XiaoMi-AI文件搜索系统
World File Search System可重复性

使用... 评估科学发现的深度可重复性
科学论文的可重复性测试表明,大多数论文都无法重复。此外,失败的论文在文献中的传播速度与可重复的论文一样快。这种动态削弱了文献,增加了研究成本,并表明需要新的方法来评估研究的可重复性。在这里,我们训练了一个人工智能模型,使用通过或未通过手动复制测试的研究的基本事实数据来评估论文的可重复性,然后在大量样本外研究中测试该模型的普遍性。该模型对可重复性的预测优于审稿人的基本比率,并且与预测市场相当,这是当今预测可重复性的最佳方法。在对来自不同学科和方法的手动复制论文进行样本外测试时,该模型的准确率高达 0.65 到 0.78。探索模型预测背后的原因,我们发现没有证据表明存在基于主题、期刊、学科、基准失败率、说服性词语或“非凡”或“出乎意料”等新颖词语的偏见。我们确实发现,当对论文文本而不是其报告的统计数据进行训练时,该模型的准确率更高,并且 n-gram(人类难以处理的高阶词组合)与复制相关。我们讨论如何将人类和机器智能结合起来,提高研究信心,提供研究自我评估技术,并创建可扩展且高效的方法来审查不断增长的出版物数量——这项任务需要大量人力资源,仅靠预测市场和手动复制才能完成。


优化中的可重复性:理论框架和局限性
除了机器学习模型的实际部署之外,机器学习学术界的可重复性危机也得到了充分的记录:请参阅 [ Pineau 等人,2021 ] 及其参考文献,其中对不可重复性的原因(对超参数和实验设置的探索不足、缺乏足够的文档、代码无法访问以及不同的计算硬件)进行了出色的讨论,并提出了缓解建议。最近的论文 [ Chen 等人,2020 、D'Amour 等人,2020 、Dusenberry 等人,2020 、Snapp 和 Shamir,2021 、Summers 和 Dinneen,2021 、Yu 等人,2021 ] 还证明,即使在相同的数据集上使用相同的优化算法、架构和超参数训练模型,它们也会对同一个示例产生明显不同的预测。这种不可重复性可能是由多种因素造成的 [D'Amour 等人,2020 年,Fort 等人,2020 年,Frankle 等人,2020 年,Shallue 等人,2018 年,Snapp 和 Shamir,2021 年,Summers 和 Dinneen,2021 年],例如目标的非凸性、随机初始化、训练中的不确定性(例如数据混洗)、并行性、随机调度、使用的硬件和舍入量化误差。也许令人惊讶的是,即使我们通过使用相同的“种子”进行模型初始化来控制随机性,其他因素(例如由于现代 GPU 的不确定性而引入的数值误差)(参见,例如,[ Zhuang et al. , 2021 ])仍可能导致显着差异。经验表明(参见,例如,Achille et al. [ 2017 ])

遗传质量:实验研究可重复性的一个复杂问题。
在过去的 15 年中,科学界逐渐意识到已发表的研究普遍缺乏可重复性,尤其是动物研究。据估计,36% 的临床前研究成本花在了不可重复的实验上,原因是所用试剂和材料(包括动物)的错误(Freedman 等人,2015 年)。科学文献中报道的研究资源(包括模型生物,例如转基因小鼠品系)通常缺乏关键细节,因此研究无法重复(Percie du Sert 等人,2020 年)。再加上动物研究向临床研究的可转移性非常低(Leenaars 等人,2019 年),这些问题令人担忧,需要予以解决,以改进药物研究,并且出于明显的道德原因。造成这种情况的原因有多种,例如:缺乏统计功效分析、实验设计不佳、所用动物的健康状况等。本文将重点讨论小鼠的遗传质量。在使用疾病动物模型时,科学家需要考虑一系列因素

深度学习可重复性和可解释人工智能 (XAI)
本文借助图像分类示例研究了深度学习 (DL) 训练算法的不确定性及其对神经网络 (NN) 模型可解释性的影响。为了讨论这个问题,我们训练了两个卷积神经网络 (CNN) 并比较了它们的结果。比较有助于探索在实践中创建确定性、稳健的 DL 模型和确定性可解释人工智能 (XAI) 的可行性。本文详细描述了所有努力的成功和局限性。本文列出了所获得的确定性模型的源代码。可重复性被列为模型治理框架的开发阶段组成部分,该框架由欧盟在其 AI 卓越方法中提出。此外,可重复性是建立因果关系以解释模型结果和建立信任以应对 AI 系统应用的迅猛扩展的必要条件。本文研究了在实现可重复性的过程中必须解决的问题以及处理其中一些问题的方法。

PET/MRI:SUV 测量的可靠性/可重复性
SUV 指标在临床中被广泛使用,因为它简单、易用、可重复,并且与传统的全身 PET/CT 采集协议兼容,只需要静态扫描,而全动力学建模方法则需要复杂的动态研究和动脉血样采集。几乎所有商业和开源医学图像显示软件平台都提供测量 SUV 的选项。然而,定量成像生物标志物联盟倡议的 PET 技术委员会最近进行的一项研究表明,临床和研究环境中使用的不同软件包之间存在相当大的不一致性 [ 4 ]。还应注意,大多数软件包将 SUV 标准化为患者的体重(等式( 6.1 ))。然而,由于脂肪组织的代谢活性不如其他组织,因此提出了其他变体,包括标准化为瘦体重(SUV LBM 或 SUL)[ 5 ] 或体表面积(SUV BSA )[ 6 ]。最大SUV(SUV max )代表最高体素SUV值,平均SUV(SUV mean )代表定义的VOI中所有体素的平均SUV,无疑是最广泛使用的半定量指标(图6.1 )。相反,SUV峰值(图6.1 )在PERCIST标准中定义为代表SUV平均值

提高研究的可重复性:测量科学的作用
摘要:• 我们报告了 2018 年 5 月 1 日至 3 日在英国泰丁顿国家物理实验室举行的研讨会,该研讨会的重点是世界各国计量机构如何帮助解决研究可重复性的挑战。• 研讨会汇集了物理科学、数据分析、生命科学、工程和地质科学领域的测量和更广泛研究界的专家。研讨会共有来自计量实验室 (38)、学术界 (16)、工业界 (5)、资助机构 (2) 和出版商 (2) 的 63 名参与者。参与者来自英国、美国、韩国、法国、德国、澳大利亚、波斯尼亚和黑塞哥维那、加拿大、土耳其和新加坡。• 主题探讨了良好的测量实践和原则如何增强对研究结果的信心以及如何应对工业和研究领域数据量增加的挑战。

提高研究的可重复性:测量科学的作用
摘要:• 我们报告了 2018 年 5 月 1 日至 3 日在英国泰丁顿国家物理实验室举行的研讨会,该研讨会的重点是世界各国计量机构如何帮助解决研究可重复性的挑战。• 研讨会汇集了物理科学、数据分析、生命科学、工程和地质科学领域的测量和更广泛研究社区的专家。研讨会共有来自计量实验室 (38)、学术界 (16)、工业界 (5)、资助机构 (2) 和出版商 (2) 的 63 名参与者。参与者来自英国、美国、韩国、法国、德国、澳大利亚、波斯尼亚和黑塞哥维那、加拿大、土耳其和新加坡。• 主题探讨了良好的测量实践和原则如何增强对研究结果的信心,以及如何应对工业和研究领域数据量增加的挑战。
提高研究的可重复性:测量科学的作用
摘要:• 我们报告了 2018 年 5 月 1 日至 3 日在英国泰丁顿国家物理实验室举行的研讨会,该研讨会的重点是世界各国计量机构如何帮助解决研究可重复性的挑战。• 研讨会汇集了物理科学、数据分析、生命科学、工程和地质科学领域的测量和更广泛研究社区的专家。研讨会共有来自计量实验室 (38)、学术界 (16)、工业界 (5)、资助机构 (2) 和出版商 (2) 的 63 名参与者。参与者来自英国、美国、韩国、法国、德国、澳大利亚、波斯尼亚和黑塞哥维那、加拿大、土耳其和新加坡。• 主题探讨了良好的测量实践和原则如何增强对研究结果的信心,以及如何应对工业和研究领域数据量增加的挑战。
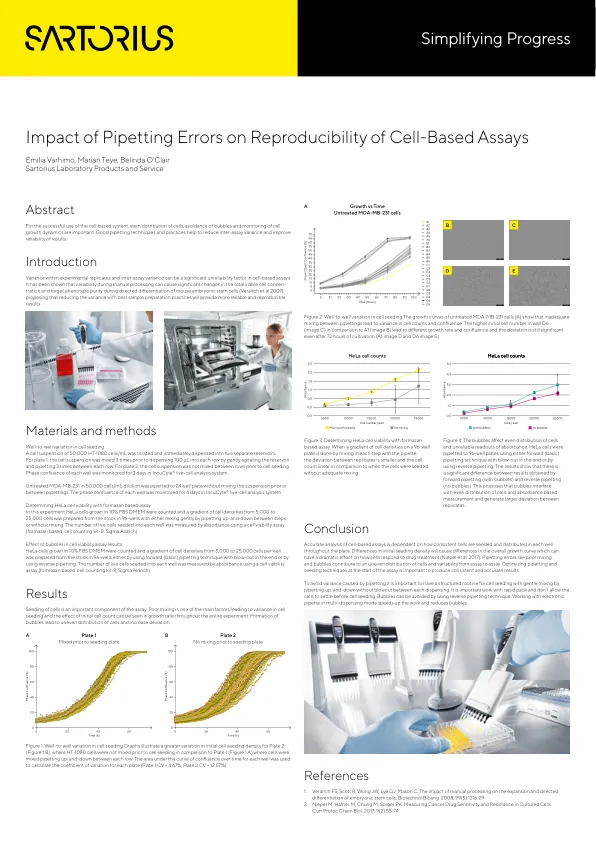
移民错误对基于细胞测定的可重复性的影响
对基于细胞的测定的准确分析取决于整个板中每个孔中播种和分布的一致性细胞。初始播种密度的差异将导致整体生长曲线的差异,这可能会对细胞对药物治疗的反应产生巨大影响(Niepel等人。2017)。诸如混合差和气泡之类的移移误差会导致细胞分布和从测定之间的变异性不均匀。在测定开始时优化移液和播种技术对于产生一致和准确的结果很重要。