XiaoMi-AI文件搜索系统
World File Search System任务完成

基于模拟的机器人辅助手术训练的多感官指导和反馈:视觉,触觉和视觉效果的初步比较
摘要 - 如今,机器人辅助手术培训越来越依赖于基于计算机的模拟。但是,这种培训技术的应用仍仅限于实践培训的早期阶段。为扩大模拟器的实用性,最近研究了多感官反馈增强。本研究旨在将视觉和触觉域中的初始预测(指导)和随后的基于错误的基于错误(反馈)训练增强结合起来。32名参与者通过使用DA Vinci Research套件的外科医生控制台进行了30项虚拟现实任务的重复。这些受训者被随机且平均分为四组:一组没有训练增强,而其他小组分别进行了视觉,触觉和视觉狂热的增强。结果表明,在所有实验组的对照组的任务完成功能中,最初是由指南引入的显着改进。在准确性方面,实验组在训练结束时表现优于对照组。特定的视觉引导和触觉反馈在误差减少中起着重要作用。对长期学习的进一步研究可以更好地描述这些感觉域中的指导和反馈的最佳组合。
![arXiv:2412.05115v1 [quant-ph] 2024 年 12 月 6 日](/simg/d\d34385a72726c41566258b9d7b5eb2868b816426.webp)
arXiv:2412.05115v1 [quant-ph] 2024 年 12 月 6 日
实时解码是未来容错量子系统的关键要素,但许多解码器太慢,无法实时运行。先前的研究表明,在有足够的经典资源的情况下,并行窗口解码方案可以在解码时间增加的情况下可扩展地满足吞吐量要求。但是,窗口解码方案要求将某些解码任务延迟到其他解码任务完成为止,这在时间敏感的操作(例如 T 门传送)期间可能会出现问题,导致程序运行时间不理想。为了缓解这种情况,我们引入了一种推测窗口解码方案。从经典计算机架构中的分支预测中汲取灵感,我们的解码器利用轻量级推测步骤来预测相邻解码窗口之间的数据依赖关系,从而允许同时解决多层解码任务。通过最先进的编译管道和详细的模拟器,我们发现与之前的并行窗口解码器相比,推测平均可将应用程序运行时间缩短 40%。
音量 - 9 升将军(博士)VJ Sundaram PVSM,AVSM,VSM
印度国防研究与发展组织 (DRDO) 首次成功试飞了搭载多弹头独立再入飞行器 (MIRV) 技术的本土研制的烈火-5 导弹。这项名为“Divyastra 任务”的飞行试验在奥里萨邦的 Dr APJ 阿卜杜勒卡拉姆岛进行。各种遥测和雷达站跟踪和监视多弹头再入飞行器。该任务完成了设计参数。总理纳伦德拉·莫迪对参与执行这一复杂任务的 DRDO 科学家的努力表示赞赏。他在社交媒体平台 X 上的一篇帖子中表示:“我们为 DRDO 科学家参加 Divyastra 任务感到骄傲,这是搭载多弹头独立再入飞行器 (MIRV) 技术的本土研制的烈火-5 导弹的首次飞行试验。” Raksha Mantri Shri Rajnath Singh 也向科学家和整个团队表示祝贺,称这是一次非凡的成功。'
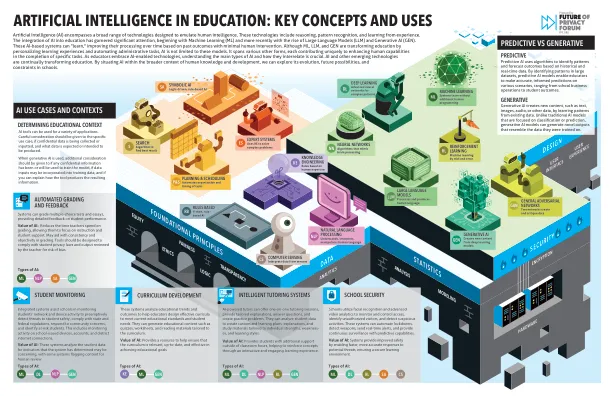
教育中的人工智能
人工智能(AI)涵盖了旨在模仿人类智能的广泛技术。这些技术包括推理,模式识别和从经验中学习。将人工智能融入教育已经引起了人们的显着关注,从机器学习(ML)开始,而最近,大型语言模型(LLM)和Generative AI(Gen)的兴起。这些基于AI的系统可以“学习”,根据过去的人类干预的过去结果,改善了它们的处理。尽管ML,LLM和Gen正在通过个性化学习经验和自动化行政任务来改变教育,但AI不仅限于这些模型。它涵盖了各种其他形式,每种形式都有贡献在特定任务完成中增强人类能力的独特作用。随着教育工作者采用AI支持的技术,了解AI的主要类型以及它们如何相互关键是至关重要的。AI和其他新兴技术正在不断改变教育。通过将AI置于人类知识和发展的更广泛背景下,我们可以探索其进化,未来的可能性和学校的约束。

美国空军部 CFETP 3F3X1 总部 美国空军第一部分和第二部分 华盛顿特区 20330-1030 2024 年 5 月 30 日
2.2.第二部分提供记录任务完成情况所需的信息。A 部分确定了专业培训标准 (STS),包括职责、任务、支持培训的技术参考、空中教育和训练司令部 (AETC) 进行的培训、战时课程和核心任务以及函授课程要求。B 部分包含课程目标列表和培训标准,主管将使用它们来确定飞行员是否满足培训要求。C 部分确定了可用的支持材料。D 部分确定了培训课程索引,主管可以使用该索引来确定可用于支持培训的资源。此处包括必修和选修课程。E 部分确定了 MAJCOM 独特的培训要求,主管可以使用这些要求来确定相关资格需求所需的额外培训。F 部分确定了支持应急和战时培训所需的驻地培训参考和该专业所需的课程材料。在单位层面,主管和培训师将使用第二部分来确定、规划和开展与本计划总体目标相称的培训。

能源感知的多代理增强学习,用于以任务为导向的无人机网络进行协作执行
摘要 - 面向以下的无人机网络已被广泛用于结构检查,灾难监测,边境监视等。由于无人机电池容量有限,任务执行策略会影响网络绩效和任务完成。但是,在如此动态的环境中,协作执行是无人机的一个问题问题,因为它也涉及有效的轨迹设计。我们利用多代理增强学习(MARL)来管理这项研究中的挑战,让每个无人机学会根据其当前状态和环境协作执行任务并计划轨迹。仿真结果表明,所提出的协作执行模型至少可以在80%的时间内成功完成任务,无论任务位置和长度如何,甚至在任务密度不太稀疏时甚至可以达到100%的成功率。据我们所知,我们的工作是利用MARL为以任务为导向的无人机网络的协作执行的开拓者研究之一;这项工作的独特价值在于无人机电池水平推动了我们的型号设计。索引术语 - 面向以下的无人机网络,协作执行,多代理增强学习,深Q-network

人工智能(AI)的使用与工商管理专业学生学业成绩之间的关系
人工智能以其数据解释、学习和任务完成能力而闻名,由于效率和质量的提高,在各个行业和学院中越来越受欢迎。本研究旨在确定学生使用人工智能的程度,包括功能性、可用性、复杂性、评估分数、课程掌握和评分指标。它还试图确定人工智能的使用与他们的学业成绩之间是否存在关系。该研究采用相关设计的定量方法。该研究的受访者是来自杜马格特市内格罗斯东方州立大学主校区 1 的 293 名工商管理专业学生。研究结果表明,学生使用人工智能在功能性、可用性和复杂性方面相当普遍。然而,学生的学业成绩高于平均水平,在评估、课程掌握和成绩方面得分较高。没有发现人工智能的使用和学业成绩之间有显著的关系。总之,人工智能工具提供个性化的学习体验、即时反馈和协作活动,但需要进一步发展和改进,包括培训、可访问性、研究、监控和最佳实践分享。

开放世界交互式个性化机器人导航
摘要 - 零击对象导航(ZSON)使代理能够在未知环境中朝着开放式摄制对象导航。ZSON的现有作品主要集中于遵循单个说明,以查找通用对象类,忽略了自然语言互动的利用以及识别特定用户特定对象的复杂性。为了解决这些限制,我们引入了零击交互式个性化对象导航(Zipon),在与用户进行对话时,机器人需要导航到个性化目标对象。要解决Zipon,我们提出了一个新的框架,称为开放世界交互式个性化导航(Orion)1,该框架使用大型语言模型(LLMS)来做出顺序决策,以操纵不同的模块以进行感知,导航和交流。实验结果表明,可以利用用户反馈的交互式剂的性能会显示出显着改善。但是,对于所有方法,在任务完成与导航和互动效率之间获得良好的平衡仍然具有挑战性。我们进一步提供了更多有关不同用户反馈表对代理商绩效的影响的发现。

人工智能 (AI) 的使用与工商管理专业学生学业成绩之间的关系 Jaysone Christopher M. Bancor
摘要 - 人工智能以其数据解释、学习和任务完成能力而闻名,由于效率和质量的提高,在各个行业和学院中都广受欢迎。本研究旨在确定学生使用人工智能的程度,包括功能、可用性、复杂性、评估分数、课程掌握和评分指标。它还试图确定人工智能的使用与他们的学业成绩之间是否存在关系。该研究采用相关设计的定量方法。该研究的受访者是来自杜马格特市内格罗斯东方州立大学主校区 1 的 293 名工商管理专业学生。研究结果表明,学生在功能、可用性和复杂性方面对人工智能的使用较为普遍。然而,学生的学业成绩高于平均水平,在评估、课程掌握和优异成绩方面得分较高。没有发现人工智能的使用与学业成绩之间有显著的关系。总之,人工智能工具提供个性化的学习体验、即时反馈和协作活动,但需要进一步发展和改进,包括培训、可访问性、研究、监控和最佳实践共享

奖励重要的事情:逐步加强了以任务为导向的对话
强化学习(RL)是增强面向任务对话(TOD)系统的强大方法。然而,现有的RL方法倾向于主要集中于生成任务,例如对话策略学习(DPL)或反应生成(RG),同时忽略了Dia-Logue State Tracking(DST)进行理解。这个狭窄的焦点限制了系统通过忽视理解与发电之间的相互依赖性来实现全球最佳性能。此外,RL方法面临稀疏和延迟奖励的挑战,这使训练和优化变得复杂。为了解决这些问题,我们通过在整个代币生成中逐步介绍逐步奖励,将RL扩展到理解和生成任务中。随着DST正确填充更多的插槽,理解会增加,而一代奖励则随着用户请求的准确包含而增长。我们的方法提供了与任务完成一致的平衡优化。实验性恢复表明,我们的方法有效地增强了TOD系统的性能,并在三个广泛使用的数据集上获得了新的最新结果,包括Multiwoz2.0,Multiwoz2.1和CAR。与当前模型相比,我们的方法在低资源设置中还显示出优越的射击能力。