XiaoMi-AI文件搜索系统
World File Search System决策树

EEG SINYALLERINIPEMEKIEMEKIEMAKINEÖğenimininImininKullanıldığıKonular
糖尿病是一种终身疾病,对各种器官(例如长期器官损伤,功能障碍以及最终的器官失败)具有不良影响。糖尿病必须在医生的监督下进行治疗。糖尿病被称为当今许多人可以看到的疾病,并且由于生活条件而变得广泛。如果患有糖尿病患者在早期没有接受任何治疗,则患者的身体会因严重的并发症而反应。除了诊断糖尿病的医学方法外,该疾病还可以通过人工智能方法检测到。这项研究旨在在引起糖尿病的许多变量中建立最具影响力的变量,并设计一种模型,该模型将预测糖尿病,以帮助医生使用选定的机器学习方法分析该疾病。在这项研究中,将决策树,决策树包装,随机森林和额外的树算法用于拟议的模型,并使用99.2%的额外树算法获得了最高的精度值。

深度学习简介(11-785/ 685/485) div>
- 常见算法:线性回归,决策树,支持向量机(SVM),K-Nearest邻居(K-NN)。- 深度学习是机器学习的一个子集,它使用具有多个层(深神经网络)的神经网络来对大型数据集中的复杂模式进行建模。

电子
摘要:电子,认知计算和传感的大规模现代技术革命为当今物联网(IoT)的开发提供了关键的基础架构,以用于广泛的应用。但是,由于端点设备的计算,存储和通信功能有限,因此物联网基础架构暴露于广泛的网络攻击中。因此,darknet或黑洞(污水坑)攻击很大,并且最近针对多种物联网通信服务发射的攻击向量。由于DarkNet地址空间是作为保留的Internet地址空间演变而来的,在全球合法的主机上不考虑使用,因此任何通信运输IC都被推测为未经请求的,并且独特地认为是探测器,反向散射或错误概括。因此,在本文中,我们在物联网网络中开发,调查和评估基于机器学习的DarkNet流量检测系统(DTD)的性能。主要是,我们使用六种监督的机器学习技术,包括行李决策树的合奏(BAG-DT),ADABOOST决策树共制(ADA-DT),RUSBOOSTED决策树组合(RUS-DT),可优化的决策树(O-DT),可优化的k-nearest k-nearest Inloes noest(O-nearest ofignize k-nearest nearp-egrigheat(o-o-knn)和Optim optig optig optim difcs和optigs ivciminant(Outigizigriminant(O-DSC))和DSC。我们在最近且全面的数据集上评估了已实施的DTD模型,称为CIC-Darknet-2020数据集,该数据集由当代实际的实际IoT通信流量组成,其中涉及四个差异类别,这些类别在一个数据集中结合了VPN和Tor Trapl IC,其中涵盖了涵盖广泛捕获的Cyber-Attacts和Deampersshide Serpect Service的单个数据集。我们的经验绩效分析表明,与其他实施的监督学习技术相比,Bagging集成技术(BAG-DT)更高的准确性和更低的错误率,得分为99.50%的分类精度,低推断开销为9.09 µ秒。最后,我们还与其他现有的DTDS型号进行了对比,并证明我们的最佳结果比以前的最新模型改善了(1.9〜27%)。

网络在人工智能与深度...中的应用
给定输入数据(表示为由其特征响应定义的 d 维空间中的点的集合(在此示例中为 2D),通过将整个训练集发送到树中并优化分割节点的参数来优化所选的能量函数,从而训练决策树。

利用算法预测糖尿病病情
糖尿病是一种全球患病率迅速上升的慢性疾病,影响着约4.22亿人,主要集中在中低收入国家。有效的糖尿病管理需要早期发现和及时干预。本研究旨在使用三种机器学习算法(随机森林、逻辑回归和决策树)开发糖尿病的精准预测模型。皮马印第安人糖尿病数据集包含 768 份包含各种健康指标的患者记录,用于模型训练和评估。探索性数据分析显示血糖水平、BMI、年龄和糖尿病风险之间存在显著相关性。数据集分为80%的训练数据(614个数据)和20%的测试数据(154个数据)。使用最小-最大缩放器方法对数据进行标准化,以确保所有特征都在同一尺度上。该模型使用交叉验证方法进行验证,并根据准确率、精确率、召回率和 F1 分数进行评估。结果显示,Logistic回归的准确率最高(75%),在识别正面和负面情况方面表现均衡。决策树在召回率方面表现出色,而随机森林在精确度和召回率之间的平衡略低。 ROC曲线分析显示,随机森林的AUC最高(0.82),其次是逻辑回归(0.81),决策树(0.73)。该研究证实,机器学习算法可以有效预测糖尿病,为早期发现和干预提供宝贵的工具,最终可能减轻全球糖尿病负担。

NETANTICIPATE:终极网络 AI 平台
支持的 ML 算法包括:1. 监督/分类 - AdaBoost、卷积神经网络 (CNN)、决策树、广义线性模型 (GLM)、K-最近邻 (KNN)、逻辑回归、多层感知器 (MLP)、朴素贝叶斯、随机森林、循环神经网络 (RNN)、支持向量回归 (SVM)、XGBoost。2. 监督/回归 - AdaBoost、卷积神经网络 (CNN)、决策树、广义线性模型 (GLM)、K-最近邻 (KNN)、线性回归、多层感知器 (MLP)、朴素贝叶斯、随机森林、循环神经网络 (RNN)、支持向量回归 (SVM)、XGBoost。 3. 时间序列/预测 - 自回归综合移动平均线 (ARIMA)、长短期记忆 (LSTM)、Prophet、Seq2Seq、时间卷积网络 (TCN)、NBeats、Autoformer、TCMF。4. 时间序列/异常 - 自动编码器、DBSCAN、椭圆包络、孤立森林、K-Means、一类 SVM。

脑肿瘤检测:深度综合研究...
对于其他机器学习模型,朴素贝叶斯的准确率达到 68.62%,而 SVM(支持向量机)的准确率达到 60.78%。同样,决策树模型的准确率也达到 68.62%。另一种集成技术 Bagging 的准确率达到 66.66%。有趣的是,结合预训练的 VGG-16 和 InceptionV3 模型的混合模型的准确率达到 68.92%。结果表明,卷积神经网络 (CNN) 是最成功的方法,在 MRI 扫描中实现脑肿瘤检测的最高准确率(86.27%)。这表明 CNN 特别擅长学习隐藏在 MRI 图像数据中的关键模式。关键词:磁共振成像 (MRI)、深度学习、卷积神经网络 (CNN)、多层感知器 (MLP)、迁移学习、InceptionV3、特征提取、主成分分析 (PCA)、准确度、VGG16、逻辑回归、随机森林、Ada Boosting、朴素贝叶斯、SVM、决策树、Bagging
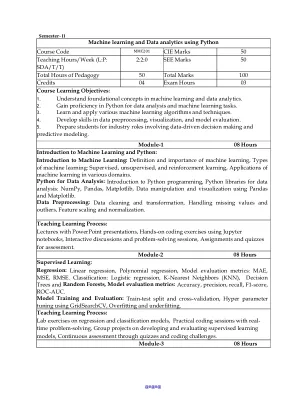
机器人学学期的管理经济学V
2对于一个给定的培训数据示例存储在.csv文件中,并实现并演示候选算法算法输出与培训示例一致的所有假设集的描述。3编写一个程序,以演示基于决策树的ID3算法的工作。使用适当的数据集来构建决策树并应用此知识来对新样本进行分类。4编写一个程序,以实现幼稚的贝叶斯分类器,以将存储为.csv文件存储的示例培训数据集。考虑了很少的测试数据集,计算分类器的准确性。5编写一个程序来实现k-nearest邻居算法以对虹膜数据集进行分类。打印正确与错误的预测。6通过实现反向传播算法并使用适当的数据集测试相同的人工神经网络。7编写一个程序,以在给定数据集上使用残差图演示回归分析。

使用机器学习算法用于银行贷款...
摘要背景:银行贷款预测是银行业的重要问题。通过使用历史数据并应用预测模型,银行可以识别模式并对贷款违约做出准确的预测。这可以帮助他们做出有关贷款的明智决定,并最大程度地减少损失。目标:研究影响贷款并使用机器学习算法方法预测银行贷款的重要参数:CRISP-DM过程是一种用于开发预测模型的全面且结构化的方法。通过遵循此过程,该研究可以确保采取所有必要的步骤来开发个人贷款的准确和可靠的预测模型。使用三种机器学习算法,例如决策树,幼稚的贝叶斯和支持向量机可以为开发模型提供,并使研究能够选择最佳。结果:结果表明,J48决策树算法达到了98.85%的最高精度,其次是SVM算法,精度为94.01%,而天真的贝叶斯算法的精度为89.53%。在精确,召回和F量表方面,所有三种算法都达到了相似的性能,值范围从0.895到0.989。结论:预测银行贷款的不同机器学习算法的性能表明,根据其高准确性,平均绝对错误和快速培训时间,J48 DT是开发银行贷款预测指标的最合适算法。关键字:银行贷款,Smote,幼稚的贝叶斯,支持向量机,决策树为了提高模型的准确性和适用性,可能有必要收集其他数据或完善特征选择过程以识别最相关的属性。

使用
摘要研究研究了三种分类算法,即使用来自Kaggle的数据集对糖尿病的分类进行分类,以分类糖尿病。k-nn使用欧几里得距离公式依靠测试和训练数据之间的距离计算。K的选择,代表最近的邻居,显着影响K-NN的有效性。天真的贝叶斯是一种概率方法,可以根据过去事件预测类概率,并采用高斯分布方法进行连续数据。决策树,以易于实现的规则形成预测模型。数据收集涉及获取具有八个属性的糖尿病的糖尿病数据集。数据预处理包括清洁和归一化,以最大程度地减少不一致和数据不完整的数据。使用RapidMiner工具应用了分类算法,并比较结果的准确性。天真的贝叶斯产生77.34%的精度,K-NN的性能取决于所选的K值,而决策树生成了分类规则。该研究提供了对糖尿病分类每种算法的优势和缺点的见解。关键字:分类算法,决策树,糖尿病,k-nearest邻居,幼稚的贝叶斯1。引言技术的发展和持续的时间发展对人类生活方式产生了重大影响,人类的生活方式正在迅速从传统变为现代。这些改变还带来了疾病出现模式的改变,尤其是与个人生活方式相关的疾病[1]。一种不健康的生活方式有助于肥胖,高血压,冠心病和糖尿病等疾病的发展。糖尿病,通常称为糖尿病,是一种长期代谢疾病,其血糖水平高于正常水平[2]。高糖水平是由于人体无法将食物加工成能量而引起的[1]。