XiaoMi-AI文件搜索系统
World File Search System回归模型

CAP4631C数据分析的机器学习i
课程描述CAP4631C |数据分析的机器学习| 4.00学分,该上限课程适用于专业的数据分析学生。学生将了解为什么机器学习对于数据分析至关重要,以及为什么回归分析是监督机器学习的基础。使用Python编程,学生将使用各种软件包来创建进行预测的回归模型。先决条件:COP1047C; STA3164或CAP3330

增强供应链弹性:一种用于预测产品可用日期的机器学习方法
COVID-19的大流行和正在进行的政治和地区冲突对全球供应链产生了极大的有害影响,从而导致物流运营和国际运输造成重大延误。最紧迫的问题之一是围绕产品可用性日期的不确定性,这对于公司生成有效的物流和运输计划的关键信息。因此,准确预测可用性日期在执行成功的物流运营中起着关键作用,最终最大程度地减少了总运输和库存成本。我们利用数值和分类功能研究了通用电动(GE)气体功率的产品可用性日期的预测日期。我们评估了几种回归模型,包括简单回归,拉索回归,脊回归,弹性网,随机森林(RF),梯度增强机(GBM)和神经网络模型。基于实际数据,我们的实验表明,基于树的算法(即RF和GBM)提供了最佳的概括误差,并且优于测试的所有其他回归模型。我们预计,我们的预测模型将帮助公司管理供应链中断并降低供应链的风险。

HER2 阳性/激素受体的 HER2DX 基因组测试
结果 参与 PerELISA 的 55 名患者(86.0%)接受了 HER2DX 评估,其中 40 名患者(73.0%)患有 ESD。ESD 患者的 pCR 率为 22.5% (9/40)。在该组中,HER2DX pCR 评分和 HER2DX ERBB2 mRNA 评分与 pCR 显着相关(p = 0.008 和 p = 0.003,单变量逻辑回归模型;ROC 下面积 [AUC] = 0.803 和 0.896)。低、中、高 HER2DX pCR 评分组的 pCR 率分别为 7.7% (2/26)、46.2% (6/13) 和 100.0% (1/1)。 HER2DX ERBB2 低、中、高评分组的 pCR 率分别为 0.0% (0/12)、7.7% (1/13) 和 53.3% (8/15)。HER2DX pCR 评分也与来曲唑 2 周治疗后的 Ki-67 反应显着相关(p = 0.002,单变量逻辑回归模型;AUC = 0.775)。HER2DX pCR 低、中、高评分组的 ESD 率分别为 89.7% (26/29)、65.0% (13/20) 和 16.7% (1/6)。
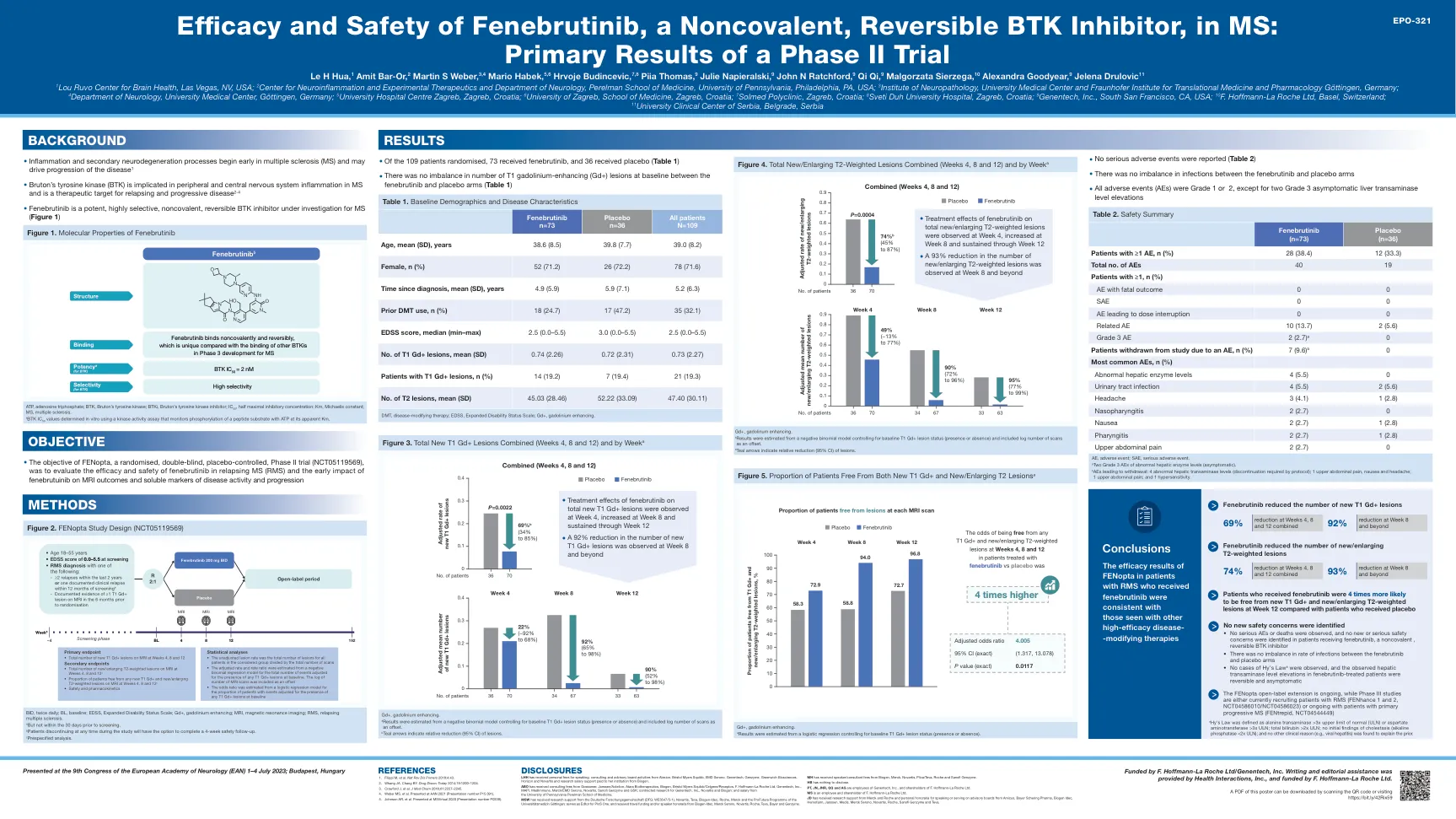
fenebrutinib的功效和安全性,一种非可逆的,可逆的BTK抑制剂,在MS中:2期试验的主要结果
统计分析•未经调整的病变率是被考虑组中所有患者的病变总数除以扫描总数•调整后的速率和速率比估计了从负二项式回归模型的负二项式回归模型的总数,该事件的总数在基线时的任何T1 GD+病变的存在调整了。 将MRI扫描数量的日志作为偏移•从逻辑回归模型中估计的优势比,用于针对基线时存在任何T1 GD+病变的事件的患者比例。统计分析•未经调整的病变率是被考虑组中所有患者的病变总数除以扫描总数•调整后的速率和速率比估计了从负二项式回归模型的负二项式回归模型的总数,该事件的总数在基线时的任何T1 GD+病变的存在调整了。将MRI扫描数量的日志作为偏移•从逻辑回归模型中估计的优势比,用于针对基线时存在任何T1 GD+病变的事件的患者比例

通过深入的强化学习来鉴定SARS-COV-2 MPRO抑制剂,用于新的药物设计和计算化学方法
给定带有测量活性标记的DNA序列的数据集(图1a),我们用一系列分类令牌(“提示令牌”)编码标签,该标签的前缀为DNA序列的开始(图1b)。我们训练或微调鬣狗模型以采用处理的序列并以及时令牌开始执行令牌预测(图。1C)。这种形式使我们能够明确地使用对模型序列的任何先验知识。一旦受过训练,就可以使用代表任何所需功能的令牌序列来提示语言模型。该模型现在以及时令牌为条件,一次生成一个DNA序列一个核苷酸(图1d)。并行,我们在同一数据集上训练一个监督的序列到活动回归模型(图1E),并将其应用于生成的序列以选择最匹配所需活动的序列(图1F)。这种合并的方法使我们可以将回归模型用作甲骨文,例如以前的模型引导的方法,而语言模型可确保生成的序列具有现实的内容。

使用机器学习对房价的预测
MEERUT工程技术研究所CSE部,Meerut 250001,印度摘要:本研究调查了机器学习技术的应用,特别是随机森林算法以及对住房价格的预测分析。 利用一个包含各种住房属性的全面数据集,研究重点是预处理步骤,包括数据清洁,归一化和功能工程以增强模型性能。 回归模型,包括线性回归,脊回归和拉索回归以及随机森林算法,使用严格的交叉验证技术对培训和评估,以确保稳健性和准确性。 “这些评估措施,包括预测和实际值之间平均方差的平方差异的平方根,以及预测和实际值之间的绝对差异的平均值,用于全面的性能评估。”。分析表明,随机森林算法表明,在较高的准确性和弹性中,可以在更高的准确性和互补的情况下进行复杂的相关性,从而使不合格的相关性均优于传统的回归模型。 这些发现强调了利用机器学习的重要性,尤其是随机森林方法,在有效预测住房价格方面,为房地产领域中的利益相关者提供了宝贵的见解,以实现知情的决策过程。MEERUT工程技术研究所CSE部,Meerut 250001,印度摘要:本研究调查了机器学习技术的应用,特别是随机森林算法以及对住房价格的预测分析。利用一个包含各种住房属性的全面数据集,研究重点是预处理步骤,包括数据清洁,归一化和功能工程以增强模型性能。回归模型,包括线性回归,脊回归和拉索回归以及随机森林算法,使用严格的交叉验证技术对培训和评估,以确保稳健性和准确性。“这些评估措施,包括预测和实际值之间平均方差的平方差异的平方根,以及预测和实际值之间的绝对差异的平均值,用于全面的性能评估。”。分析表明,随机森林算法表明,在较高的准确性和弹性中,可以在更高的准确性和互补的情况下进行复杂的相关性,从而使不合格的相关性均优于传统的回归模型。这些发现强调了利用机器学习的重要性,尤其是随机森林方法,在有效预测住房价格方面,为房地产领域中的利益相关者提供了宝贵的见解,以实现知情的决策过程。


少数民族的迷幻回报减少:心脏 - ...
摘要尽管对迷幻药以改善心理和身体健康的保护因素的支持越来越多,但这些影响在种族和族裔群体中可能有所不同。种族差异仍然是迷幻电光的严重研究的差距。最近对少数民族的实证研究减少了迷幻的回报,这表明黑人美国人可能会从迷幻使用中获得很少的健康益处。这项研究测试了终生经典迷幻使用与心脏代谢健康的多个指标(包括心血管疾病,高血压和体重指数)之间的差异。该项目使用了全国药物使用与健康调查(NSDUH)(2005年至2019年)的黑白成年人受访者的汇总数据(n = 421,477)。该分析包括一系列逻辑和普通最小二音回归模型。结果表明,终生迷幻的使用与更好的心脏代谢健康有关。但是,种族的回归模型发现,LCPU和有氧代谢健康对黑人没有关联,而对白人的积极关联仍然很重要。总体而言,结果为MPDR理论提供支持。

reglm:使用自回归语言模型设计现实的监管DNA
给定带有测量活性标记的DNA序列的数据集(图1a),我们以一系列分类令牌(“提示令牌”)的序列编码标签,该标记已预先固定到DNA序列的开始(图1b)。我们训练或填充hyenadna模型以采用处理后的序列并以及时令牌开始执行令牌预测(图1C)。这种形式使我们能够明确地使用对模型序列的任何先验知识。一旦受过训练,就可以使用代表任何所需功能的令牌序列来提示语言模型。该模型现在以及时令牌为条件,一次生成一个DNA序列一个核苷酸(图1d)。并行,我们在同一数据集上训练一个监督的序列到活动回归模型(图1E),并将其应用于生成的序列以选择最匹配所需活动的序列(图1F)。这种合并的方法使我们可以将回归模型用作甲骨文,例如以前的模型引导的方法,而语言模型可确保生成的序列具有现实的内容。最后,我们提供了几种评估生成序列以及模型本身的方法(图1G)。

由数学与计算机系组织...
实现无信息搜索算法(BFS、DFS) 实现信息搜索算法(A*、内存受限 A*) 实现朴素贝叶斯模型 实现贝叶斯网络 构建回归模型 构建决策树和随机森林 构建 SVM 模型 实现集成技术 实现聚类算法 实现贝叶斯网络的 EM