
机构名称:
¥ 1.0
我们提出了一种采用多个内核的量子投影学习 (QPL) 的理论分析,并通过表征误差分析突出其优势。在先前使用单个基于量子内核的方法的研究基础上,我们进一步研究了一种结合多个高斯内核的量子投影框架,用于低资源口头命令识别。我们的实证结果与我们的理论见解一致,表明基于多个内核的方法可以进一步提高 QPL 的性能。通过利用量子到经典的投影输出嵌入,我们将其与原型网络相结合以进行声学建模。当使用 CommonVoice 中的阿拉伯语、楚瓦什语、爱尔兰语和立陶宛语低资源语音进行评估时,我们提出的方法比循环神经网络和基于单个内核的分类器基线平均高出 +5.28%。
利用量子多核学习方法
主要关键词



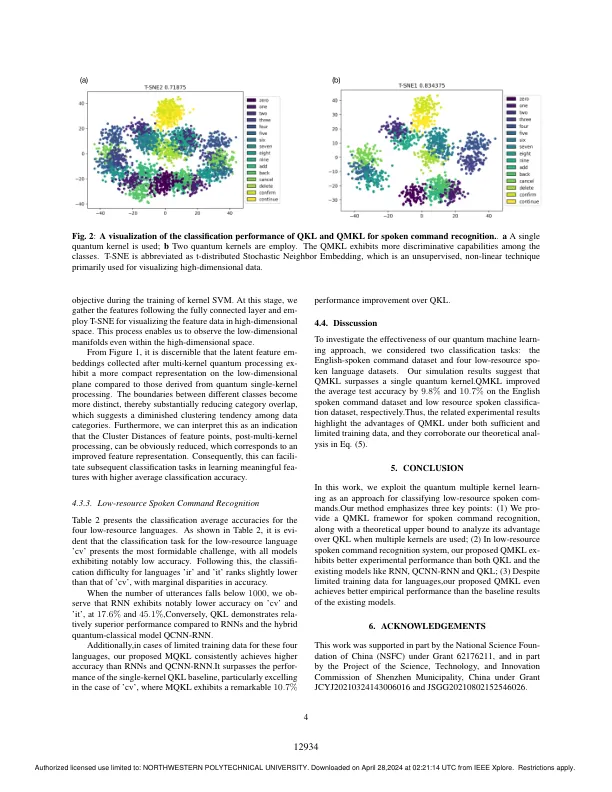

相关文件推荐





























