D.(n = 3)(每组n = 10只小鼠, * p <0.05,*** p <0.001对假手术)。缩写:CCA,常见的颈动脉; ICA,颈内动脉; ECA,外部颈动脉; MCA,中大脑中动脉; TTC,2,3,5-三苯基四唑氯化物。

全脑脑
全脑脑是复杂的大脑畸形,这是由于早期胎儿发育过程中大脑不完全的裂解而导致的。这种情况的特征在于普罗德龙(胚胎的前脑)的失败,以正确分成大脑半球的双叶,导致影响大脑和面部特征的异常。根据大脑分裂的严重程度,全脑脑分为四种类型:Alobar Holoporsencephaly:最严重的形式,其中没有脑半球分离,导致单个脑室心室和一个单裂脑。半月骨全脑脑:大脑半球部分分离,大脑的结构在某种程度上介于Alobar和Lobar之间。Lobar Holoporsencephaly:最少的严重形式,具有更好的脑半球分离和更正常的大脑结构。中半球间变体(syntelcephaly):半球在大脑中间没有分离,但可能在前和后方面更正常地分裂。是什么导致全脑脑?

基于对数梅尔频谱图和卷积循环神经网络的脑电驾驶疲劳检测
驾驶员疲劳检测是减少事故、提高交通安全的重要手段之一,其主要挑战在于如何准确识别驾驶员的疲劳状态。现有的检测方法包括基于面部表情和生理信号的打哈欠、眨眼等,但基于面部表情的检测结果会受到光照和环境影响,而脑电信号是直接反应人的精神状态的生理信号,对检测结果的影响较小。本文提出一种基于EEG的对数梅尔语谱图和卷积循环神经网络(CRNN)模型来实现驾驶员疲劳检测,这种结构可以发挥不同网络的优势,克服单独使用各个网络的劣势。其流程为:首先将原始脑电信号经过一维卷积的方法实现短时傅里叶变换(STFT),并经过梅尔滤波器组得到对数梅尔谱图,然后将得到的对数梅尔谱图输入到疲劳检测模型中,完成脑电信号的疲劳检测任务。疲劳检测模型由6层卷积神经网络(CNN)、双向循环神经网络(Bi-RNN)和分类器组成。在建模阶段,将谱图特征输送到6层CNN自动学习高级特征,从而在双向RNN中提取时间特征,得到谱图-时间信息。最后,通过由全连接层、ReLU激活函数和softmax函数组成的分类器得到警觉或疲劳状态。本研究的实验是在公开可用的数据集上进行的。结果表明,该方法能够准确区分警觉与疲劳状态,且稳定性较高;此外,还将四种现有方法的性能与本文方法的结果进行了比较,均表明本文方法能够取得目前为止的最好效果。

研究论文基于双向LSTM和注意力机制的表情脑电多模态情绪识别方法
由于人类情绪的复杂性,不同的情绪特征之间存在一定的相似性,现有的情绪识别方法存在特征提取困难、准确率不高的问题,为此提出一种基于双向长短期记忆和注意机制的表情脑电多模态情绪识别方法。首先基于双线性卷积网络(BCN)提取面部表情特征,将脑电信号变换为三组频带图像序列,利用BCN对图像特征进行融合,得到表情脑电多模态情绪特征。然后通过带有注意机制的长短期记忆在时序建模过程中提取重要数据,有效避免采样方法的随机性或盲目性。最后,设计一种具有三层双向长短期记忆结构的特征融合网络,将表情与脑电特征进行融合,有助于提高情绪识别的准确率。在MAHNOB-HCI和DEAP数据集上,基于MATLAB仿真平台对所提方法进行测试。实验结果表明,注意机制可以增强图像的视觉效果;且与其他方法相比,所提方法可以更有效地从表情和脑电信号中提取情感特征,情绪识别的准确率更高。


电是1.((stationo, parallel) 时是电2, (charges, ...
21 de ago. de 2024 — 当电 2,(电荷,电路)通过获得或失去 3.(分支,电子)在 n 物体上积累时,电就是 1.((静止,平行)......