XiaoMi-AI文件搜索系统
World File Search System决策树

通过对机器学习模型的比较分析改善心血管疾病预测:
摘要:心血管疾病仍然是当代世界中死亡率的主要原因。它与吸烟,血压升高和胆固醇水平的关联强调了这些危险因素的重要性。本研究解决了预测心肌疾病的挑战,这是医学研究中的一项艰巨任务。准确的预测是精炼医疗策略的关键。这项调查对六个不同的机器学习模型进行了比较分析:逻辑回归,支持向量机,决策树,包装,XGBoost和LightGBM。所达到的结果表现出希望,准确率如下:逻辑回归(81.00%),支持向量机(75.01%),XGBoost(92.72%),LightGBM(90.60%)(90.60%),决策树(82.30%)和装袋(83.01%)。值得注意的是,XGBoost作为表现最佳模型出现。这些发现强调了其增强冠状动脉梗塞预测精度的潜力。随着心血管危险因素的普遍性持续存在,结合了先进的机器学习技术,具有优化积极主动的医疗干预措施的潜力。

糖尿病的机器学习和平衡技术...
此外,一些研究应用了集合技术来改善结果。参考[6]进行了几种ML算法的比较:逻辑回归,线性判别分析,k-neart邻居,决策树,支持向量机,Adaboost分类器,梯度增强分类器,随机森林分类器,随机森林分类器和额外的树分类器。使用PIMA印度糖尿病数据集和早期糖尿病风险预测数据集评估了这些算法。与两个数据集中的其他机器学习算法相比,整体机器学习算法提供了更好的分类精度。在其他研究[7]中,使用了决策树,SVM,随机森林,逻辑回归,KNN和各种集合技术。该研究采用了PIMA印度糖尿病数据集和203名来自孟加拉国的女性患者的样本。此外,采用了Smote和Adasyn方法来解决阶级不平衡问题。XGBoost分类器与Adasyn方法结合使用,得出的结果最佳,获得了81%的精度,F1系数为0.81,AUC为0.84。
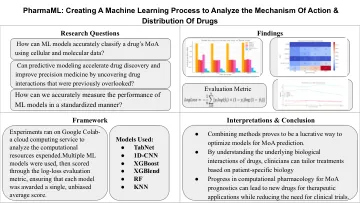
PharmAML:创建一个机器学习过程来分析动作机理&
●随机森林:一种合奏学习算法,该算法构建了多个决策树并结合了输出以提高准确性并减少过度效果。●XGBoost:像随机森林一样,XGBoost是一种集合学习算法,但它使用梯度提升来依次构建决策树,在每个步骤上纠正错误,以提高准确性和效率。●KNN:一种基于实例的学习算法,该算法基于其K最近的K最近邻居的多数类或通过平均值来预测值。●XGBlend:我们创建的XGBoost模型!将标准神经网络与XGBoost体系结构相结合,以提高算法处理的速度。●1D-CNN:使用卷积层将每一行视为1D序列的卷积神经网络,以捕获特征相互作用并提取图案,以提高预测性能。●TABNET:专为表格数据而设计的深度学习模型,利用注意机制动态选择相关特征,从而实现可解释性和有效的学习。

纳米流体导热率和粘度的预测
众所周知,纳米流体在其热和转移特性方面与传统传热液显着不同。CO 2传输特性的两个,其导热率和粘度对于改善油的检索方法和工业制冷至关重要。通过将分子模型与各种机器学习算法相结合,本研究预测了氧化铁CO 2纳米流体的传导特征。可以通过应用机器学习方法,例如决策树,k-neareast邻居和线性回归来评估这些传输参数估计值的准确性。预测这些转移质量需要知道纳米颗粒体积的大小,比例和温度的比例。为了确定特征,分子动力学模拟是使用大尺度原子进行的。建立了一个间和vari内部功能的皮尔逊相关性,以确认输入变量依赖于M和导热率。最终使用确定的统计系数确认了结果。对于各种温度范围,体积分数和纳米颗粒尺寸,该研究发现,决策树模型是预测纳米流体传输参数的最佳方法。它的成功率为99%。关键词:导热率,粘度,机器学习,纳米流体,

将决策工具应用于生物多样性保护中的道德分析
摘要实现道德负责的决定对于生物多样性公会项目的成功至关重要。我们通过构造这些工具来调整道德矩阵,决策树和贝特森的立方体,以协助对复杂的保护方案进行道德分析,以便它们可以实施参与保护道德的不同价值维度(环境,社会和动物)。然后,我们将它们应用于案例研究中,相对于决策过程,关于是否继续在两个剩下的北部白犀牛(Ceratotherium simum cottoni)中,是否继续收集生物材料,这是白色犀牛的功能灭绝的亚种。我们使用道德矩阵来收集道德利弊,并作为参与式决策方法的起点。我们使用决策树来比较一套道德义务的不同选项。我们使用Bateson的立方体建立了道德可接受性的阈值,并模拟了简单调查的结果。这些工具的应用被证明是构建决策过程以及帮助从可用的那些人的道德角度来实现最佳选择的共同,合理和透明决策的关键。

12 个人工智能技术术语对于这个时代的商业人士
当我们谈论人工智能和机器学习算法时,我们谈论的是过程和我们小学学数学的时候一样。但情况更复杂。例如,谷歌使用了一种算法(基于规则的过程)为了决定哪些网站显示在搜索结果页面的顶部,机器学习技术使用不同类型的算法来得出结果。最佳结果常用算法的例子包括决策树、分类算法、回归算法等。
![arxiv:2401.12759v2 [Math.oc] 2024年3月6日](/simg/b\b8bf9ec950844c52e783609f299361a2a2ab0d15.webp)
arxiv:2401.12759v2 [Math.oc] 2024年3月6日
图1。集成设计和调度问题的结构:问题结构允许优化当地发电和存储系统的设计,同时考虑同时进行DA和ID市场参与和流程DR。决策树对决策的时间顺序序列进行了建模。每个分支表示不确定参数的实现,每个节点代表一个决策点。
![arxiv:2503.04137V1 [CS.LG] 2025年3月6日 div>](/simg/4\4c3f55801d995e756b2d4cc9371cda01b66db8e1.webp)
arxiv:2503.04137V1 [CS.LG] 2025年3月6日 div>
糖尿病是一种普遍存在的慢性疾病,全世界具有重大的健康和经济负担。早期的预测和诊断可以帮助有效地管理和预防并发症。本研究探讨了使用机器学习模型根据生活方式因素进行基于生活方式因素预测糖尿病的使用,该数据使用行为风险面对面监视系统(BRFSS)2015调查的数据。数据集由21种生活方式和与健康相关的特征组成,包括体育锻炼,饮食,心理健康和社会经济状况等方面。实施并评估了三种分类模型 - 决策树,K-Nearest邻居(KNN)和逻辑回归 - 以确定其预测性能。使用平衡的数据集对模型进行了训练和测试,并根据准确性,精度,召回和F1得分对其性能进行评估。结果表明,决策树,KNN和逻辑回归的精度分别为74%,72%和75%,在精确和召回方面具有不同的优势。这些发现突出了糖尿病预测中机器学习的潜力,并通过特征选择和合奏学习技术提出了改进。

糖尿病预测的机器学习技术
糖尿病以慢性高血糖为特征,由于其相关并发症和发病率提高而提出了重大挑战。本研究研究了一系列机器学习算法,例如幼稚的贝叶斯,决策树,逻辑回归,随机森林,神经网络,支持向量机,LogitBoost和投票分类器,以开发糖尿病的准确预测模型。这项研究中使用的数据是从Mendeley.com上可用的全面数据集中获取的,该数据集来自伊拉克医疗城医院实验室。该研究的重点是特征选择和评估指标,以有效衡量模型性能。采用并比较了八种分类技术,包括决策树(DT),随机森林(RF)和LogitBoost。该研究的发现突出显示了DT和RF作为表现最佳的算法,表现出可比的预测能力,LogitBoost也显示出令人鼓舞的结果。相反,支持向量机(SVM)由于对异常值的敏感性而显示出降低的性能。这些见解使医疗保健从业人员能够采用适当的机器学习方法来改善糖尿病预测,从而及时进行干预并增强患者的结果。