XiaoMi-AI文件搜索系统
World File Search System不切实际

使用核微反应器工艺热进行生物转化和农业过程的可行性
结果与讨论:高温过程的火用效率值范围为 72% 至 100%,而低温过程的火用效率值范围为 2% 至 53%。这些效率取决于每个微反应器设计的可用源温度。产生净功率和使用工艺热之间存在权衡,特别是对于高温过程。考虑了三个热交换器位置:涡轮机之前(600 ℃ )、涡轮机和再生器之间(370 ℃ )和再生器之后(192 ℃ )。气化等高温过程需要的温度太高,不切实际。中温过程更适合涡轮机和再生器之间的热交换器,同时也可在涡轮机之前操作。巴氏灭菌和厌氧消化等低温过程可以在再生器后使用废热,不会影响发电。这些发现对于优化核微反应器的热量利用和与全球气候倡议保持一致非常有价值。

预测-解释谬误:机器学习科学应用中的普遍问题
我强调了一个在机器学习的科学应用中普遍存在的问题,它可能导致严重扭曲的推论。我称之为预测-解释谬误。当研究人员使用预测优化模型进行解释而不考虑相关权衡时,就会出现这种谬误。这是一个问题,至少有两个原因。首先,预测优化模型通常会故意产生偏差和不切实际,以防止过度拟合。在其他情况下,它们的结构非常复杂,很难或不可能解释。其次,在相同或相似数据上训练的不同预测模型可能会以不同的方式产生偏差,因此它们可能预测得同样好,但给出的解释却相互矛盾。在这里,我以非技术性的方式介绍了预测和解释之间的权衡,并提供了来自神经科学的说明性示例,最后讨论了一些可用于限制问题的缓解因素和方法。
![arXiv:2403.00260v1 [cs.CL] 2024 年 3 月 1 日](/simg/f\f9197234520089f0922e9140c06c6ac03608c9c9.png)
arXiv:2403.00260v1 [cs.CL] 2024 年 3 月 1 日
本文研究了如何使用大型语言模型 (LLM) 从全篇材料科学研究论文中提取聚合物纳米复合材料 (PNC) 的样本列表。挑战在于 PNC 样本的复杂性,它们在整个文本中散布着许多属性。注释 PNC 上的详细信息的复杂性限制了数据的可用性,由于创建全面的命名实体跨度注释的挑战,传统的文档级关系提取技术变得不切实际。为了解决这个问题,我们为这项任务引入了一个新的基准和评估技术,并以零样本方式探索了不同的提示策略。我们还结合了自一致性来提高性能。我们的研究结果表明,即使是先进的 LLM 也很难从一篇文章中提取所有样本。最后,我们分析了在这个过程中遇到的错误,将它们分为三个主要挑战,并讨论了未来研究中克服这些挑战的潜在策略。


在黎曼框架内通过 CNN 特征的协方差池对 GPR 信号进行分类
探地雷达 (GPR) 是一种成像系统,可用于观察现场地下情况,以研究土壤的层组成或埋藏物体的存在。由于地面的电磁特性,此类图像通常具有非常低的信噪比 (SNR)。此外,根据设计,埋藏物体被观察为双曲线,其形状可能与物体类型(例如空腔或管道)相关联。在这种情况下,埋藏物体的分类在民用应用中非常重要,例如恢复埋藏天然气管道的位置 [1] 或军事应用,例如地雷探测 [2]。为了进行这种识别,一些研究考虑使用信号反演技术 [3] 来提高 SNR,以便地球物理学家进行手动解释。当需要处理大量图像时,这种解决方案可能不切实际,因为它需要专门的人力资源。因此,自动识别方法已成为必需,并受到社区的关注。GPR 信号的自动分类分两步进行。首先,感兴趣区域(ROI)对应于

英国皇家生物学会对环境、食品和乡村事务部咨询意见的回应...
有利的等位基因来自杂交不切实际或不可能的种群;它甚至允许合理设计新的等位基因。1 这可以在一代中实现,而不会稀释遗传价值。此外,目前的家养育种池通常利用该物种中可用的一小部分遗传变异。野生亲属是未来农业的关键等位基因来源(例如,面对不断变化的气候条件),重新测序项目正在确定等位基因差异的功能。现在可以通过等位基因替换或使用基因编辑重新创建突变将有益的“野生”等位基因直接整合到精英种质中。这种遗传“再野化”应用可以帮助减少遗传侵蚀并保护养殖和驯养动物的遗传多样性。2 应该指出的是,在畜群层面,家养物种健康和福利的普遍改善可能伴随着家畜种群遗传多样性的增加。3

因纽特人高等教育战略
通过调查和访谈从因纽特学生那里获得的反馈; 不切实际地期望因纽特学生和非土著学生的生活和旅行费用相同; 因纽特学生更需要其他家庭支持,包括儿童保育。 ii 还需要为校园内的因纽特学生、社区层面的因纽特 PSE 考生以及为学生在高中阶段取得成功奠定更好的基础提供其他支持。还需要更高水平的国家协调来管理、监督并为这项举措提供因纽特领导。为了开始缩小这一差距并在未来 10 年内使因纽特 PSE 毕业生人数翻一番(与现状预测相比),需要 4.16 亿美元,其中 3.12 亿美元将直接用于资助学生。此外,还需要资金用于:
2038.pdf
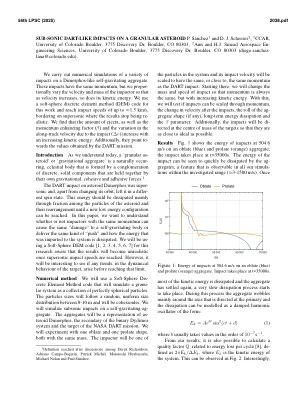
简介 正如我们今天的理解,“颗粒小行星”或“重力聚集体”是一种自然形成的天体,它是由离散的固体成分聚集而成,这些成分通过自身的重力、内聚力和附着力 1 结合在一起。DART 对小行星 Dimorphos 的撞击是超音速的,除了改变其轨道外,还使其处于不同的自旋状态。这些能量应主要通过小行星粒子之间的摩擦和它们的重新排列而消散,直到达到新的低能量结构。在本文中,我们想要了解具有相同动量的撞击者是否能对自引力体造成相同的“损害”或提供相同的“推力”,以及传递给系统的能量是如何消散的。我们将使用 Soft-Sphere DEM 代码 [1、2、3、4、5、6、7] 进行这项研究,因为我们知道一旦达到超音速撞击速度,结果将变得不切实际。然而,在达到该极限之前,观察目标的动态行为是否会出现任何趋势将会很有趣。

从全...
本文研究了使用大型语言模型(LLM)从全长材料科学研究论文中提取聚合物纳米复合材料(PNC)的样本清单。挑战在于PNC样品的复杂性质,这些属性具有散布在整个文本中的许多属性。关于PNCS的注释详细信息的复杂性限制了数据的可用性,从而使文档级别级别的关系提取技术不切实际,这是由于综合命名实体的挑战跨度跨度。为了解决这个问题,我们为此任务介绍了一种新的基准和评估技术,并以零拍的方式探索了不同的提示策略。我们还结合了提高性能的自我一致性。我们的发现表明,即使是先进的LLMS陷入困境,也可以从文章中提取所有样本。最后,我们分析了此过程中遇到的错误,将它们归类为三个主要挑战,并讨论了未来研究的潜在策略以克服它们。

lethe:便携式,异步安全删除-CRSS
加密擦除是一种替代,有效的安全删除技术;它在存储数据并通过删除关联的密钥来擦除数据之前,将用户数据加密。数据块上细粒的加密擦除片段对幼稚的加密擦除的不切实际存储要求;不仅需要存储每个密钥,而且每个密钥都必须擦除。最新的安全删除系统使用大型擦除存储的技术解决此问题,该技术在树层次结构中递归使用加密擦除,以将所需量的键存储量减少到单个键。不幸的是,由于其同步管理加密密钥和数据以避免数据损坏,因此现有的最新安全删除系统患有高IO潜伏期。这些现有的安全删除系统也不灵活,因为它们在块层管理加密,并且无法使用存储系统使用的文件系统抽象(例如,云存储,网络文件系统和保险丝存储系统)。