XiaoMi-AI文件搜索系统
World File Search System输入数据
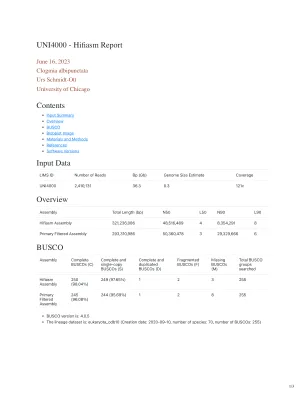
输入数据概述BUSCO UNI4000 -CDN
对于每个DiDail omni-c文库,将染色质与甲醛固定在原子核中,然后提取。用DNase I消化了固定的染色质,将染色质末端修复并连接到生物素化桥适配器,然后将含有末端的衔接子接近粘合。接近连接后,将交联后逆转并纯化了DNA。纯化的DNA以去除未结扎片段内部的生物素。使用NEBNEXT Ultra酶和Illumina兼容适配器生成测序文库。在每个文库富集之前,使用链霉亲和素珠分离含生物素的片段。库是在Illumina Hiseqx平台上测序的,以产生约30倍的序列覆盖率。然后Hirise使用MQ> 50读脚手架的读数(有关数字,请参见上面的“读取对”)。

根据...更新了 cba ler 的输入数据和假设...
CE TSO 还考虑了对较早的历史频率数据进行追溯操作的可能性,以使其频率现象与 CE SA 近年来经历的频率现象相似。这种操作将特别针对 LLEFD(最不寻常的 LLFD),这是对 CBA 结果影响最大的方面之一。较近的 LLEFD 将在幅度和持续时间方面进行操纵,以使其类似于最近发生的 LLEFD。CE TSO 确实最近实施了多项结构和运营对策来缓解 LLEFD。

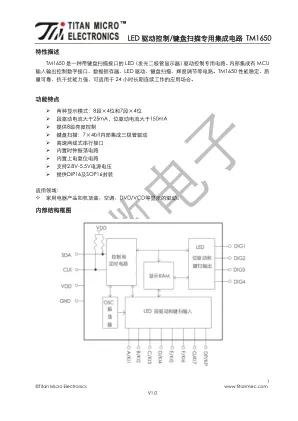
LED 驱动控制/键盘扫描专用集成电路TM1650
接口和TM1650 通信,在输入数据时当SCL 是高电平时,SDA 上的信号必须保持不变;只有SCL 上的 时钟信号为低电平时,SDA 上的信号才能改变。数据输入的开始条件是SCL 为高电平时,SDA 由高变

Jiles-Atherton 磁滞模型的改进与非正弦激励下 软磁材料复杂磁滞准确模拟
输入数据: 1 ) i = 0 时刻: H (0) = 0 , M (0) = 0 , H m = 0 2 )磁化周期 0 — T 各时刻的磁密 B ( t ) 3 )模型初始参数及动态参数 R 、 v 、 α 、 k 对应函数 4 )磁化反转点磁密存储序列 [ B m (1), ⋅⋅⋅ , B m ( z )]
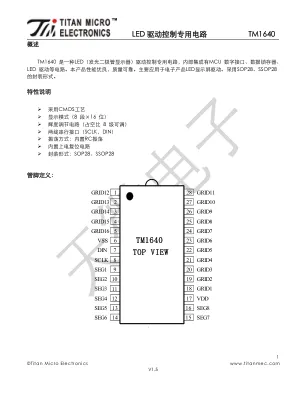
LED 驱动控制专用电路TM1640
微处理器的数据通过两线总线接口和TM1640 通信,在输入数据时当CLK 是高电平时,DIN 上的信号必须 保持不变;只有CLK 上的时钟信号为低电平时,DIN 上的信号才能改变。数据的输入总是低位在前,高位在后 传输.数据输入的开始条件是CLK 为高电平时,DIN 由高变低;结束条件是CLK 为高时,DIN 由低电平变为高 电平。

推荐引文 推荐引文 Gema, Ari Juliano (2022)“Masalah Penggunaan Ciptaan Sebagai Data Masukan Dalam Pengembangan Artificial Intelligence Di Indonesia”,技术与经济法杂志:卷。 1:第 1 号,第 1 条。DOI:10.21143/TELJ.vol1.no1.1000 网址:https://scholarhub.ui.ac.id/telj/vol1/iss1/1
摘要 当前人工智能(AI)的发展非常迅速。输入数据的可用性很重要,因为它对AI系统如何开发有很大影响。在人工智能开发中使用受版权保护的创作作为输入数据也是不可避免的。本文试图探讨第 14 号法律的规定。2014 年第 28 号关于版权 (UUHC) 的法律,涉及使用创作作为印度尼西亚人工智能发展的输入数据。根据研究结果得知,在印度尼西亚使用创作物作为人工智能发展的输入数据,基本上仍然必须尊重创作者对其创作物的专有权利。如果您使用版权保护期已过的作品和使用开放许可的作品,以及如果您使用版权法中允许使用作品的版权限制条款,则可以在未经创作者许可的情况下将作品用作输入数据未经创作者许可,但需满足以下条件:某些。本文建议将人工智能组织者视为电子系统组织者,并承担注册义务,以便他们使用创作物作为输入数据时可以被要求公开信息,有必要制定UUHC的衍生法规,进一步解释有关版权限制的规定,有必要对复制权实施非排他性许可(综合许可),以促进将创作物作为商业和非商业用途的输入数据的许可程序,政府需要促进对版权保护期已过的作品和使用开放许可的作品的访问,并对版权法进行修改,以预测未来人工智能的发展。

Raven HBV-EC模型的集成实现,并描述了多模型合奏评估中的不确定性
尽管水文建模方面取得了进步,但在模拟和预测中量化了固有的不确定性仍然是必不可少的。这些不确定性来自诸如初始条件,输入数据,参数估计和模型结构之类的来源。虽然水文界越来越关注不确定性评估,但大多数研究都集中在特定模型中的输入数据和参数不确定性上,使模型结构不确定性未经探索。这项研究介绍了一种基于整体的新方法来评估水文模型不确定性,同时强调模型结构和输入数据不确定性。研究利用Raven水文建模框架创建了水文模型的合奏。此合奏会与噪声进一步扰动,以表示输入数据不确定性。在加拿大圣龙流域的西南部分展示了该方法,评估了模型集合针对观察到的水流。正向贪婪方法有助于从集合中选择子模型,增强可靠性并降低模型计数。通过确保每个标准符合预定义的性能标准,采用此方法来完善模型池。此外,还评估了校准不确定性和输入数据不确定性。结果强调了多模型合奏在降低各种不确定性来源的重要性,而噪声扰动的数据可提高可靠性。这项研究促进了对水文模型不确定性评估的理解,并强调了一种全面的多模型方法的重要性,该方法解释了结构性,输入数据和校准不确定性,以实现强大的流量模拟和预测。

计算机和计算机化会计系统
2. 数据验证:通过将输入数据与某些预定义标准或已知数据进行比较,确保输入数据的准确性和可靠性。此验证由“错误检测”和“错误更正”程序完成。控制机制将实际输入数据与预定标准进行比较,旨在检测错误,而错误更正程序则为输入正确的数据提供建议。使用已知数据验证客户的个人识别码 (PIN)。如果不正确,则建议指示 PIN 无效。验证 PIN 后,还会检查提款金额,以确保提款金额不超过预先指定的提款限额。

数据稀缺药物协同专家组合......
药物-靶标相互作用预测 (DTI) 在药物发现和临床应用等各种应用中都至关重要。DTI 预测中广泛使用的输入数据有两个视角:内在数据表示药物或靶标的构造方式,外在数据表示药物或靶标与其他生物实体的关系。然而,对于某些药物或靶标,尤其是那些不受欢迎或新发现的药物或靶标,输入数据的两个视角中的任何一个都可能很稀缺。此外,特定相互作用类型的真实标签也可能很稀缺。因此,我们提出了第一种方法来解决输入数据和/或标签稀缺情况下的 DTI 预测。为了使我们的模型在只有一个输入数据视角可用时发挥作用,我们设计了两个独立的专家分别处理内在数据和外在数据,并根据不同的样本自适应地融合它们。此外,为了使这两个视角相互补充并弥补标签稀缺问题,两个专家以相互监督的方式相互协同,以利用大量未标记数据。在输入数据稀缺性和/或标签稀缺性不同的 3 个真实数据集上进行的大量实验表明,我们的模型显著且稳定地优于现有技术,最大改进为 53.53%。我们还在没有任何数据稀缺的情况下测试了我们的模型,它也优于当前方法。代码可在 https://github.com/BUPT-GAMMA/MoseDTI 获得。