XiaoMi-AI文件搜索系统
World File Search System分类器

使用随机森林分类器对癫痫发作类型进行分类
癫痫是一种因脑部异常电活动而出现的病理状况 [1]。它是影响全球约 6500 万人(占世界人口的 1%)的重要问题之一 [2]。在阿拉伯国家,癫痫的发病率估计为每 100,000 人中有 174 人。在沙特阿拉伯王国,癫痫的患病率为每 1,000 人中有 6.54 人 [3]。然而,三分之一的癫痫患者无法获得医疗服务。他们必须找到生活和管理日常生活的方法。即使癫痫患者可以获得医疗服务,医疗质量也达不到标准 [4]。癫痫患者的诊断和治疗取决于癫痫发作的类型 [4]。脑电图 (EEG) 记录是神经科医生用来分析脑电波功能异常的技术之一。多年来,它被广泛用于诊断脑部疾病,例如

使用 DEAP 进行 SVM 分类器特征提取的 DWT 与 PSD 性能比较
信号由在不同情况下组合的多个频率组成。离散小波变换 (DWT) 用于使用一系列高通/低通滤波器将信号分解为不同的频带。或者,使用功率谱密度 (PSD) 来获取频谱以及每个频率的功率分布。统计特征来自 DWT 和 PSD。然后,PCA 用于降维,并且在 SVM 分类器的情况下仅将得到的数据用于情绪分类,因为我们需要尽可能多的数据来进行深度学习。所有这些都是为了从分类器中提取最大性能并最小化所需的计算资源,然后将信号分解为组成频率并得出表征整个信号的相关统计特征。

4CAC:使用机器学习和装配图的元基因组重叠群的4类分类器
抽象的微生物群落通常具有细菌,古细菌,质粒,病毒和微核生素的混合物。在相对的含量丰度中,Y等人与细菌进行了复杂的相互作用。Moreo Ver,病毒和质粒作为移动遗传元素,在水平基因转移和微生物种群中抗生素耐药性中起着重要作用。由于难以识别微生物群落中的病毒,质粒和微核生素,因此我们对这些次要类别落后于细菌和古细菌的差异。resse,将分类器被用来分开,将一个或多个次要类别与元基因组组件中的细菌和古细菌分开。ho w e v er,这些分类器通常是阶级不平衡问题,从而导致识别次要类别的精确度较低。在这里,我们开发了一个称为4CAC的分类器,能够从元素组组件中同时识别病毒,质粒,微核细胞和原核生物。4CAC使用se v er序列长度调整后的XGB OOST模型生成了初始的F我们的分类,并使用汇编图进一步对分类进行了分类。对所采用和真实的元基因组数据集进行的表明,在简短读取中,4CAC显然优于现有的分类器及其组合。 长期读取,除非少数类的丰度为very lo w,否则它也会显示出优势。 4CAC的运行速度比其他分类器快1-2个数量级。表明,在简短读取中,4CAC显然优于现有的分类器及其组合。长期读取,除非少数类的丰度为very lo w,否则它也会显示出优势。4CAC的运行速度比其他分类器快1-2个数量级。4CAC软件可从https://github.com/ shamir-lab/ 4cac获得。

使用T2 MRI脑图像和CNN二元分类器和DWT
摘要:目的:放射线学家使用磁共振成像(MRI)数据对脑肿瘤进行了手动和无创诊断和非侵入性分类。可能由于人为因素(例如缺乏时间,疲劳和相对较低的经验)而存在误诊的风险。深度学习方法在MRI分类中变得越来越重要。为提高诊断准确性,研究人员强调需要通过使用深度学习方法(例如卷积神经网络(CNN))来开发基于人工智能(AI)系统的计算机辅助诊断(CAD)计算诊断,并通过将其与其他数据分析工具(如波动型波现变换)相结合来改善CNN的性能。在这项研究中,开发了一个基于CNN和DWT数据分析的新型诊断框架,用于诊断大脑中的神经胶质瘤肿瘤以及其他肿瘤和其他疾病,并进行了T2-SWI MRI扫描。这是一种二元CNN分类,将“神经胶质瘤肿瘤”视为阳性,而其他病理为阴性,导致非常不平衡的二元问题。该研究包括对经过MRI的小波变换数据而不是其像素强度值的CNN进行比较分析,以证明CNN和DWT分析在诊断脑胶质瘤时的性能提高。还将提出的CNN体系结构的结果与使用DWT知识的VGG16传输学习网络和SVM机器学习方法进行了比较。此外,没有对原始图像应用预处理。使用的图像是与轴向平面平行的T2-SWI序列的MRI。方法:为了提高CNN分类器的准确性,拟议的CNN模型用作知识,通过将原始MRI图像转换为频域而提取的空间和时间特征,通过执行离散小波转换(DWT),而不是传统上使用的原始扫描以Pixel Intomesition的形式进行。首先,对每次MRI扫描进行了一个压缩步骤,该DWT施加了三个级别的分解级别。这些数据用于训练2D CNN,以将扫描分类为显示神经胶质瘤。拟议的CNN模型对MRI切片进行了培训,该模型源自382名各种男性和女性成年患者,显示出疾病选择的健康和病理图像(显示出神经胶质瘤,脑膜瘤,垂体,垂体,坏死,水肿,非onsence肿瘤,肿瘤,出血性焦点,水肿,缺血性,缺血性区域等)。这些图像由医学图像计算和计算机辅助干预(MICCAI)的数据库以及缺血性的中风病变细分(ISLE)对脑肿瘤细分(BRATS)挑战2016和2017的挑战以及2017年和2017年的挑战,以及在Chania,Crete,Crete,Crete,Crete,Crete,Crete,Saint George中保存的许多记录。结果:通过检查源自190名不同患者的MRI切片(未包含在训练集中),在实验中评估了所提出的框架,其中56%的胶质瘤显示了最长的两个轴小于2 cm,而44%的轴是其他病理效应或健康的病例。结果表明,当使用AS信息时,令人信服的性能是原始扫描提取的空间和时间特征。使用拟议的CNN模型和DWT格式的数据,我们实现了以下

通过环境意识的关系分类器进行多对象操作的潜在空间计划
摘要 - 对象很少在日常的人类环境中孤立地坐着。如果我们希望机器人在人类环境中操作和执行任务,他们必须了解他们操纵的对象将如何与最简单的任务相互作用。因此,我们希望我们的机器人推理多个对象和环境元素如何相互关系,以及这些关系在机器人与世界互动时可能会发生变化。我们研究了以前看不见的对象和新颖的环境之间纯粹来自部分视图点云之间预测目标间和对象环境关系的问题。我们的方法使机器人能够计划和执行序列,以完成由逻辑关系定义的多对象操纵任务。这消除了提供明确的,连续的对象作为机器人目标的负担。我们为此任务探索了几种不同的神经网络体系结构。我们发现最佳性能模型是一个基于新颖的变压器神经网络,既可以预测对象环境关系,又可以学习潜在空间动力学功能。我们实现了可靠的SIM转移传输,而无需进行任何微调。我们的实验表明,我们的模型了解观察到的环境几何形状的变化如何与对象之间的语义关系有关。我们在网站上显示更多视频:https://sites.google.com/view/erelationaldynamics。

脑电图中与性别相关的模式及其在机器学习分类器中的相关性
图1用迷你尖端卷积神经网络和相关归因方法进行性检测。首先,xðÞ节X段是交叉相关的吗?ðÞ,有16个学识渊博的时空内核(K I)的维度与脑电图的短窗口相似(图2中描述的实际核)。由于内核具有与数据相同数量的通道,因此它们仅沿时间轴而不是跨通道滑动。16个相关曲线被整流(Relu激活),并分为40个重叠的窗口。接下来,平均将窗户的最大值(M ij)进行。在最后一层中,从这16个平均值中预测了性别yðÞ。事后,网络参数用于归因于每个eeg通道和录音中的时间点的相关性r(紫色中指示的路径)。最终分类器层的重量(W I)的符号表示与第一层( /emale /Red and + / + /男性 /蓝色)的每个内核相对应的性别。

机器学习分类器在前颅底病变鉴别中的应用
前颅底有多种病变。该区域最常见的肿瘤类型是垂体腺瘤、颅咽管瘤和脑膜瘤(1、2)。Rathke 裂囊肿也是与先天性鞍区肿块鉴别诊断的常见方法(3)。早期诊断该区域病变的重要性已得到强调,因为即使是这些良性病变,如果位于无法控制生长的区域,也可能呈进行性、持续性发展,有些病变还可能表现出侵袭性(4)。磁共振(MR)扫描具有良好的软组织分辨率,因此被强烈推荐用于前颅底病变的术前评估。磁共振成像(MRI)对这四种类型病变的描述具有特征性(5)。然而,MRI 图像的诊断准确性取决于放射科医生的经验,在某些情况下,具有相似 MRI 模式的病变可能彼此相似并使放射学诊断复杂化(6,7)。因此,有助于术前鉴别的新方法可能具有临床价值。放射组学可以从医学图像中提取高维特征,提供与病变病理生理相关的信息,而这些信息难以通过肉眼检查获得(8-10)。此外,可以利用新型机器学习技术分析病变的可挖掘放射组学特征,该技术在生物医学领域显示出良好的应用前景(11)。基于放射组学的机器学习已在先前的研究中应用于各种脑肿瘤的鉴别诊断,代表着在临床实践中应用于促进诊断和指导决策的潜力(12-16)。本研究评估了机器学习技术结合MRI影像组学特征和临床参数对前颅底四种常见病变的鉴别诊断能力。根据病变的流行病学和部位,将鉴别诊断分为三组:垂体腺瘤与颅咽管瘤(鞍区/鞍上区最常见的肿瘤)、脑膜瘤与颅咽管瘤(鞍旁区最常见的肿瘤)以及垂体腺瘤与Rathke裂囊肿(鞍内区最常见的病变)。
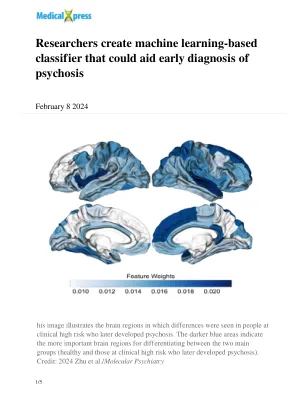
研究人员创建基于机器学习的分类器,可帮助早期诊断精神病
在训练中,该工具对结果进行分类的准确率为 85%,而在使用新数据的最终测试中,该工具对哪些参与者患精神病的风险较高进行预测的准确率为 73%。根据结果,该团队认为,为被确定为临床高风险的人提供脑部 MRI 扫描可能有助于预测未来精神病的发病率。

基于机器学习分类器的光伏阵列中的电故障分析和检测
摘要:由于其固有的优势,例如零污染,灵活性,可持续性和高可靠性,太阳能光伏发电引起了重大的兴趣。确保PV功率设施的有效运行在精确的故障检测中取决于。这不仅可以增强其可靠性和安全性,而且还可以优化利润并避免昂贵的维护。但是,使用通用保护设备的PV系统直流电(DC)侧的故障检测和分类带来了重大挑战。这项研究深入研究了对光伏(PV)阵列中复杂断层的探索和分析,尤其是那些表现出类似I-V曲线的阵列,这是PV故障诊断的重大挑战,在先前的研究中未充分解决。本文探讨了支持向量机(SVM)和极端梯度提升(XGBoost)的设计和实施,重点是它们有效地识别小型PV阵列中各种故障状态的能力。这项研究扩大了将优化算法的使用,特别是蜜蜂算法(BA)和粒子群优化(PSO),目的是提高基本SVM和XGBoost分类器的性能。优化过程涉及完善机器学习模型的超参数,以实现故障分类的卓越精度。发现蜜蜂算法的弹性和效率的有说服力的案例。使用用于优化SVM和XGBOOST分类器以检测PV阵列中的复杂故障时,蜜蜂算法显示出显着的精度。相比之下,使用PSO算法进行细调的分类器表现出相对较低的性能。这些发现强调了蜜蜂算法在光伏系统中故障检测中提高分类器准确性的潜力。

噪声数据集的二元分类器:现有量子机器学习框架和一些新方法的比较研究
量子机器学习是最有希望获得实际优势的研究领域之一,它是量子计算和传统机器学习思想相互影响的产物。在本文中,我们应用量子机器学习 (QML) 框架来改进金融数据集中普遍存在的噪声数据集的二元分类模型。我们用来评估量子分类器性能的指标是受试者工作特征曲线下面积 (ROC/AUC)。通过结合混合神经网络、参数电路和数据重新上传等方法,我们创建了受 QML 启发的架构,并利用它们对非凸二维和三维图形进行分类。对我们的新 FULL HYBRID 分类器与现有量子和经典分类器模型进行广泛的基准测试表明,与已知的量子分类器相比,我们的新模型对数据集中的非对称高斯噪声表现出更好的学习特性,并且对于现有的经典分类器表现同样出色,并且在高噪声区域内比经典结果略有改善。